

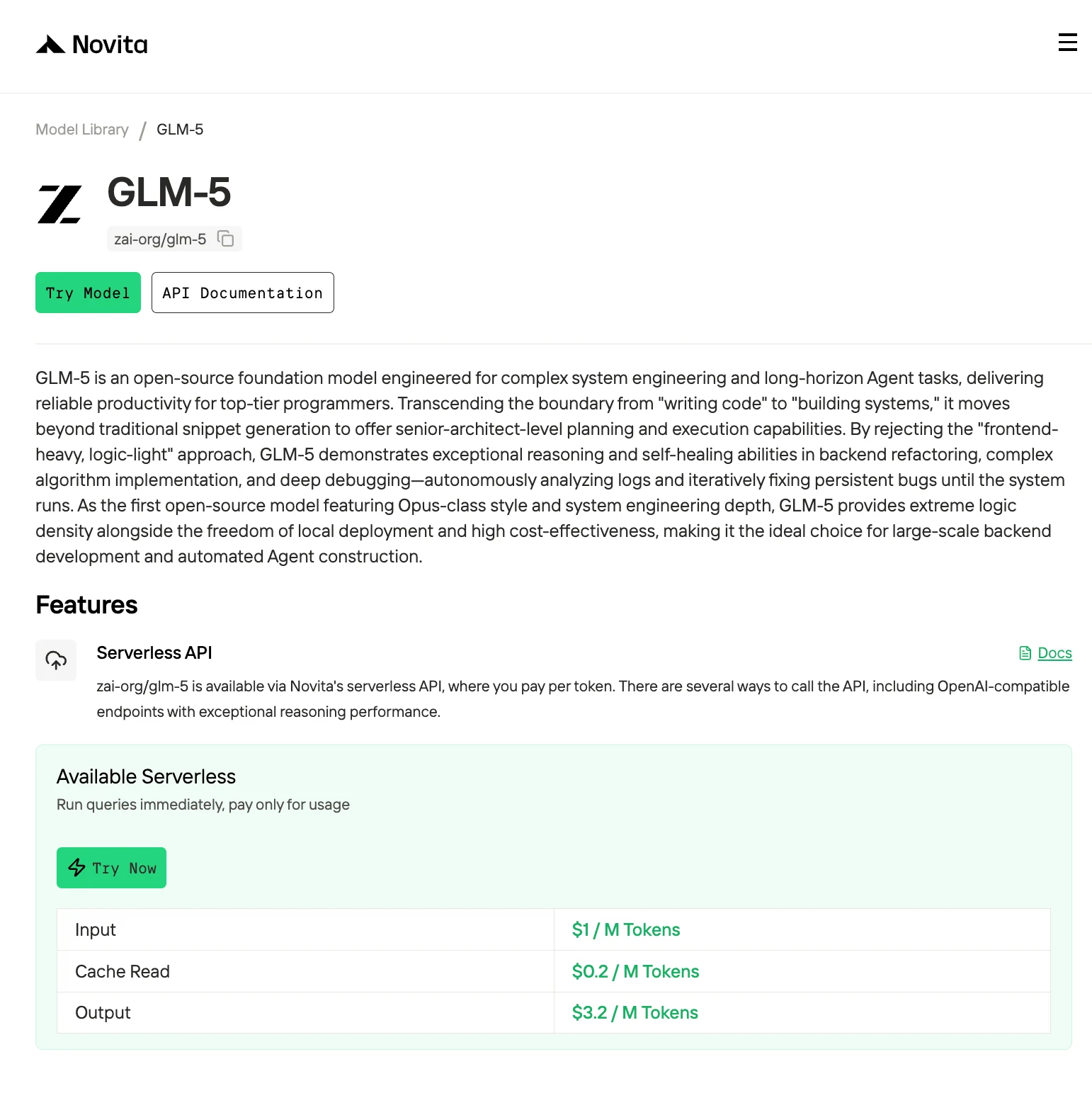
GLM-5, el modelo insignia más reciente de Z.AI, ha ampliado los límites de los modelos de lenguaje de código abierto con su masiva arquitectura de 754 mil millones de parámetros. Pero aquí está el problema: aunque ofrece un rendimiento de primer nivel en tareas de codificación, razonamiento y agentes, ejecutar GLM-5 localmente exige hardware de nivel empresarial que lo sitúa fuera del alcance de la mayoría de los desarrolladores.
Esta guía desglosa exactamente cuánta VRAM necesita GLM-5 en diferentes niveles de precisión, qué GPUs pueden manejarlo y las estrategias de despliegue realistas tanto para experimentación local como para cargas de trabajo de producción. También exploraremos por qué el tamaño de GLM-5 es importante para sus casos de uso previstos: ingeniería de sistemas complejos y flujos de trabajo agénticos de múltiples pasos.
Respuesta Rápida: Requisitos de VRAM de GLM-5
A diferencia de los modelos densos donde todos los parámetros se activan para cada token, GLM-5 utiliza una arquitectura Mixture-of-Experts (MoE) con:
- 754B parámetros totales distribuidos en múltiples redes de expertos
- 40B parámetros activos por paso de inferencia (solo ~5.4% de los parámetros totales activos)
- DeepSeek Sparse Attention (DSA) para procesamiento eficiente de contextos largos
- 28.5T tokens de datos de preentrenamiento (frente a los 23T de GLM-4.5)
| Nivel de Precisión | VRAM Mínima | Configuración de GPU |
|---|---|---|
| BF16 (Precisión Completa) | 1.51TB | 24× NVIDIA H100 80GB |
| FP8 | Aproximadamente 800GB | 8× NVIDIA H200 141GB |
| INT4 (Quantizaciones de la Comunidad) | 400GB+ | 8× NVIDIA H100 80GB |
Configuración recomendada: 8× H100 80GB con NVLink para INT4. Esto proporciona 640GB de VRAM total con interconexión de GPU de alto ancho de banda (900 GB/s por puente NVLink), esencial para el enrutamiento eficiente de parámetros en modelos MoE.
Hardware de Consumo: No es Realista
Seamos directos: GLM-5 no está diseñado para GPUs de consumo. Incluso si puedes cargar el modelo, la velocidad de inferencia será dolorosamente lenta sin NVLink. Las placas base de consumo carecen del ancho de banda entre GPUs necesario para un paralelismo de tensores eficiente.
Rendimiento de GLM-5: ¿Vale la Pena el Costo de VRAM?
GLM-5 tiene sentido cuando necesitas alta fiabilidad de ejecución y flujos de trabajo de herramientas de largo alcance, especialmente en entornos tipo Claude Code. La evidencia más sólida es que GLM-5 se comporta como un modelo de ejecución de ingeniería:
- 98% de Tasa de Éxito en la Construcción de Frontend
Esto sugiere firmemente que GLM-5 produce código que compila y se ejecuta, no solo código que “suena bien”.
También se desempeña extremadamente bien en benchmarks de agentes:
- BrowseComp con Gestión de Contexto: 75.9
- τ²-Bench: 89.7
- Conjunto Público MCP-Atlas: 67.8
Cuándo GLM-5 no vale la pena
Si tu trabajo es:
- scripts pequeños
- codificación de un solo archivo
- depuración de preguntas y respuestas cortas
- componentes web simples
- tareas de “generar fragmento de código”
Entonces la ventaja de ingeniería de contexto largo de GLM-5 no se activa, y estás pagando una gran VRAM para una ganancia mínima. En ese caso, modelos como Minimax M2.5 son mucho más rentables.
https://www.youtube.com/watch?v=3XCYruBYr-0
Opciones de Despliegue: Cloud vs Local
Opción 1: Proveedores de API (Más Fácil)
Para la mayoría de los desarrolladores, usar GLM-5 a través de API es la única opción práctica.
Conecta fácilmente Novita AI con plataformas asociadas como Claude Code, Trae, Continue, Codex, OpenCode,AnythingLLM,LangChain, Dify, Langflow, y OpenClaw a través de integraciones oficiales y guías de configuración paso a paso.
Opción 2: Alquiler de GPU en la Nube
Paso 1: Registra una cuenta
Crea tu cuenta de Novita AI a través de nuestro sitio web. Después del registro, navega a la sección “Explorar” en la barra lateral izquierda para ver nuestras ofertas de GPU y comenzar tu viaje de desarrollo de IA.

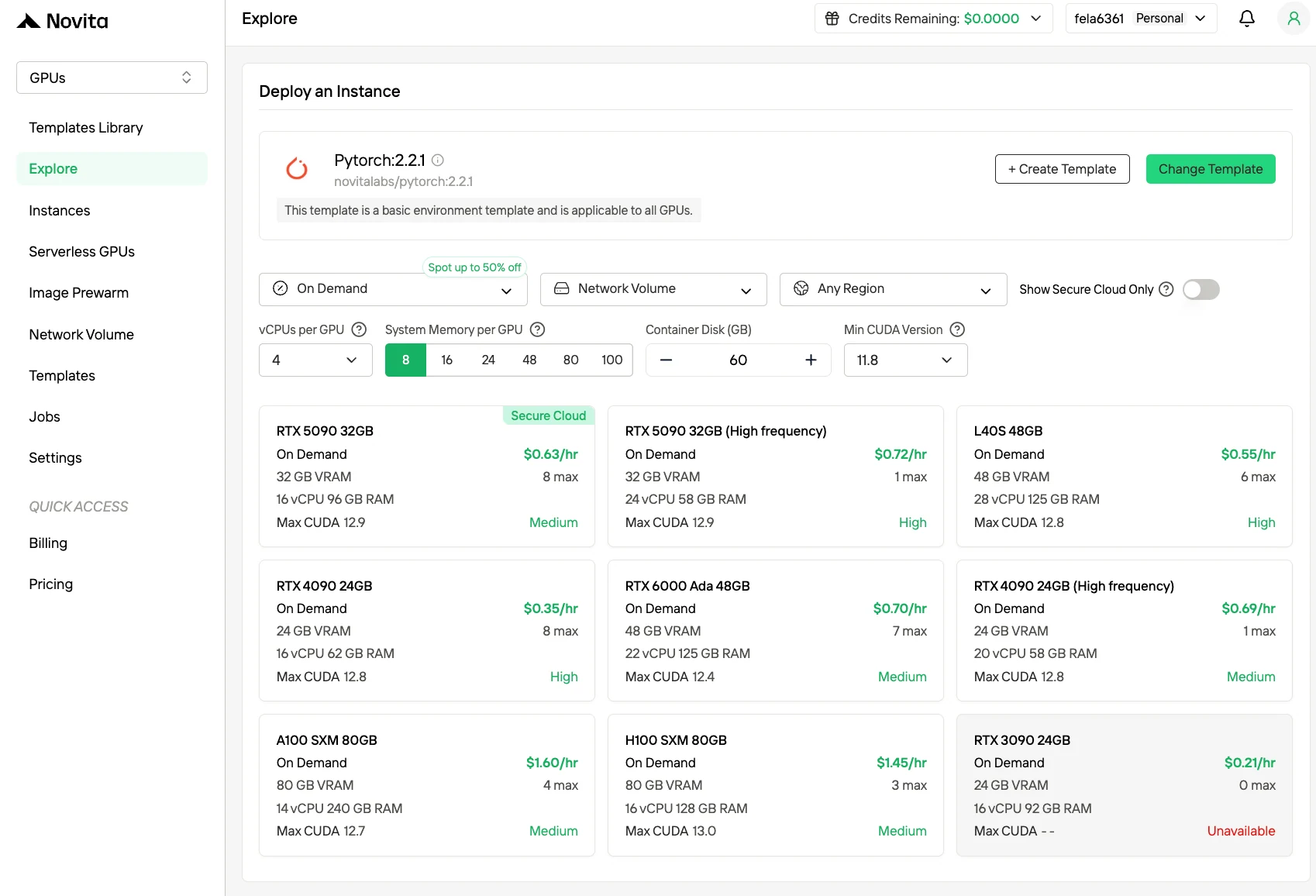
Paso 2: Explora Plantillas y Servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se adapten a las necesidades de tu proyecto. Luego selecciona tu configuración de GPU preferida: las opciones incluyen la potente H100, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.
Paso 3: Personaliza tu Despliegue
Personaliza tu entorno seleccionando tu sistema operativo y opciones de configuración preferidos para garantizar un rendimiento óptimo para tus cargas de trabajo de IA específicas y necesidades de desarrollo.
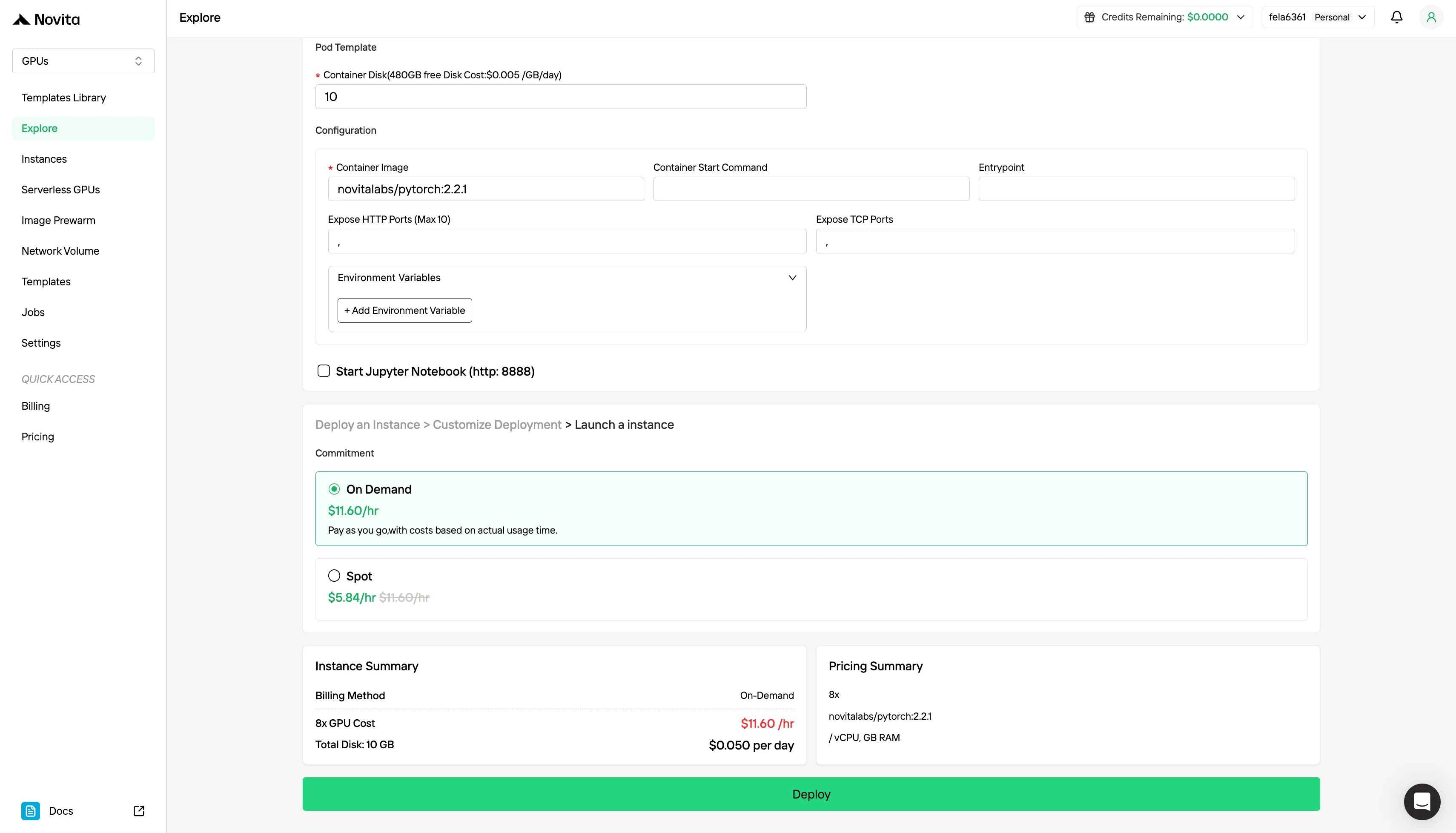
Además del modelo de precios estándar On-Demand, Novita AI también ofrece el modo Spot, una opción de GPU significativamente más barata diseñada para cargas de trabajo sensibles al costo.
El modo Spot de Novita AI es un sistema de alquiler de GPU optimizado en costo que aprovecha la capacidad de GPU inactiva o no utilizada de la plataforma. A diferencia de las instancias on-demand, que reservan hardware dedicado para un uso estable y continuo, las instancias Spot son interrumpibles —tu trabajo puede pausarse o terminarse si la GPU es reclamada por el sistema. Debido a que el modo Spot reasigna recursos GPU que de otro modo no se utilizarían, suele ser 40–60% más barato que el precio on-demand.
Opción 3: Despliegue Local (Solo Investigación)
Si tienes acceso a una estación de trabajo de gama alta o un clúster de laboratorio:
- Requisito de hardware: 8× H100/A100 para INT4
- Stack de software: vLLM 0.6+ o SGLang con soporte de paralelismo de tensores
- Almacenamiento: SSD NVMe de 2TB+ para pesos del modelo y carga rápida
- Memoria: RAM de sistema de 512GB+ para cargar checkpoints antes de la transferencia a GPU

GLM-5 representa una nueva clase de modelos de código abierto ultra grandes que amplían los límites de lo posible en IA agéntica, pero a un costo de hardware elevado. Con 754GB de VRAM requeridos incluso en INT4, GLM-5 está firmemente en territorio empresarial, necesitando 8+ GPUs de clase H100 para un despliegue viable. Para desarrolladores individuales y equipos pequeños, la ruta de la API a través de proveedores como Novita AI es la única opción práctica.
Preguntas Frecuentes
¿Puedo ejecutar GLM-5 en RTX 4090?
Ni hablar. Ocho GPUs H100 son la línea base.
¿Cuál es la diferencia entre las versiones GLM-5 BF16 y FP8?
Sorprendentemente, ambas son de ~754GB debido a la cuantización de precisión mixta en FP8. FP8 ofrece una pérdida de calidad mínima con una velocidad de inferencia ligeramente mejor en GPUs H100+.
¿Puedo afinar GLM-5 en hardware de consumo?
No. El afinamiento requiere 2-3 veces la VRAM de la inferencia (estados del optimizador, gradientes), lo que lo hace imposible.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una manera fácil de desplegar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona una GPU en la nube asequible y confiable para construir y escalar.
Lectura Recomendada



