

GLM-5، النموذج الرائد الأحدث من Z.AI، قد دفع حدود نماذج اللغات مفتوحة المصدر بفضل بنيته الضخمة المكونة من 754 مليار معامل. لكن هناك نقطة مهمة: على الرغم من أنه يقدم أداءً من الفئة الأولى في مهام البرمجة والاستدلال والمهام الوكيلية، فإن تشغيل GLM-5 محليًا يتطلب أجهزة من فئة المؤسسات، مما يجعله بعيدًا عن متناول معظم المطورين.
يشرح هذا الدليل بالضبط كمية ذاكرة الفيديو (VRAM) التي يحتاجها GLM-5 عبر مستويات دقة مختلفة، أي وحدات معالجة الرسوميات (GPUs) يمكنها التعامل معه، واستراتيجيات نشر واقعية لكل من التجارب المحلية وأحمال عمل الإنتاج. كما سنستكشف لماذا يهم حجم GLM-5 لحالات الاستخدام المخصصة له: هندسة الأنظمة المعقدة وسير العمل الوكيلية متعددة الخطوات.
إجابة سريعة: متطلبات ذاكرة الفيديو لـ GLM-5
على عكس النماذج الكثيفة التي تنشط جميع معاملاتها لكل رمز (token)، يستخدم GLM-5 بنية مختلطة الخبراء (MoE) مع:
- 754 مليار معامل إجمالي موزعة عبر شبكات خبراء متعددة
- 40 مليار معامل نشط في كل عملية استدلال (فقط ~5.4% من إجمالي المعاملات نشطة)
- انتباه Spars من DeepSeek (DSA) لمعالجة السياقات الطويلة بكفاءة
- 28.5 تريليون رمز (token) من بيانات التدريب المسبق (ارتفاعًا من 23 تريليون في GLM-4.5)
| مستوى الدقة | ذاكرة الفيديو الدنيا | تكوين وحدة معالجة الرسوميات |
|---|---|---|
| BF16 (الدقة الكاملة) | 1.51 تيرابايت | 24× NVIDIA H100 80GB |
| FP8 | حوالي 800 جيجابايت | 8× NVIDIA H200 141GB |
| INT4 (تكميم المجتمع) | 400 جيجابايت+ | 8× NVIDIA H100 80GB |
جرّب وحدات معالجة الرسوميات ذات التكلفة الفعالة!
التكوين الموصى به: 8× H100 80GB مع NVLink لـ INT4. يوفر هذا 640 جيجابايت إجمالي من ذاكرة الفيديو مع اتصال عالي النطاق بين وحدات معالجة الرسوميات (900 جيجابايت/ثانية لكل جسر NVLink)، وهو أمر ضروري لتوجيه المعاملات بكفاءة في نماذج MoE.
أجهزة المستهلكين: غير واقعي
لنكن صريحين: لم يتم تصميم GLM-5 لوحدات معالجة الرسوميات للمستهلكين. حتى إذا تمكنت من تثبيت النموذج، ستكون سرعة الاستدلال بطيئة للغاية بدون NVLink. تعاني لوحات الأم للمستهلكين من نقص في النطاق الترددي بين وحدات معالجة الرسوميات المطلوب للتطبيق المتوازي للمتجهات بكفاءة.
أداء GLM-5: هل تكلفة ذاكرة الفيديو تستحق العناء؟
يعد GLM-5 خيارًا منطقيًا عندما تحتاج إلى موثوقية تنفيذ عالية وسير عمل أدوات طويلة الأمد، خاصة داخل بيئات من نوع Claude Code. أقوى دليل على ذلك هو أن GLM-5 يتصرف كنموذج تنفيذ هندسي:
- معدل نجاح بناء الواجهات الأمامية 98%
يشير هذا بقوة إلى أن GLM-5 ينتج كودًا يمكن ترجمته وتشغيله، وليس مجرد كود “يبدو صحيحًا من الناحية النظرية”.
كما أنه يؤدي أداءً ممتازًا للغاية في معايير المهام الوكيلية:
- BrowseComp مع إدارة السياق: 75.9
- τ²-Bench: 89.7
- MCP-Atlas Public Set: 67.8
متى لا يستحق GLM-5 العناء
إذا كان عملك يتضمن:
- نصوص برمجية صغيرة
- برمجة ملف واحد
- تصحيح أخطاء أسئلة وأجوبة قصيرة
- مكونات ويب بسيطة
- مهام “توليد مقتطفات كود”
فإن ميزة GLM-5 الهندسية للسياقات الطويلة لا تنشط، وستدفع مبلغًا كبيرًا مقابل ذاكرة الفيديو مقابل مكاسب ضئيلة. في هذه الحالة، تعد نماذج مثل Minimax M2.5 أكثر فعالية من حيث التكلفة بكثير.
https://www.youtube.com/watch?v=3XCYruBYr-0
خيارات النشر: السحابة مقابل المحلي
الخيار 1: موفرو واجهة برمجة التطبيقات (الأسهل)
للمطورين في الغالب، استخدام GLM-5 عبر واجهة برمجة التطبيقات هو الخيار العملي الوحيد.
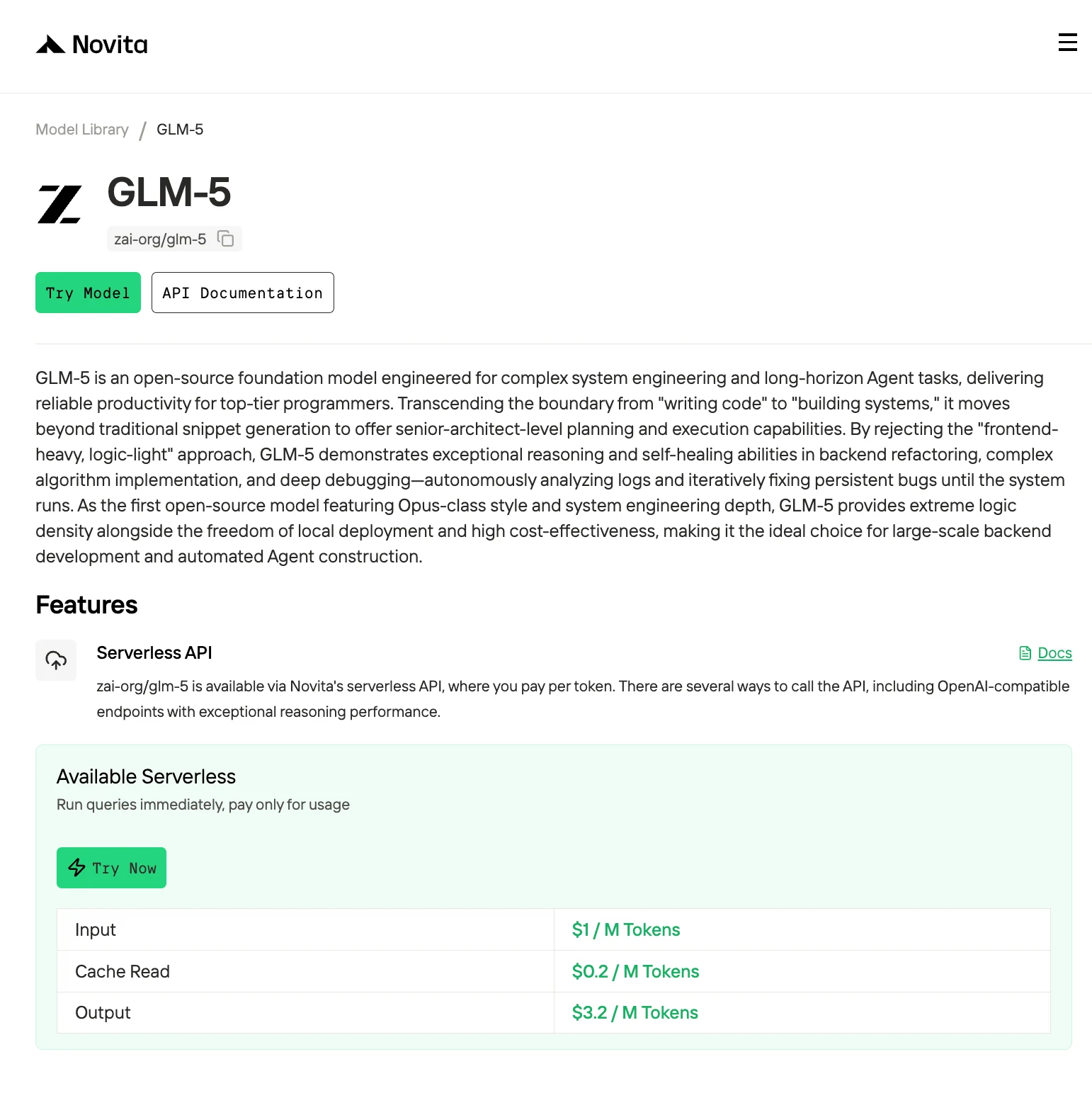
اتصل بسهولة بـ Novita AI مع منصات الشركاء مثل Claude Code، Trae، Continue، Codex، OpenCode،AnythingLLM،LangChain، Dify، Langflow، و OpenClaw عبر التكاملات الرسمية وأدلة الإعداد خطوة بخطوة.
الخيار 2: تأجير وحدات معالجة الرسوميات السحابية
الخطوة 1: تسجيل حساب
أنشئ حسابك في Novita AI عبر موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “استكشاف” في الشريط الجانبي الأيسر لعرض عروض وحدات معالجة الرسوميات لدينا وابدأ رحلة تطوير الذكاء الاصطناعي الخاصة بك.

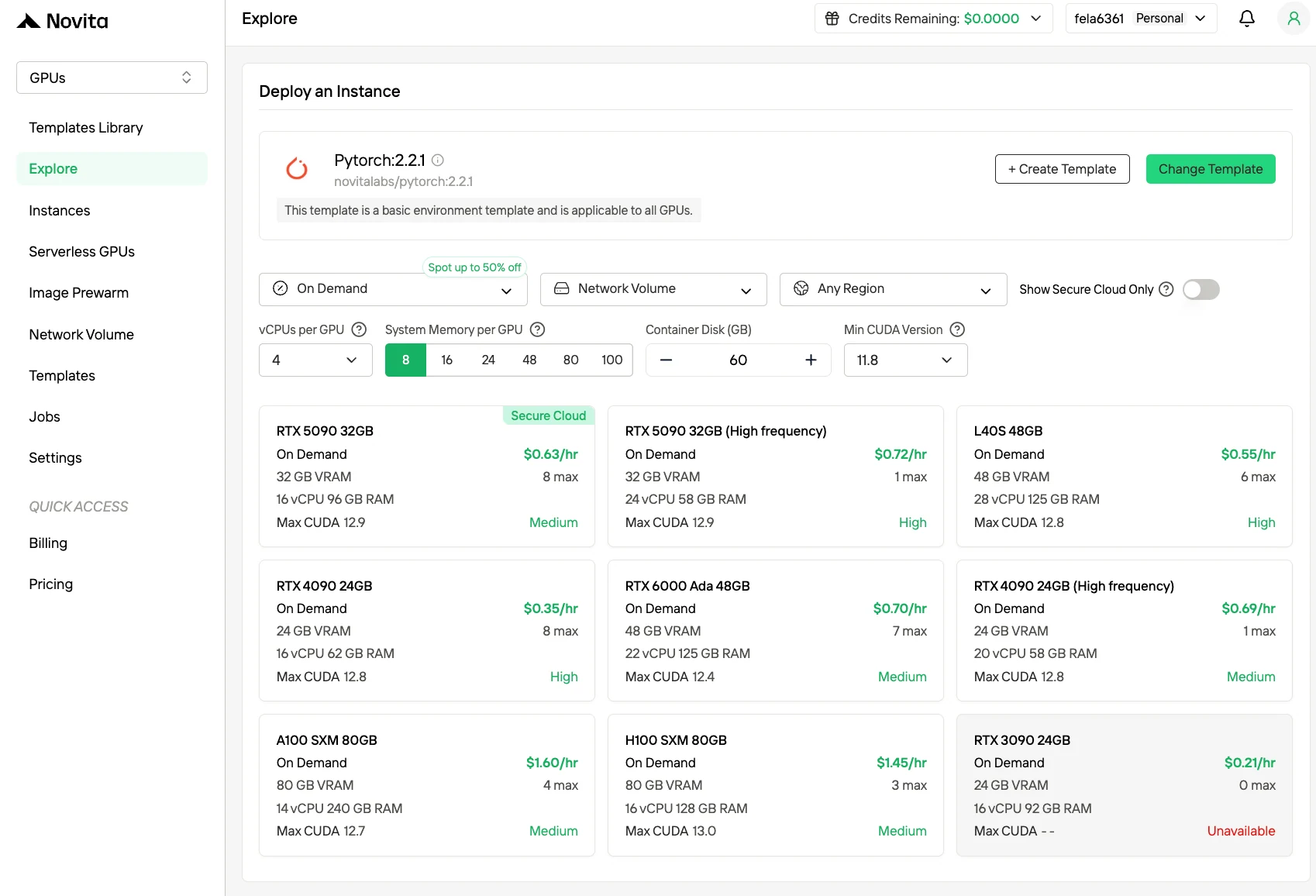
الخطوة 2: استكشاف القوالب وخوادم وحدات معالجة الرسوميات
اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تتوافق مع احتياجات مشروعك. ثم اختر تكوين وحدة معالجة الرسوميات المفضل لديك - تتضمن الخيارات H100 القوية، لكل منها مواصفات مختلفة لذاكرة الفيديو والذاكرة العشوائية والتخزين.
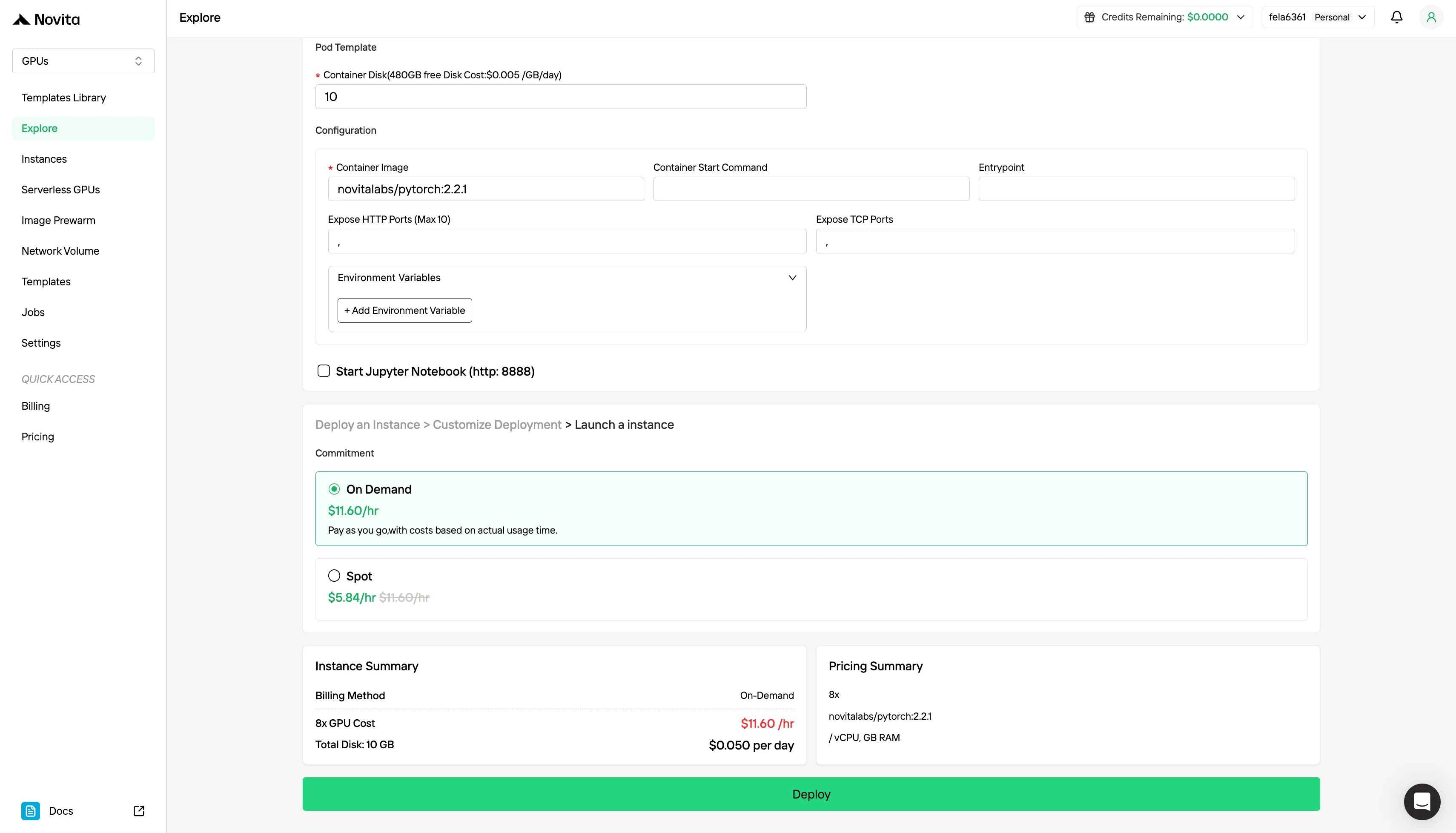
الخطوة 3: تخصيص النشر الخاص بك
خصص بيئتك عن طريق اختيار نظام التشغيل وخيارات التكوين المفضلة لديك لضمان الأداء الأمثل لأحمال عمل الذكاء الاصطناعي الخاصة بك واحتياجات التطوير.
جرّب وحدات معالجة الرسوميات ذات التكلفة الفعالة!
بالإضافة إلى نموذج التسعير القياسي عند الطلب، تقدم Novita AI أيضًا وضع النقاط، وهو خيار لوحدات معالجة الرسوميات أقل تكلفة بشكل كبير مصمم لأحمال العمل الحساسة للتكلفة.
وضع النقاط من Novita AI هو نظام تأجير لوحدات معالجة الرسوميات محسّن التكلفة يستخدم سعة وحدات معالجة الرسوميات الخاملة أو غير المستخدمة على المنصة. على عكس الحالات عند الطلب، التي تحجز أجهزة مخصصة للاستخدام المستقر والمستمر، فإن حالات النقاط قابلة للقطع - قد يتم إيقاف مهمتك أو إنهاؤها إذا استعاد النظام وحدة معالجة الرسوميات. وبما أن وضع النقاط يعيد تخصيص موارد وحدات معالجة الرسوميات غير المستخدمة، فهو عادة ما يكون أرخص بنسبة 40-60% من التسعير عند الطلب.
الخيار 3: النشر المحلي (للبحث فقط)
إذا كان لديك حق الوصول إلى محطة عمل عالية الأداء أو مجموعة مختبر:
- متطلبات الأجهزة: 8× H100/A100 لـ INT4
- مجموعة البرامج: vLLM 0.6+ أو SGLang مع دعم التطبيق المتوازي للمتجهات
- التخزين: قرص SSD NVMe سعة 2 تيرابايت أو أكثر لأوزان النموذج والتحميل السريع
- الذاكرة: ذاكرة عشوائية للنظام سعة 512 جيجابايت أو أكثر لتحميل نقاط التفتيش قبل النقل إلى وحدة معالجة الرسوميات

جرّب وحدات معالجة الرسوميات ذات التكلفة الفعالة!
يمثل GLM-5 فئة جديدة من النماذج مفتوحة المصدر فائقة الكبر التي تدفع حدود ما هو ممكن في الذكاء الاصطناعي الوكيل - ولكن بتكلفة أجهزة مرتفعة. مع الحاجة إلى 754 جيجابايت من ذاكرة الفيديو حتى في وضع INT4، يقع GLM-5 firmly في فئة المؤسسات، حيث يتطلب 8 وحدات معالجة رسوميات على الأقل من فئة H100 لنشر قابل للتطبيق. بالنسبة للمطورين الأفراد والفرق الصغيرة، فإن المسار عبر واجهة برمجة التطبيقات من خلال موفرين مثل Novita AI هو الخيار العملي الوحيد.
الأسئلة الشائعة
هل يمكنني تشغيل GLM-5 على وحدات RTX 4090؟ لا توجد فرصة. ثماني وحدات معالجة رسوميات H100 هي الحد الأدنى.
ما هو الفرق بين إصدارات GLM-5 BF16 و FP8؟ بشكل مدهش، كلاهما ~754 جيجابايت بسبب التكميم الدقيق المختلط في FP8. يقدم FP8 فقدانًا ضئيلًا في الجودة مع سرعة استدلال أفضل قليلاً على وحدات معالجة الرسوميات من فئة H100 فما فوق.
هل يمكنني ضبط GLM-5 دقيقًا على أجهزة المستهلكين؟ لا. يتطلب الضبط الدقيق 2-3 ضعف ذاكرة الفيديو المطلوبة للاستدلال (حالات المحسن، التدرجات)، مما يجعل الأمر مستحيلاً.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة لدينا، مع توفير سحابة لوحدات معالجة الرسوميات بأسعار معقولة وموثوقة للبناء والتوسع.
قراءات موصى بها



