

GLM-5는 Z.AI의 최신 플래그십 모델로, 7540억 개의 파라미터 아키텍처로 오픈소스 언어 모델의 한계를 확장했습니다. 하지만 문제는, 코딩, 추론, 에이전트 작업에서 최고 수준의 성능을 제공하지만 GLM-5를 로컬에서 실행하려면 엔터프라이즈급 하드웨어가 필요하므로 대부분의 개발자가 접근하기 어렵다는 점입니다.
이 가이드는 다양한 정밀도 수준에서 GLM-5에 필요한 VRAM 용량, 이를 처리할 수 있는 GPU, 그리고 로컬 실험과 프로덕션 워크로드 모두에 대한 현실적인 배포 전략을 자세히 설명합니다. 또한 GLM-5의 크기가 의도된 사용 사례(복잡한 시스템 엔지니어링 및 다단계 에이전트 워크플로)에서 중요한 이유도 살펴봅니다.
빠른 답변: GLM-5 VRAM 요구 사항
모든 토큰에 대해 모든 파라미터가 활성화되는 밀집 모델과 달리, GLM-5는 Mixture-of-Experts (MoE) 아키텍처를 사용합니다.
- 총 754B 파라미터가 여러 전문가 네트워크에 분산
- 추론 패스당 40B 활성 파라미터 (전체 파라미터의 약 5.4%만 활성화)
- 효율적인 긴 컨텍스트 처리를 위한 DeepSeek Sparse Attention (DSA)
- 28.5T 토큰의 사전 학습 데이터 (GLM-4.5의 23T에서 증가)
| 정밀도 수준 | 최소 VRAM | GPU 구성 |
|---|---|---|
| BF16 (Full Precision) | 1.51TB | 24× NVIDIA H100 80GB |
| FP8 | 약 800GB | 8× NVIDIA H200 141GB |
| INT4 (Community Quants) | 400GB+ | 8× NVIDIA H100 80GB |
권장 구성: INT4용 8× H100 80GB + NVLink. NVLink 브리지당 900GB/s의 고대역폭 GPU 상호 연결로 총 640GB VRAM을 제공하며, MoE 모델의 효율적인 파라미터 라우팅에 필수적입니다.
소비자 하드웨어: 현실적이지 않음
솔직히 말해서 GLM-5는 소비자 GPU용으로 설계되지 않았습니다. 모델을 맞출 수 있다고 해도 NVLink 없이는 추론 속도가 매우 느려집니다. 소비자용 마더보드는 효율적인 텐서 병렬 처리에 필요한 GPU 간 대역폭이 부족합니다.
GLM-5 성능: VRAM 비용이 그만한 가치가 있을까?
GLM-5는 높은 실행 신뢰성과 장기적인 도구 워크플로가 필요할 때, 특히 Claude Code 스타일 환경에서 유용합니다. 가장 강력한 증거는 GLM-5가 엔지니어링 실행 모델처럼 동작한다는 점입니다.
- 프론트엔드 빌드 성공률 98%
이는 GLM-5가 단순히 “그럴듯한” 코드가 아니라 실제로 컴파일되고 실행되는 코드를 생성함을 강력하게 시사합니다.
또한 에이전트 벤치마크에서도 매우 뛰어난 성능을 보입니다.
- BrowseComp w/ Context Manage: 75.9
- τ²-Bench: 89.7
- MCP-Atlas Public Set: 67.8
GLM-5가 적합하지 않은 경우
작업이 다음과 같다면:
- 작은 스크립트
- 단일 파일 코딩
- 짧은 Q&A 디버깅
- 간단한 웹 컴포넌트
- “코드 스니펫 생성” 작업
GLM-5의 긴 컨텍스트 엔지니어링 이점이 발휘되지 않으며, 적은 이득을 위해 막대한 VRAM 비용을 지불하는 셈입니다. 이런 경우 Minimax M2.5와 같은 모델이 훨씬 비용 효율적입니다.
https://www.youtube.com/watch?v=3XCYruBYr-0
배포 옵션: 클라우드 vs 로컬
옵션 1: API 제공업체 (가장 쉬움)
대부분의 개발자에게 API를 통해 GLM-5를 사용하는 것이 유일한 실질적인 선택지입니다.
Novita AI를 Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow, OpenClaw와 같은 파트너 플랫폼에 손쉽게 연결할 수 있습니다. 공식 통합 및 단계별 설정 가이드를 통해 확인하세요.
옵션 2: 클라우드 GPU 임대
Step 1: 계정 등록
웹사이트를 통해 Novita AI 계정을 만드세요. 등록 후 왼쪽 사이드바에서 “Explore” 섹션으로 이동하여 GPU 서비스를 확인하고 AI 개발 여정을 시작하세요.

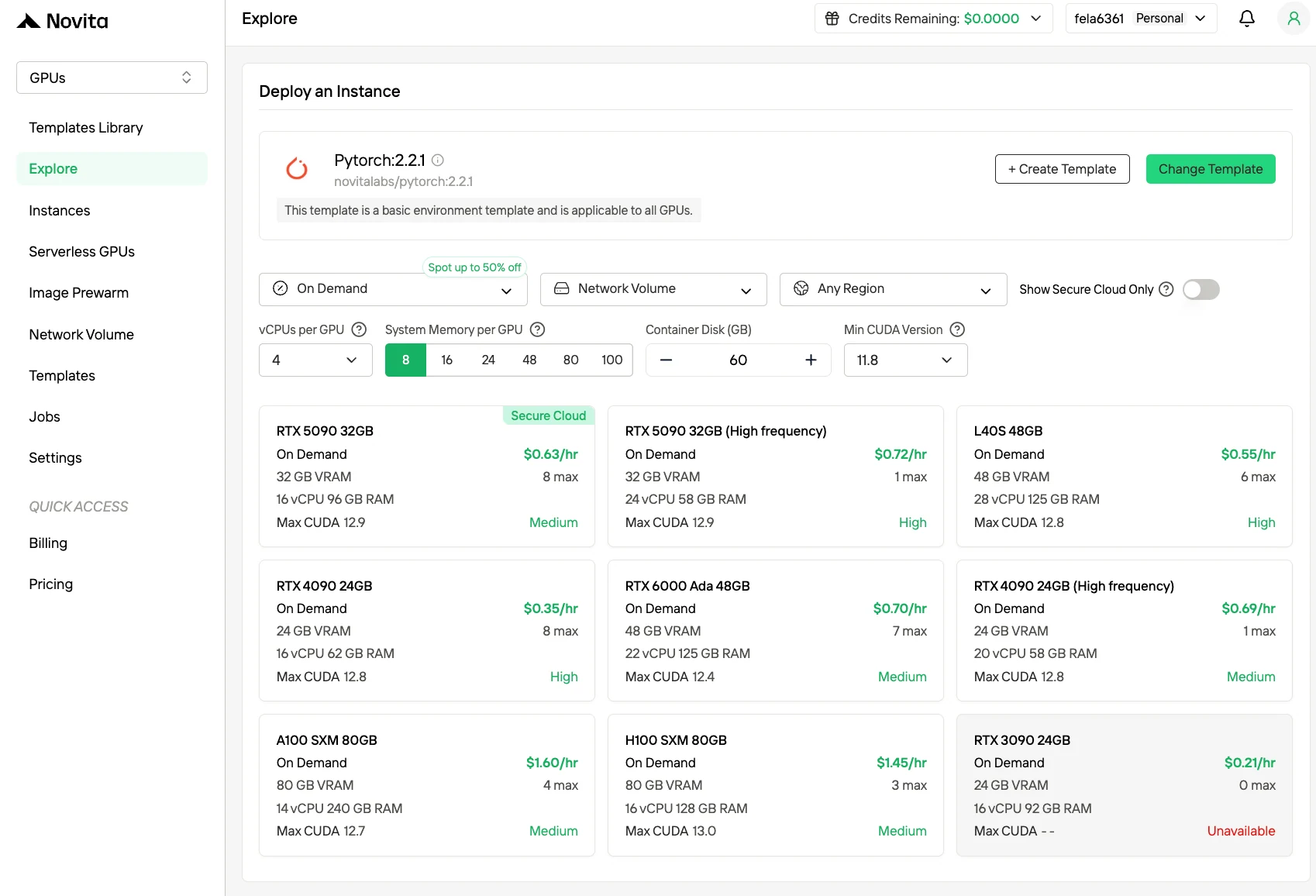
Step 2: 템플릿 및 GPU 서버 탐색
프로젝트 요구 사항에 맞는 PyTorch, TensorFlow, CUDA 등의 템플릿을 선택하세요. 그런 다음 원하는 GPU 구성을 선택하세요. H100과 같은 강력한 옵션을 사용할 수 있으며, 각각 VRAM, RAM, 스토리지 사양이 다릅니다.
Step 3: 배포 맞춤 설정
선호하는 운영 체제와 구성 옵션을 선택하여 특정 AI 워크로드 및 개발 요구 사항에 최적의 성능을 발휘하도록 환경을 사용자 지정하세요.
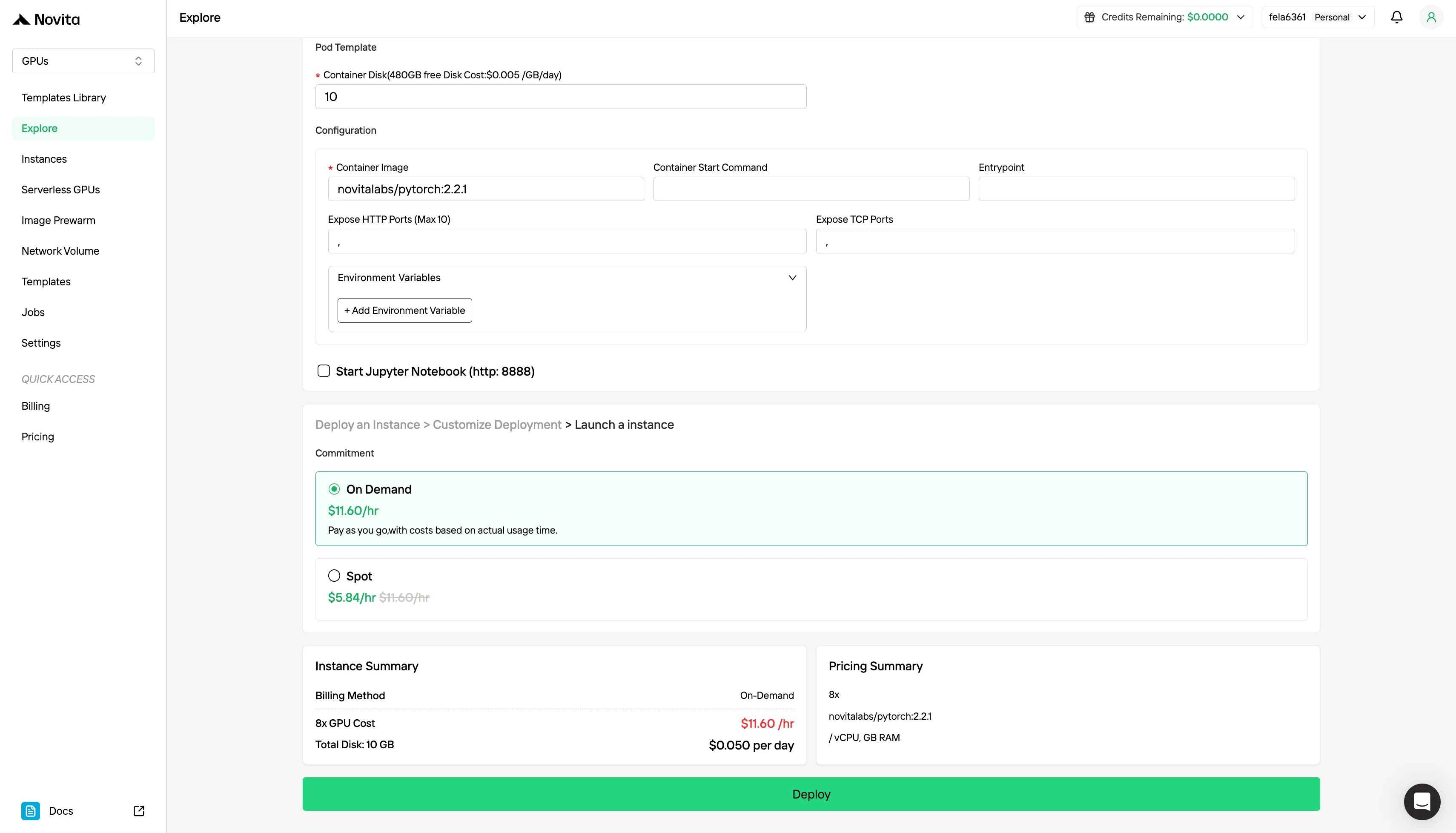
표준 On-Demand 요금제 외에도 Novita AI는 비용에 민감한 워크로드를 위해 훨씬 저렴한 GPU 옵션인 Spot 모드를 제공합니다.
Novita AI Spot 모드는 플랫폼의 유휴 또는 미사용 GPU 용량을 활용하는 비용 최적화 GPU 임대 시스템입니다. 안정적인 지속 사용을 위해 전용 하드웨어를 예약하는 On-Demand 인스턴스와 달리, Spot 인스턴스는 중단 가능합니다. GPU가 시스템에 의해 회수되면 작업이 일시 중지되거나 종료될 수 있습니다. Spot 모드는 사용되지 않는 GPU 리소스를 재할당하므로 일반적으로 On-Demand 가격보다 40–60% 저렴합니다.
옵션 3: 로컬 배포 (연구용)
고급 워크스테이션이나 연구실 클러스터에 접근할 수 있는 경우:
- 하드웨어 요구 사항: INT4용 8× H100/A100
- 소프트웨어 스택: 텐서 병렬 처리를 지원하는 vLLM 0.6+ 또는 SGLang
- 스토리지: 모델 가중치 및 빠른 로딩을 위한 2TB+ NVMe SSD
- 메모리: GPU 전송 전 체크포인트 로딩을 위한 512GB+ 시스템 RAM

GLM-5는 에이전트 AI에서 가능성의 경계를 넓히는 새로운 초대형 오픈소스 모델을 대표하지만, 그에 따른 가파른 하드웨어 비용이 따릅니다. INT4에서도 754GB의 VRAM이 필요하기 때문에 GLM-5는 엔터프라이즈 영역에 확고히 자리잡고 있으며, 실행 가능한 배포를 위해서는 8개 이상의 H100급 GPU가 필요합니다. 개인 개발자나 소규모 팀에게는 Novita AI와 같은 제공업체의 API 경로가 유일한 실질적인 선택지입니다.
자주 묻는 질문
RTX 4090에서 GLM-5를 실행할 수 있나요?
불가능합니다. H100 GPU 8개가 최소 기준입니다.
GLM-5 BF16과 FP8 버전의 차이점은 무엇인가요?
놀랍게도 FP8의 혼합 정밀도 양자화로 인해 둘 다 약 754GB입니다. FP8은 H100+ GPU에서 약간 더 나은 추론 속도로 최소한의 품질 손실을 제공합니다.
소비자 하드웨어에서 GLM-5를 파인튜닝할 수 있나요?
아니요. 파인튜닝에는 추론보다 2~3배 많은 VRAM(옵티마이저 상태, 그래디언트)이 필요하므로 불가능합니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 지원하는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드도 제공합니다.
추천 문서



