

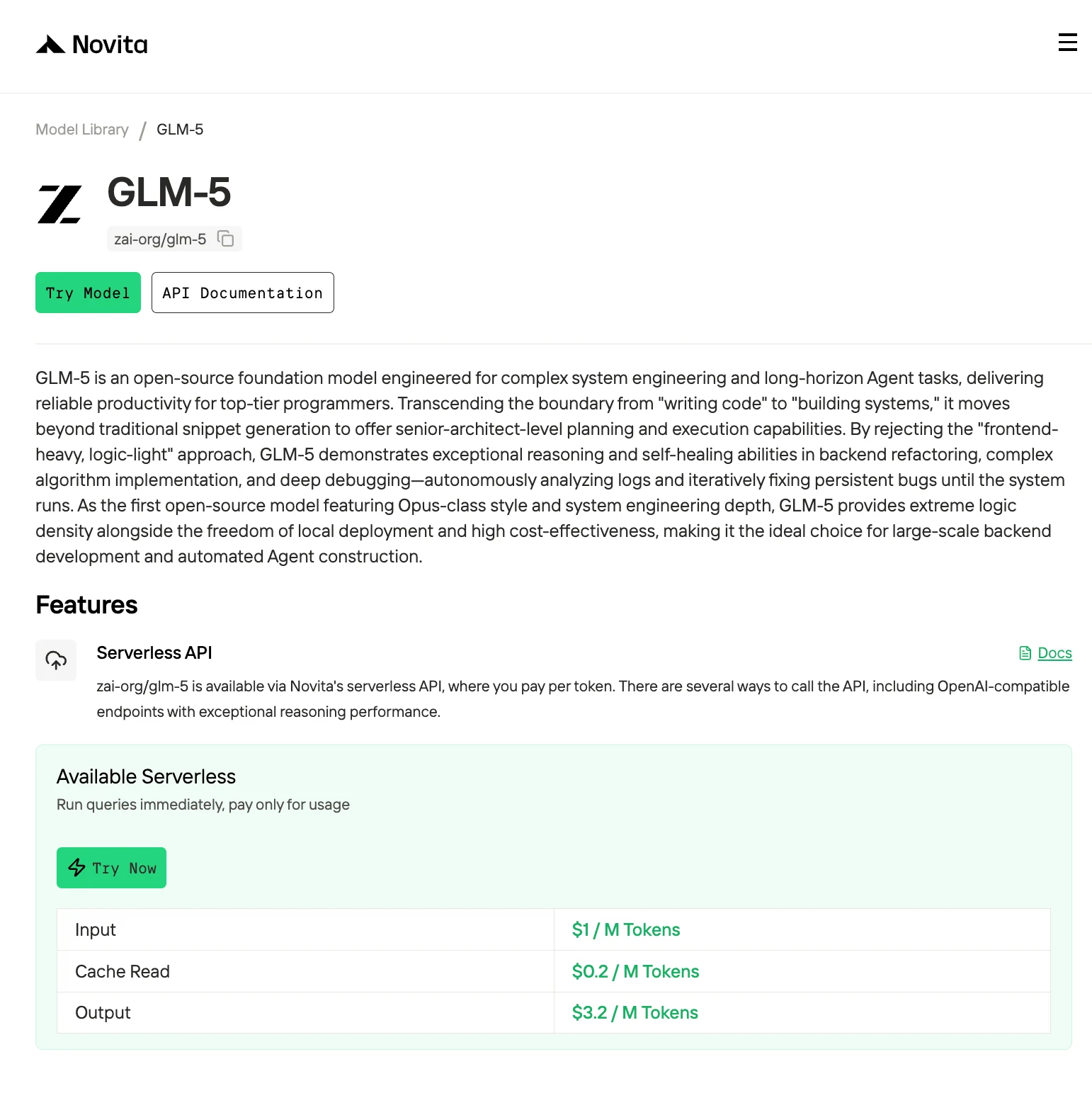
GLM-5 是 Z.AI 最新的旗舰模型,以其庞大的 7540 亿参数架构,突破了开源语言模型的边界。但问题在于:尽管它在编码、推理和智能体任务上提供了顶级性能,但本地运行 GLM-5 需要企业级硬件,这使得大多数开发者望尘莫及。
本指南将详细分解 GLM-5 在不同精度下需要多少 VRAM,哪些 GPU 可以处理它,以及针对本地实验和生产工作负载的实际部署策略。我们还将探讨 GLM-5 的规模为何对其预期用途(复杂系统工程和多步骤智能体工作流)至关重要。
快速解答:GLM-5 VRAM 需求
与每个 token 都激活全部参数的密集模型不同,GLM-5 采用混合专家(MoE)架构,具有:
- 总计 754B 参数,分布在多个专家网络中
- 每次推理 40B 活跃参数(仅有约 5.4% 的参数活跃)
- DeepSeek 稀疏注意力(DSA),实现高效的长上下文处理
- 28.5T token 预训练数据(高于 GLM-4.5 的 23T)
| 精度等级 | 最低 VRAM | GPU 配置 |
|---|---|---|
| BF16(全精度) | 1.51TB | 24× NVIDIA H100 80GB |
| FP8 | 约 800GB | 8× NVIDIA H200 141GB |
| INT4(社区量化) | 400GB+ | 8× NVIDIA H100 80GB |
推荐配置:8× H100 80GB 搭配 NVLink,用于 INT4。这提供了 640GB 总 VRAM,并具备高带宽 GPU 互连(每个 NVLink 桥接器 900 GB/s),这对 MoE 模型中的高效参数路由至关重要。
消费级硬件:不现实
直白地说:GLM-5 并非为消费级 GPU 设计。即使能装下模型,没有 NVLink 的推理速度也会慢得难以忍受。消费级主板缺乏用于高效张量并行所需的 GPU 间带宽。
GLM-5 性能:VRAM 成本值得吗?
当你需要高执行可靠性和长周期工具工作流时(尤其是在 Claude Code 风格的环境中),GLM-5 就非常值得。最强有力的证据是:GLM-5 表现得像一个工程执行模型:
- 前端构建成功率 98%
这强烈表明 GLM-5 生成的是能编译并运行的代码,而不仅仅是“听起来不错”的代码。
它在智能体基准测试上也表现出色:
- BrowseComp w/ 上下文管理:75.9
- τ²-Bench:89.7
- MCP-Atlas 公共集:67.8
什么时候不值得使用 GLM-5
如果你的工作涉及:
- 小型脚本
- 单文件编码
- 简短问答调试
- 简单 Web 组件
- “生成代码片段”类任务
那么 GLM-5 的长上下文工程优势无法发挥,而你却要为微小的增益支付巨大的 VRAM 成本。这种情况下,Minimax M2.5 等模型性价比更高。
https://www.youtube.com/watch?v=3XCYruBYr-0
部署选项:云端 vs 本地
选项 1:API 提供商(最简单)
对大多数开发者而言,通过 API 使用 GLM-5 是唯一实用的选择。
通过官方集成和分步设置指南,轻松将 Novita AI 与合作伙伴平台连接,如 Claude Code、Trae、Continue、Codex、OpenCode、AnythingLLM、LangChain、Dify、Langflow 和 OpenClaw 等。
选项 2:云端 GPU 租赁
步骤 1:注册账户
通过我们的网站创建 Novita AI 账户。注册后,导航到左侧边栏的“探索”部分,查看我们的 GPU 产品,开启你的 AI 开发之旅。

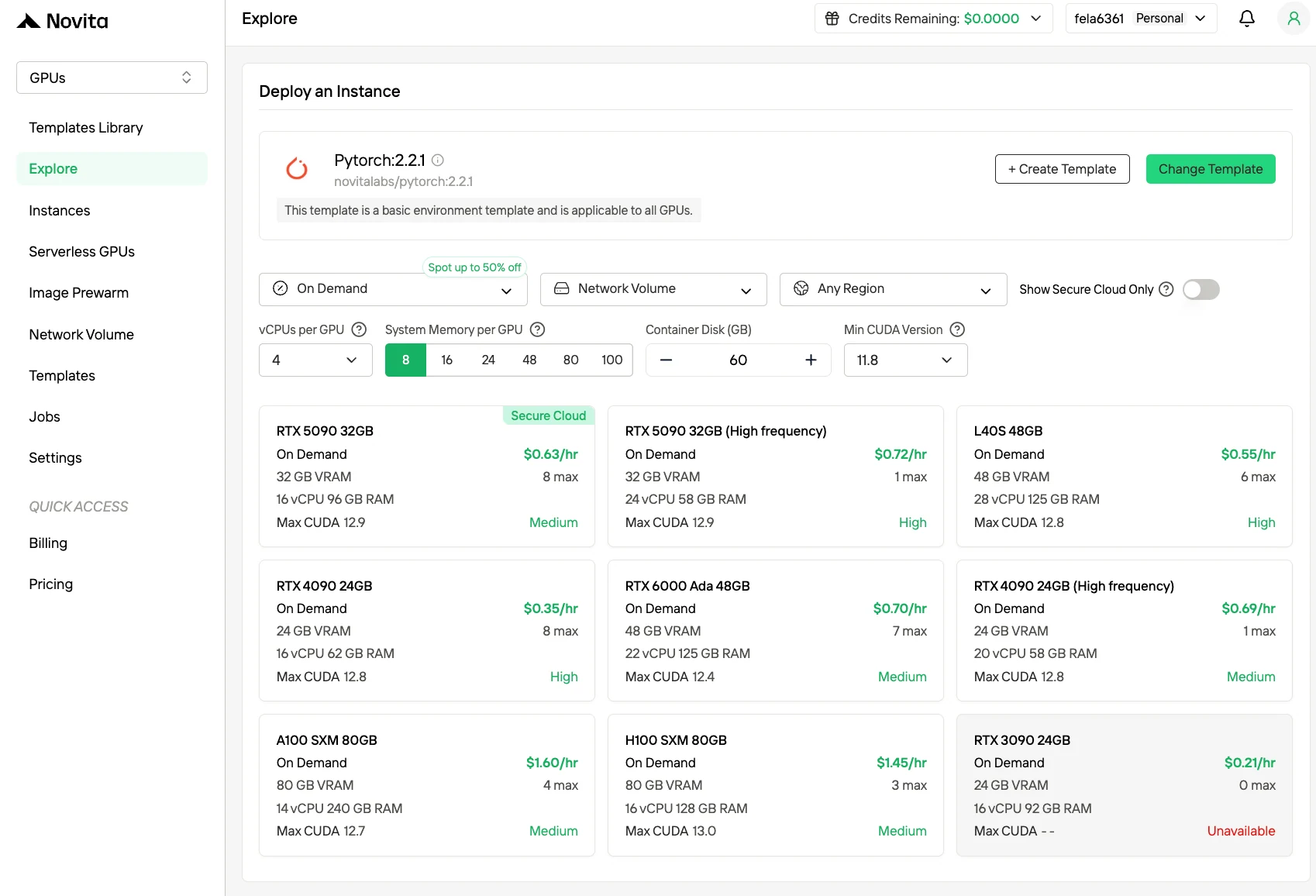
步骤 2:探索模板和 GPU 服务器
选择与项目需求匹配的模板,如 PyTorch、TensorFlow 或 CUDA。然后选择你偏好的 GPU 配置——选项包括强大的 H100,每种都有不同的 VRAM、RAM 和存储规格。
步骤 3:定制你的部署
通过选择偏好的操作系统和配置选项来定制环境,确保针对特定 AI 工作负载和开发需求获得最佳性能。
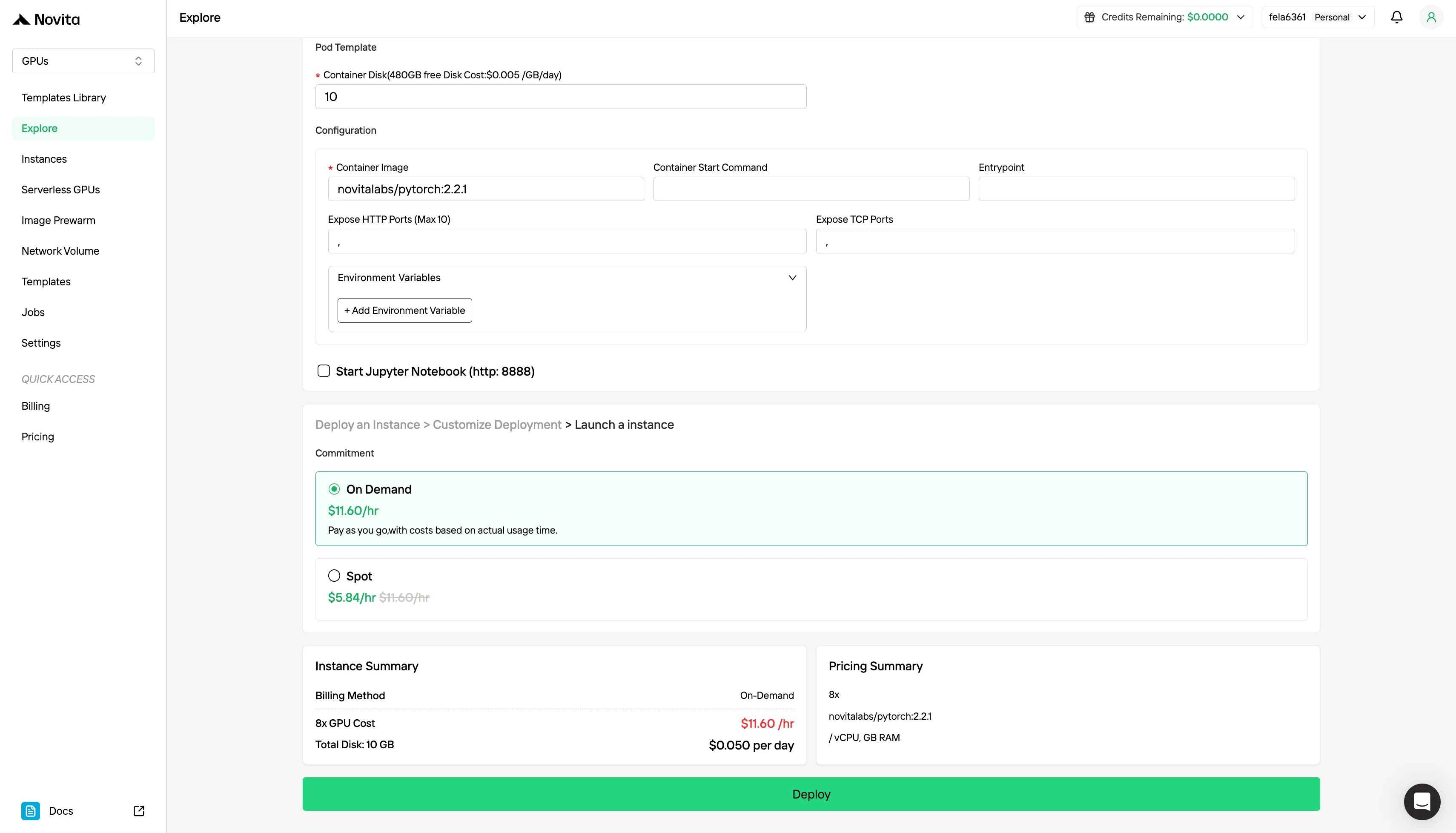
除了标准的按需定价模式外,Novita AI 还提供 Spot 模式,这是一种显著更便宜的 GPU 选项,专为对成本敏感的工作负载设计。
Novita AI 的 Spot 模式是一种成本优化的 GPU 租赁系统,利用平台闲置或未使用的 GPU 容量。与按需实例(保留专用硬件以进行稳定、连续使用)不同,Spot 实例是可中断的——如果系统回收 GPU,你的任务可能会暂停或终止。由于 Spot 模式重新分配了原本未使用的 GPU 资源,其价格通常比按需定价便宜 40–60%。
选项 3:本地部署(仅限研究)
如果你能访问高端工作站或实验室集群:
- 硬件需求: 8× H100/A100(用于 INT4)
- 软件栈: 支持张量并行的 vLLM 0.6+ 或 SGLang
- 存储: 2TB+ NVMe SSD(用于模型权重和快速加载)
- 内存: 512GB+ 系统 RAM(用于在 GPU 传输前加载检查点)

GLM-5 代表了一类新型超大型开源模型,它推动了智能体 AI 的可能性边界——但代价是高昂的硬件成本。即使在 INT4 下也需要 754GB VRAM,GLM-5 坚定地属于企业领域,需要 8 块以上 H100 级 GPU 才能进行可行部署。对于个人开发者和小团队,通过 Novita AI 等提供商使用 API 是唯一实用的选择。
常见问题
我能在 RTX 4090 上运行 GLM-5 吗?
不可能。八块 H100 GPU 是底线。
GLM-5 的 BF16 和 FP8 版本有什么区别?
出人意料,两者都需要约 754GB,因为 FP8 采用了混合精度量化。FP8 的质量损失极小,在 H100+ GPU 上推理速度略有提升。
我能用消费级硬件微调 GLM-5 吗?
不能。微调所需的 VRAM 是推理的 2-3 倍(优化器状态、梯度),因此不可能。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的简便途径,同时还提供经济实惠且可靠的 GPU 云,用于构建和扩展。
推荐阅读



