

GLM-5 是 Z.AI 最新的旗艦模型,擁有 7540 億參數的龐大架構,再次推進了開源語言模型的極限。但問題在於:雖然它在編碼、推理與代理任務上表現頂尖,但要本地執行 GLM-5,就需要企業級硬體,這對大多數開發者來說遙不可及。
本指南將詳細說明 GLM-5 在不同精度下所需的 VRAM 容量、哪些 GPU 可以支援,以及適合本地實驗與生產負載的實際部署策略。我們也會探討 GLM-5 的巨大規模為何與其預期用途(複雜系統工程與多步驟代理工作流程)密不可分。
快速解答:GLM-5 VRAM 需求
與所有參數在每個 token 都會啟動的密集模型不同,GLM-5 採用混合專家(MoE)架構,包含:
- 7540 億總參數,分散於多個專家網路
- 每次推理 400 億活躍參數(僅約 5.4% 的總參數啟動)
- DeepSeek 稀疏注意力(DSA),實現高效的長上下文處理
- 28.5 兆 tokens 的預訓練資料(較 GLM-4.5 的 23 兆有所增長)
| 精度等級 | 最低 VRAM | GPU 配置 |
|---|---|---|
| BF16(全精度) | 1.51TB | 24× NVIDIA H100 80GB |
| FP8 | 約 800GB | 8× NVIDIA H200 141GB |
| INT4(社群量化) | 400GB+ | 8× NVIDIA H100 80GB |
建議配置:8× H100 80GB 搭配 NVLink,使用 INT4 精度。這樣可提供 640GB 總 VRAM,並透過高速 GPU 互連(每個 NVLink 橋接器 900 GB/s)支援高效的 MoE 參數路由。
消費級硬體:不切實際
老實說:GLM-5 不是為消費級 GPU 設計的。即使你能放入模型,沒有 NVLink 的推理速度也會慢得難以忍受。消費級主機板缺乏進行高效張量並行所需的 GPU 間頻寬。
GLM-5 效能:VRAM 成本值得嗎?
當你需要高執行可靠度與長時程工具工作流程時(特別是在 Claude Code 類型的環境中),GLM-5 就顯得意義非凡。最有力的證據是 GLM-5 表現得像一個「工程執行模型」:
- 前端建置成功率 98%
這強烈表示 GLM-5 產生的程式碼能編譯並執行,而不只是「聽起來合理」的程式碼。
它在代理基準測試中的表現也極為出色:
- BrowseComp(含上下文管理):75.9
- τ²-Bench:89.7
- MCP-Atlas 公開集:67.8
何時 GLM-5 不值得
如果你的工作內容是:
- 小型腳本
- 單一檔案編碼
- 簡短 Q&A 除錯
- 簡單網頁元件
- 「產生程式碼片段」任務
那麼 GLM-5 的長上下文工程優勢便無法發揮,你是在為微小的收益付出巨大的 VRAM 成本。在這種情況下,像是 Minimax M2.5 這樣的模型會划算得多。
https://www.youtube.com/watch?v=3XCYruBYr-0
部署選項:雲端 vs 本地
選項 1:API 供應商(最簡單)
對大多數開發者來說,透過 API 使用 GLM-5 是唯一實際的選擇。
透過官方整合與逐步設定指南,輕鬆將 Novita AI 與合作平台連接,例如 Claude Code、Trae、Continue、Codex、OpenCode、AnythingLLM、LangChain、Dify、Langflow 與 OpenClaw。
選項 2:雲端 GPU 租賃
步驟 1:註冊帳號
透過我們的網站建立你的 Novita AI 帳號。註冊後,點擊左側邊欄的「探索」區塊,查看我們的 GPU 方案,開始你的 AI 開發旅程。

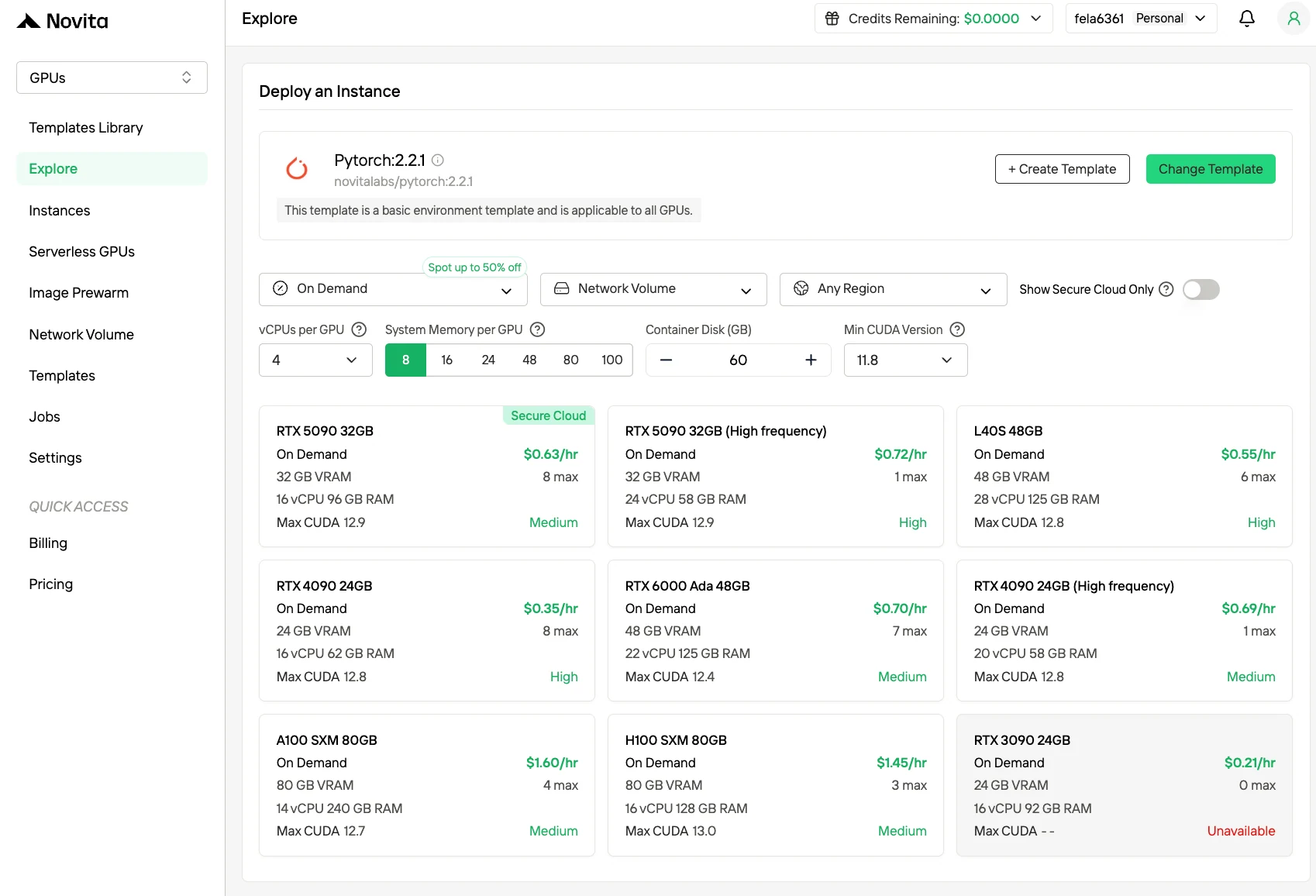
步驟 2:探索模板與 GPU 伺服器
從 PyTorch、TensorFlow 或 CUDA 等模板中選擇符合專案需求的方案。然後選擇你偏好的 GPU 配置——選項包括強大的 H100,各有不同的 VRAM、RAM 與儲存規格。
步驟 3:自訂部署
自訂你的環境,選擇偏好的作業系統與配置選項,確保你的特定 AI 工作負載與開發需求能達到最佳效能。
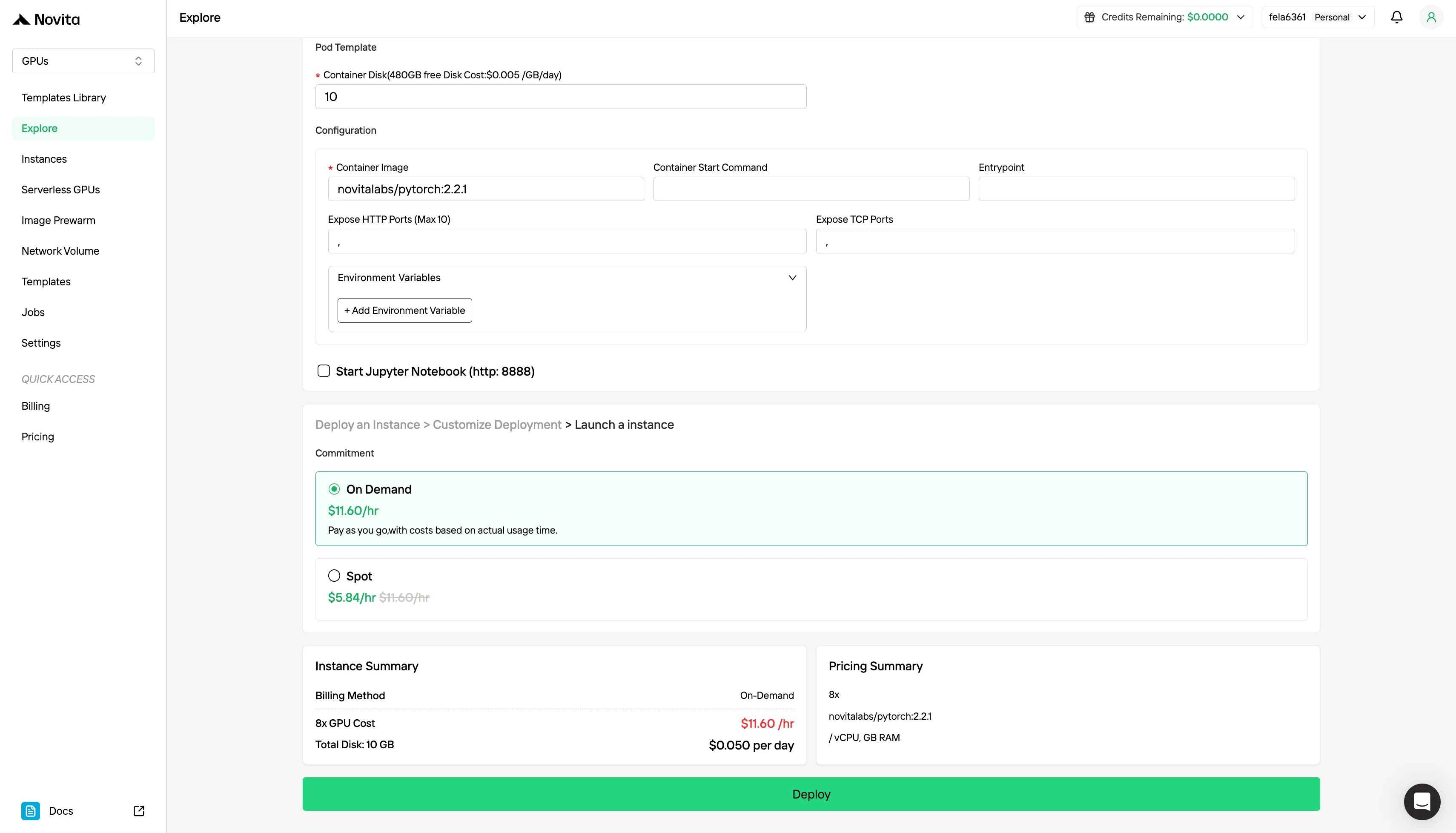
除了標準的隨需計費模式外,Novita AI 也提供 Spot 模式,這是一種專為成本敏感工作負載設計、價格顯著更低的 GPU 選項。
**Novita AI 的 Spot 模式 ** 是一種成本最佳化的 GPU 租賃系統,利用平台閒置或未使用的 GPU 容量。不同於隨需執行個體會保留專用硬體以提供穩定、持續的使用,Spot 執行個體是 ** 可中斷的 ——如果 GPU 被系統回收,你的任務可能會暫停或終止。由於 Spot 模式重新分配了原本未使用的 GPU 資源,其價格通常比隨需定價 ** 便宜 40% 至 60%。
選項 3:本地部署(僅限研究用途)
如果你能使用高階工作站或實驗室叢集:
- 硬體需求: 8× H100/A100,用於 INT4
- 軟體堆疊: vLLM 0.6 以上版本或 SGLang,搭配張量並行支援
- 儲存: 2TB 以上 NVMe SSD,儲存模型權重並加速載入
- 記憶體: 512GB 以上系統 RAM,用於在將檢查點傳輸至 GPU 前載入

GLM-5 代表了一種新型的超大規模開源模型,將代理式 AI 的可能性推向新高度——但代價是高昂的硬體成本。即使在 INT4 精度下也需要 754GB VRAM,GLM-5 穩穩落在企業領域,需要 8 張以上 H100 等級 GPU 才能有效部署。對於個人開發者和小型團隊,透過 Novita AI 等供應商使用 API 是唯一可行的選擇。
常見問題
我能在 RTX 4090 上執行 GLM-5 嗎?
不可能。八張 H100 GPU 是最低門檻。
GLM-5 BF16 與 FP8 版本有何不同?
令人意外的是,兩者都約為 754GB,因為 FP8 使用了混合精度量化。FP8 在 H100 以上 GPU 上的推理速度略快,且品質損失極小。
我能在消費級硬體上微調 GLM-5 嗎?
不行。微調需要推理時 2 至 3 倍的 VRAM(優化器狀態、梯度),因此無法實現。
Novita AI 是一個 AI 雲端平台,讓開發者能透過簡單的 API 輕鬆部署 AI 模型,同時提供價格合理且可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。
推薦閱讀



