

MiniMax M2.5 kann auf Consumer-Hardware laufen – aber nur mit aggressiver Quantisierung. Mit der Dynamic 3-bit GGUF-Quantisierung von Unsloth AI können Sie das 457 GB große Vollpräzisionsmodell auf ca. 101 GB schrumpfen. Dieser Leitfaden erklärt die tatsächlichen VRAM-Anforderungen für verschiedene Quantisierungsstufen und ordnet sie spezifischen GPU-Konfigurationen mit Novita AI Cloud-Preisen zu.
MiniMax M2.5 Einführung
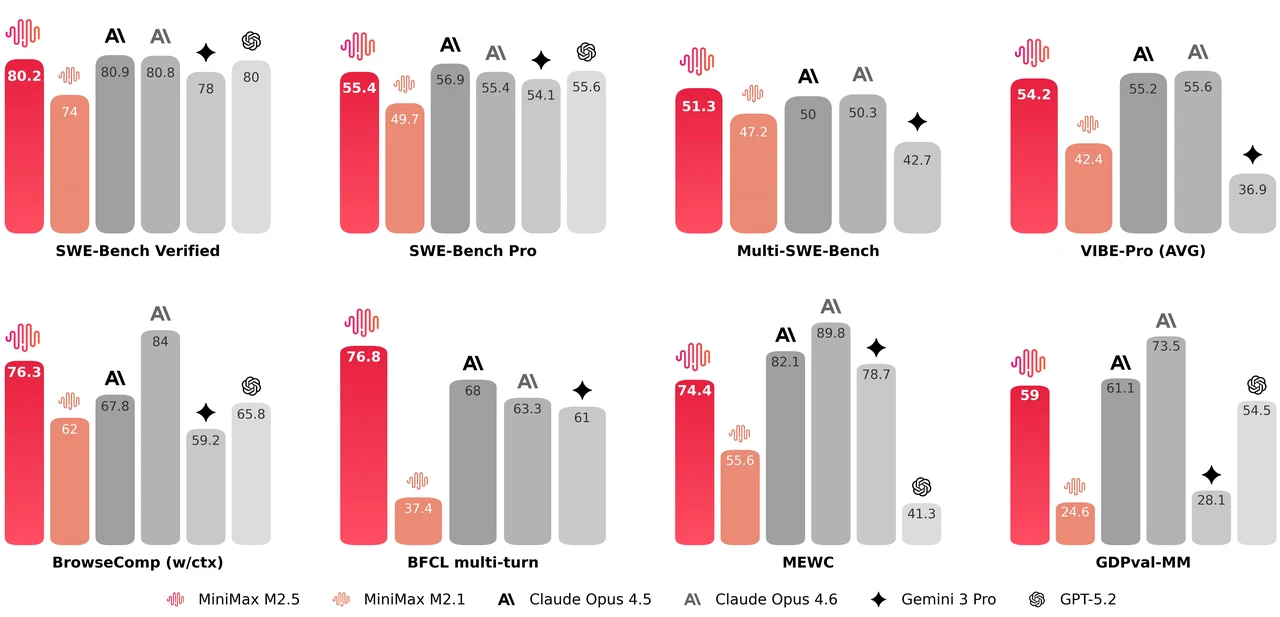
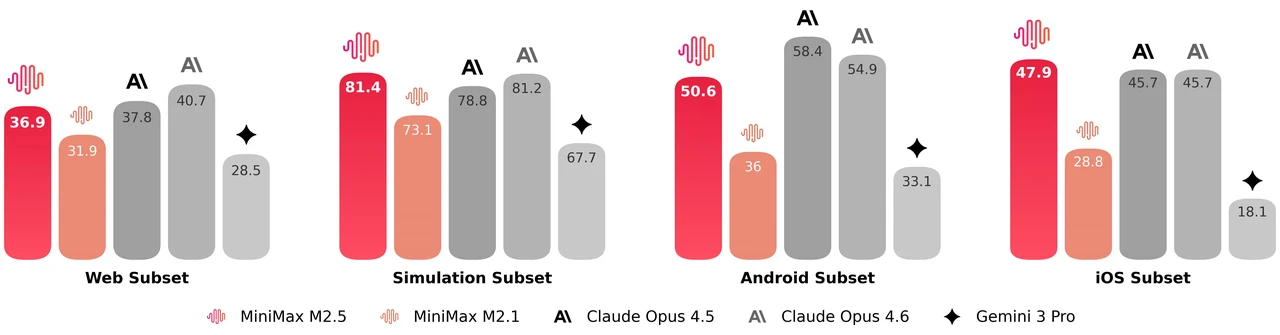
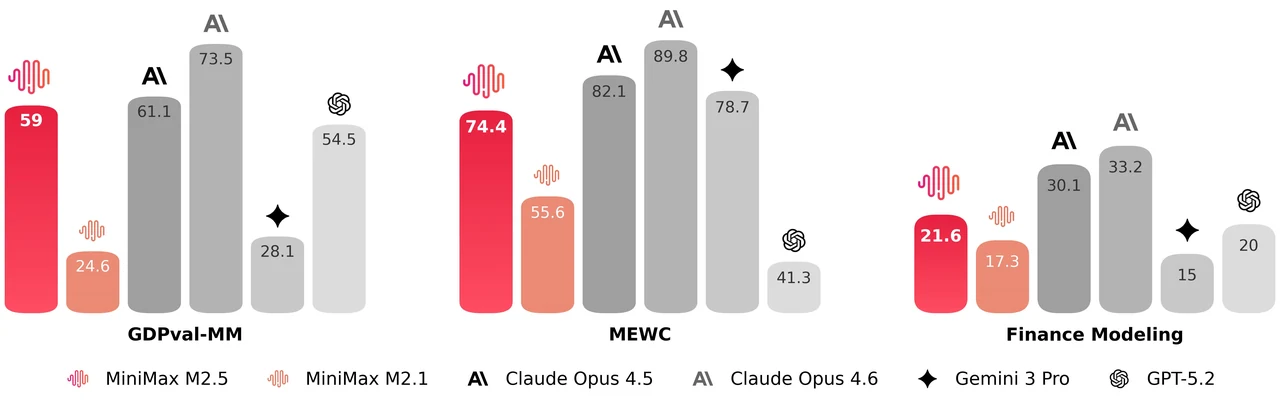
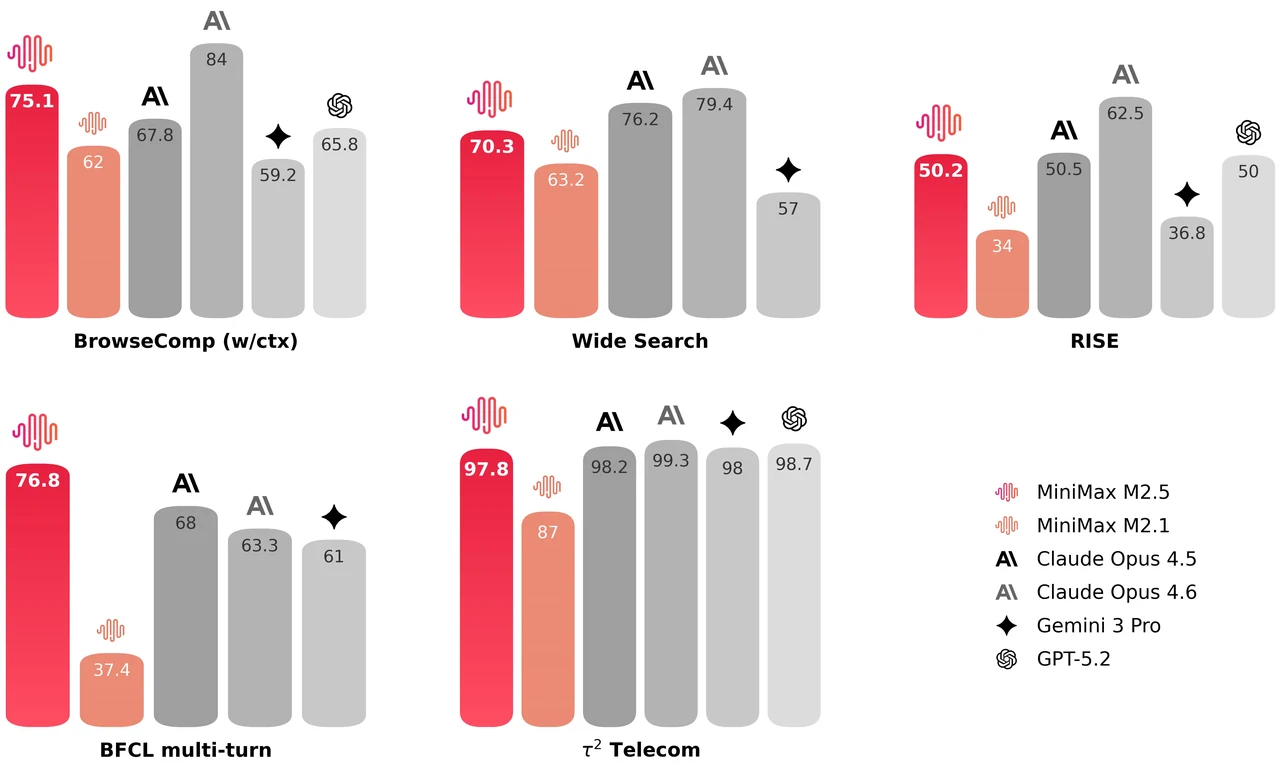
MiniMax M2.5 ist ein 229B Parameter-Mixture-of-Experts-Modell mit 256 Expertenschichten, das pro Token 8 Experten (ca. 10B Parameter) aktiviert. Es erreicht 80,2 % bei SWE-Bench Verified, 51,3 % bei Multi-SWE-Bench und 76,3 % bei BrowseComp, was es zu einem der stärksten Open-Modelle für agentisches Coding und Tool-Nutzung macht. Das Modell unterstützt ein 205K Token-Kontextfenster und ist MIT-lizenziert für uneingeschränkte kommerzielle Nutzung.
Von Huggingface
Von Huggingface
Von Huggingface
VRAM-Anforderungen von MiniMax M2.5
Der VRAM-Bedarf skaliert mit der Präzisionsstufe. Die folgende Tabelle zeigt Dateigrößen der GGUF-Quantisierungen von Unsloth und hybriden AWQ-Formaten – addieren Sie 4–10 GB Overhead für den KV-Cache, abhängig von Kontextlänge und Batch-Größe.
| Konfiguration | Erforderlicher VRAM |
|---|---|
| BF16 (Vollpräzision) | 457 GB |
| Q8_0 GGUF | 243 GB |
| Q6_K GGUF | 188 GB |
| Q4_K_M GGUF | 138 GB |
| IQ4_XS GGUF | 122 GB |
| Q3_K_M GGUF (Dynamic 3-bit) | 109 GB |
| Q2_K GGUF | 83 GB |
| UD-IQ2_XXS GGUF (Ultra-Dynamic 2-bit) | 74 GB |
Mit einem hybriden Quantisierungsschema (INT4 AWQ-Gewichte, FP8-Aufmerksamkeit und kalibrierter FP8 KV-Cache) kann MiniMax M2.5 einen 370K-Kontext auf 192 GB VRAM erreichen und ermöglicht im Vergleich zu Standard-AWQ, das typischerweise durch den KV-Cache begrenzt ist, einen deutlich höheren Batch-Durchsatz.
GPU-Empfehlungen für MiniMax M2.5
Alle unten genannten Preise entsprechen den Novita AI On-Demand-Raten. Multi-GPU-Kosten werden als Einzel-GPU-Preis × Anzahl berechnet.
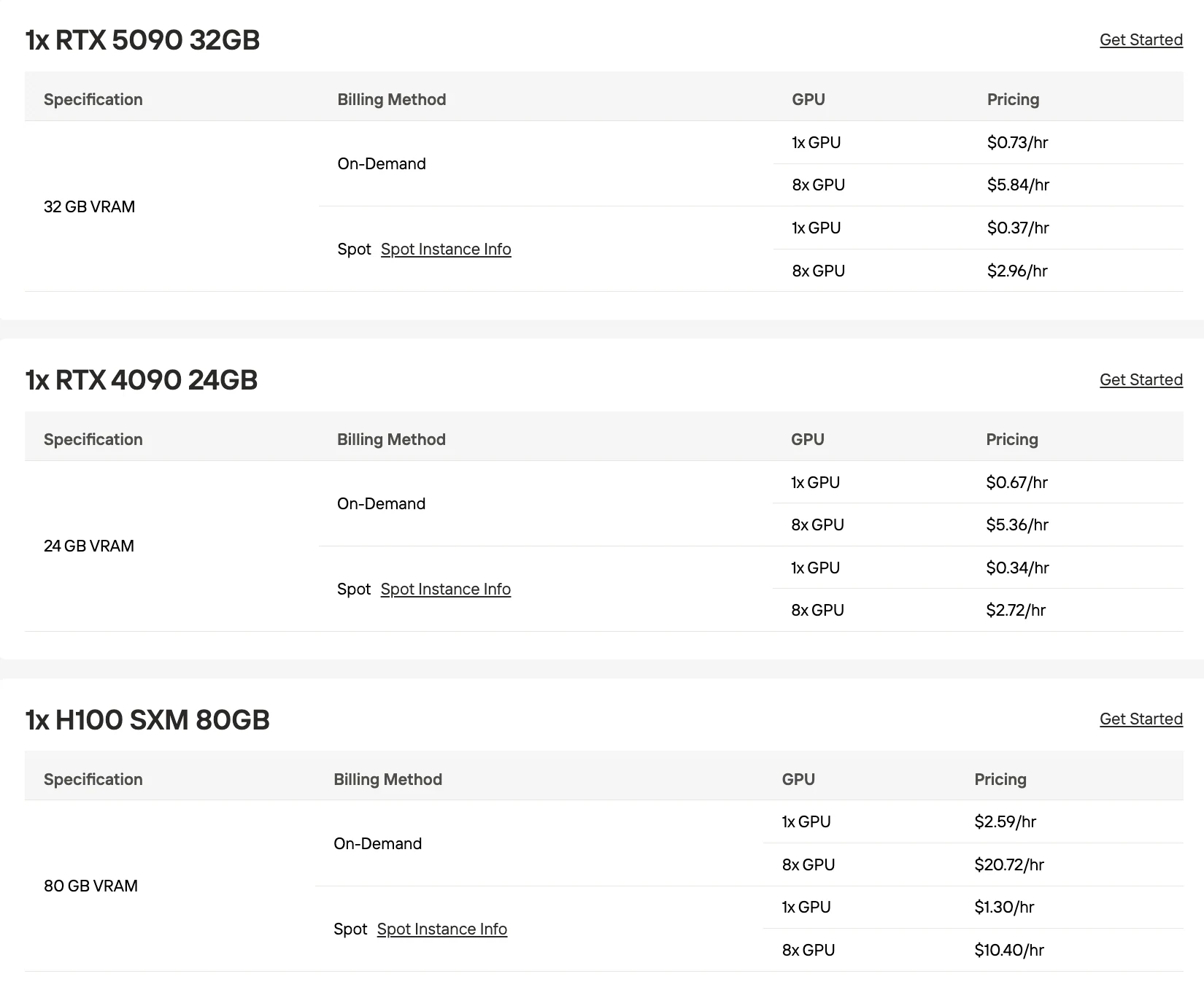
RTX 5090 (32 GB)
| Konfiguration | Gesamter VRAM | Quantisierung | Hinweise |
|---|---|---|---|
| 3× RTX 5090 | 96 GB | Q2_K | Funktioniert, aber stößt an Speichergrenzen |
| 4× RTX 5090 | 128 GB | Q3_K_M Dynamic 3-bit | Stabil mit moderater Batch-Größe |
H100 (80 GB)
| Konfiguration | Gesamter VRAM | Quantisierung | Hinweise |
|---|---|---|---|
| 2× H100 | 160 GB | Q4_K_M | Stabile Bereitstellung mit höherer Modellqualität |
Nicht empfohlen: Eine einzelne RTX 4090 oder RTX 5090 kann MiniMax M2.5 selbst bei der aggressivsten Quantisierung nicht aufnehmen. Der Strix Halo APU mit Q3_K_M liefert “fast unbrauchbare” Geschwindigkeiten, verarbeitet 80K Kontext, aber mit unpraktischen Inferenzgeschwindigkeiten.
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
Probieren Sie kostengünstige GPUs aus!
Praktische Bereitstellungsstrategien
Strategie 1: API-First mit Spot-GPU-Failover
Beginnen Sie mit der Novita AI API für 0,30 $/1,20 $ pro 1M Token für Entwicklung und leichte Produktion. Wenn der Datenverkehr über ~100M Token/Monat (150 $/Monat API-Kosten) hinausgeht, starten Sie Spot-Instanzen von 2×H100 für 5,18 $/Stunde für Batch-Verarbeitungsaufträge und behalten Sie die API für Echtzeit-Anwender-Inferenz bei. Dieser hybride Ansatz begrenzt die Kosten, während er niedrige Latenz für interaktive Nutzung beibehält.
Um die Kosten im großen Maßstab weiter zu senken, bietet Novita kostengünstige API-Preise sowie Rabatte für Prompt-Cache-Lesezugriffe. Wenn Prompts wiederverwendet werden (z. B. Systemanweisungen, Vorlagen oder wiederholter Kontext), werden zwischengespeicherte Token zu einem niedrigeren Tarif bereitgestellt, anstatt neu berechnet zu werden – das senkt sowohl Latenz als auch Kosten. Dies macht die API-First + Batch-Architektur noch effizienter, insbesondere für agentische Workflows und häufige Abfragen.
Probieren Sie MiniMax M2.5 jetzt aus!
Strategie 2: Selbst gehostet mit Quantisierung
Für Teams mit Datenschutzanforderungen oder hochvolumigen, anhaltenden Workflows setzen Sie Q3_K_M Dynamic 3-bit oder Q4_K_M-Quantisierung auf 2×H100 ein. Nutzen Sie llama.cpp für GGUF-Formate oder vLLM mit AWQ für produktionsreife Durchsatzoptimierung.
Wie greife ich auf MiniMax M2.5 in Cloud-GPUs zu?
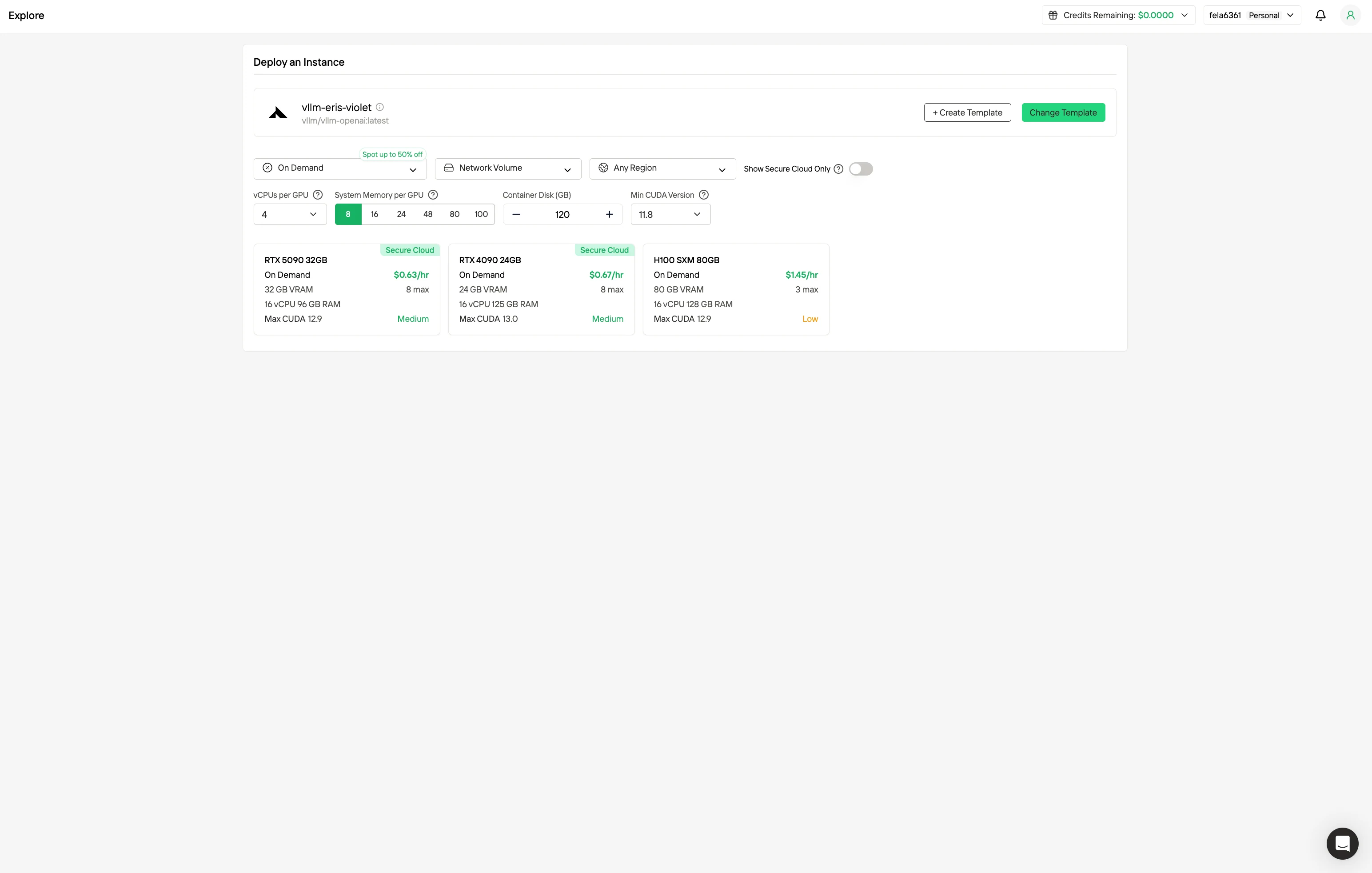
Schritt 1: Konto erstellen Erstellen Sie Ihr Novita AI-Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Entdecken" in der linken Seitenleiste, um unsere GPU-Angebote einzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2: Vorlagen und GPU-Server erkunden Wählen Sie Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu den Anforderungen Ihres Projekts passen. Wählen Sie anschließend Ihre bevorzugte GPU-Konfiguration – Optionen umfassen leistungsstarke GPUs, jede mit unterschiedlichen VRAM-, RAM- und Spezifikationen.
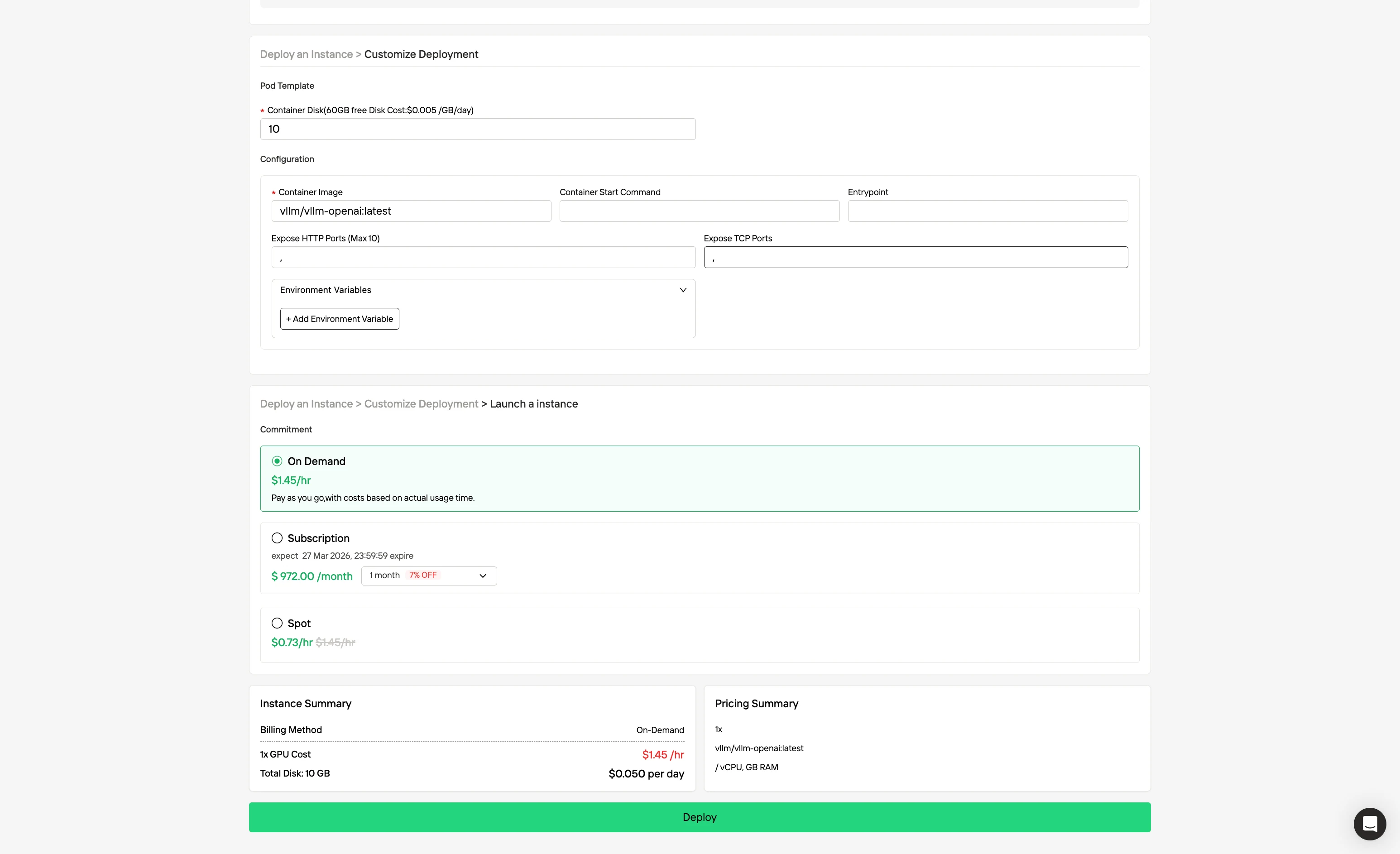
Schritt 3: Passen Sie Ihre Bereitstellung an Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten.
Probieren Sie kostengünstige GPUs aus!
Die 229B MoE-Architektur von MiniMax M2.5 ermöglicht erstklassige Coding-Leistung, erfordert aber mindestens 96 GB VRAM für 2-Bit-Quantisierung oder 128–160 GB für produktionsreife 3–4-Bit-Bereitstellungen. Für die meisten Entwickler bietet die API-Bereitstellung für 0,30 $/1,20 $ pro 1M Token das beste Verhältnis von Kosten, Leistung und Einfachheit bis zu 50M Token/Monat.
Häufig gestellte Fragen
Kann ich MiniMax M2.5 auf einer einzelnen RTX 4090 ausführen? Nein, MiniMax M2.5 erfordert mindestens 74 GB VRAM selbst bei der aggressivsten UD-IQ2_XXS 2-Bit-Quantisierung. Eine einzelne RTX 4090 hat nur 24 GB VRAM. Sie benötigen mindestens 3–4 Consumer-GPUs oder 2×H100.
Welche Quantisierungsstufe liefert produktionsreife Ausgaben für MiniMax M2.5? Q4_K_M (138 GB) oder Dynamic 3-bit Q3_K_M (109 GB) bieten die beste Balance. Vermeiden Sie Q2_K (83 GB) für den Produktivbetrieb – Reddit-Nutzer berichten von spürbaren Einbußen bei der Coding-Qualität trotz höherer Kontextkapazität.
Wie funktioniert die MiniMax M2.5 API-Preisgestaltung? Bei Novitas Tarif von 0,30 $/1,20 $ pro 1M Token kostet die Verarbeitung von 1M Token pro Tag ca. 45 $/Monat über die API.
Novita AI ist eine KI- & Agenten-Cloud-Plattform, die Entwicklern und Startups hilft, Modelle und agentische Anwendungen mit hoher Leistung, Zuverlässigkeit und Kosteneffizienz zu erstellen, bereitzustellen und zu skalieren.
Empfohlene Lektüre



