

MiniMax M2.5 可以在消费级硬件上运行——但前提是采用激进的量化方案。 借助 Unsloth AI 的动态 3 位 GGUF 量化,你可以将完整精度的 457GB 模型压缩至约 101GB。本指南将分解不同量化等级下的实际 VRAM 需求,并将其映射到特定 GPU 配置及 Novita AI 云定价。
MiniMax M2.5 简介
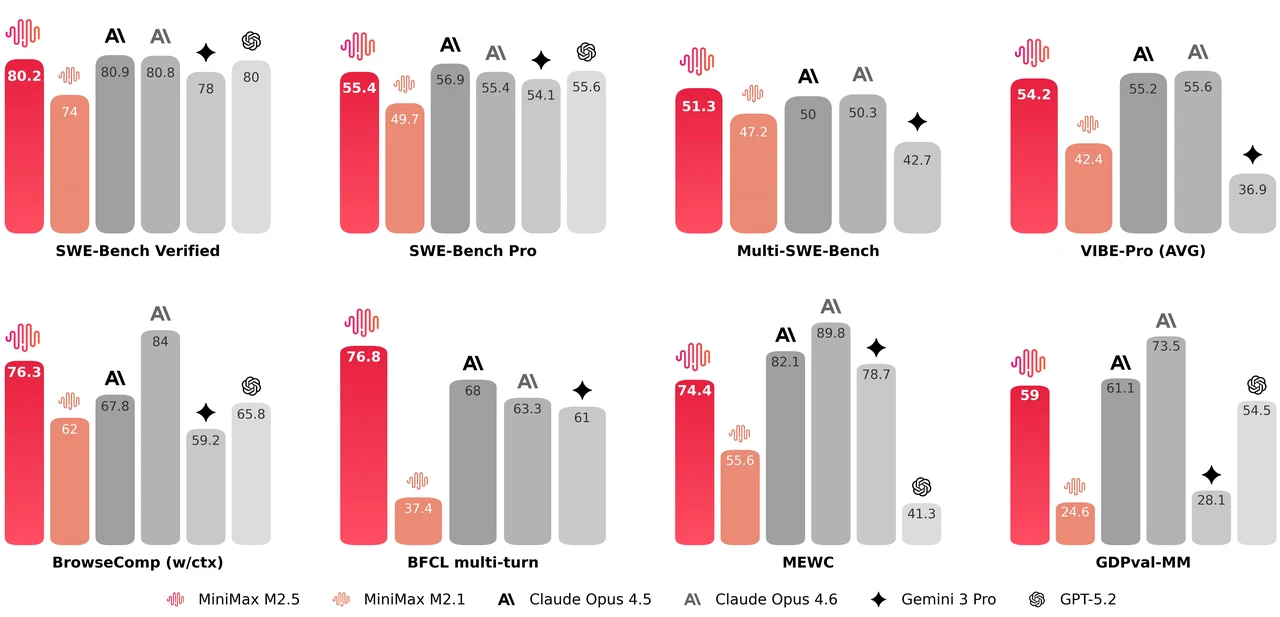
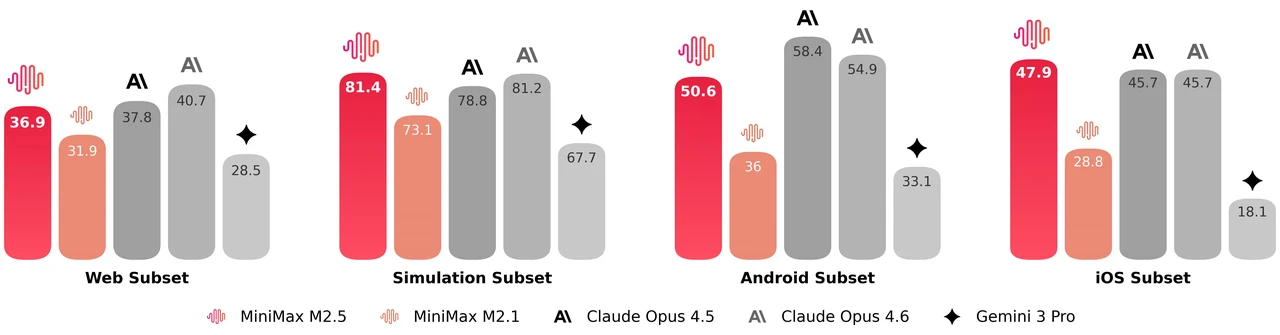
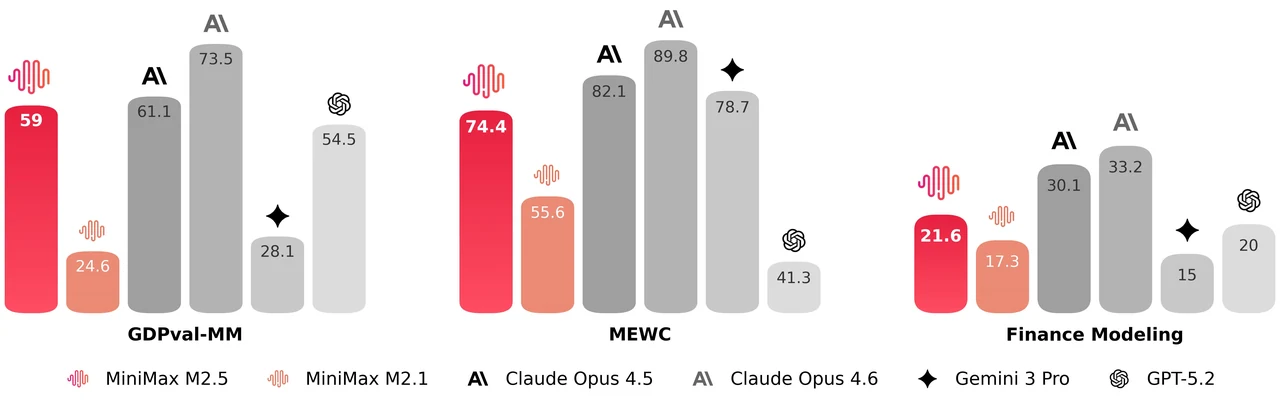
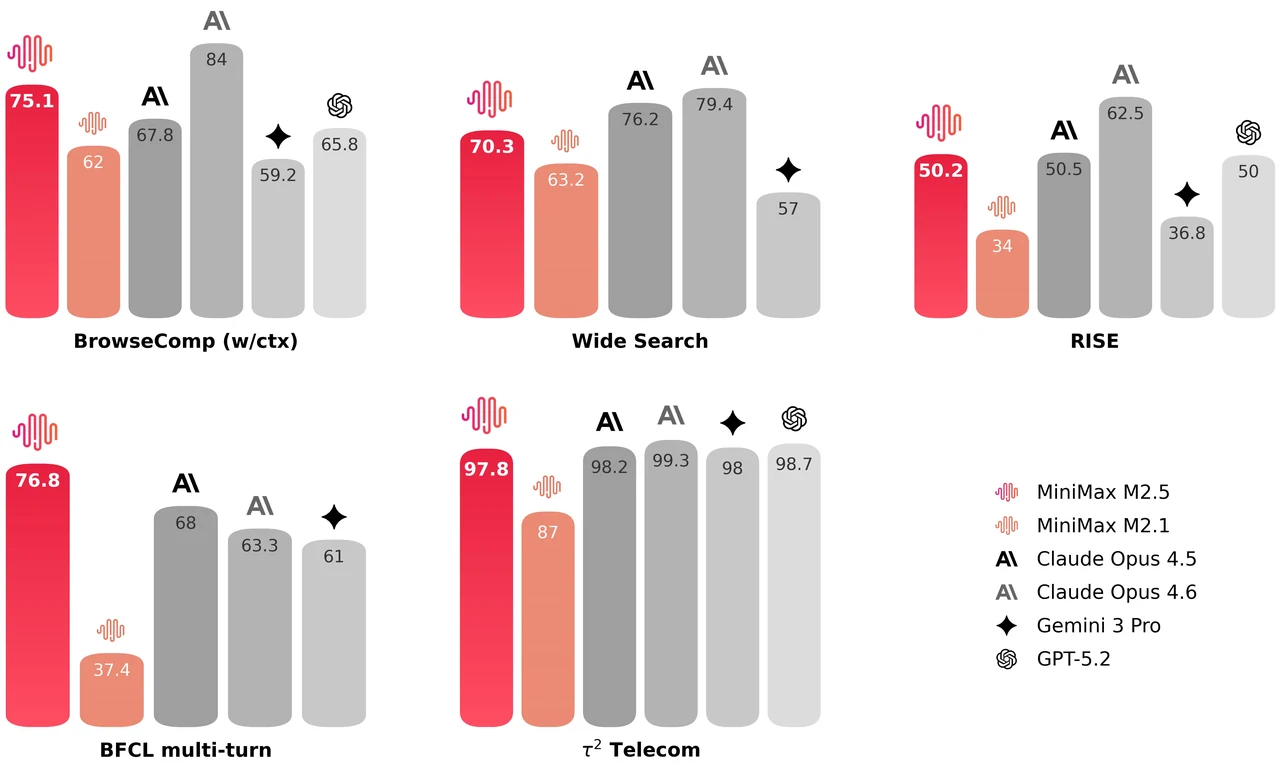
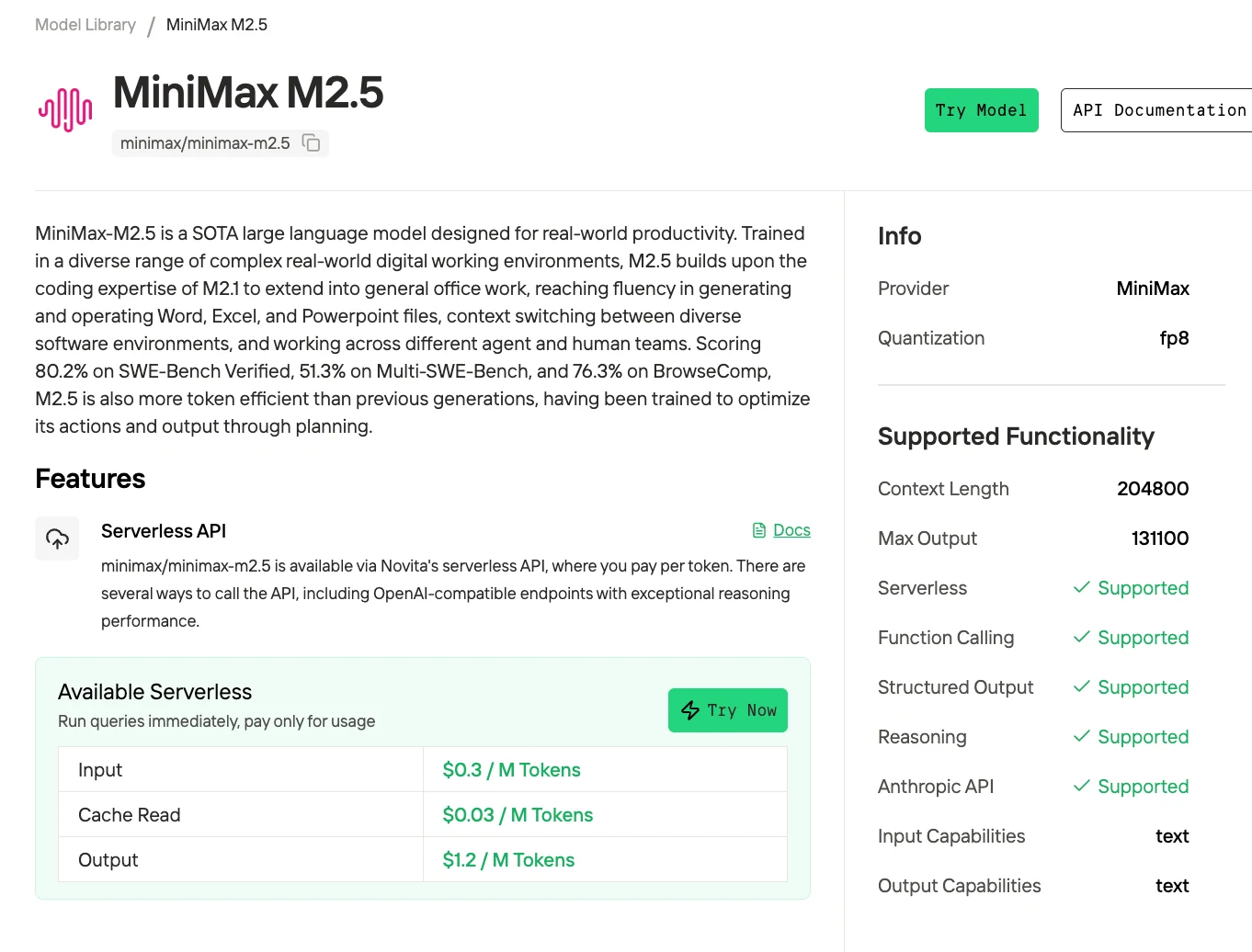
MiniMax M2.5 是一个 229B 参数的混合专家模型,拥有 256 个专家层,每 token 激活 8 个专家(约 10B 参数)。它在 SWE-Bench Verified 上达到 80.2%,Multi-SWE-Bench 上达到 51.3%,BrowseComp 上达到 76.3%,是面向智能体编程和工具使用的顶级开源模型之一。该模型支持 205K token 上下文窗口,并采用 MIT 许可证,可无限制用于商业用途。
来自 Huggingface
来自 Huggingface
来自 Huggingface
MiniMax M2.5 的 VRAM 需求
VRAM 需求随精度等级变化。下表列出了 Unsloth 的 GGUF 量化和混合 AWQ 格式的文件大小——根据上下文长度和批处理大小,还需要额外预留 4-10 GB 用于 KV 缓存。
| 配置 | 所需 VRAM |
|---|---|
| BF16(完整精度) | 457 GB |
| Q8_0 GGUF | 243 GB |
| Q6_K GGUF | 188 GB |
| Q4_K_M GGUF | 138 GB |
| IQ4_XS GGUF | 122 GB |
| Q3_K_M GGUF(动态 3 位) | 109 GB |
| Q2_K GGUF | 83 GB |
| UD-IQ2_XXS GGUF(超动态 2 位) | 74 GB |
通过混合量化方案(INT4 AWQ 权重、FP8 注意力以及校准后的 FP8 KV 缓存),MiniMax M2.5 可在 192GB VRAM 下达到 370K 上下文,并能实现比标准 AWQ 高得多的批处理吞吐量——标准 AWQ 通常受限于 KV 缓存。
MiniMax M2.5 的 GPU 推荐
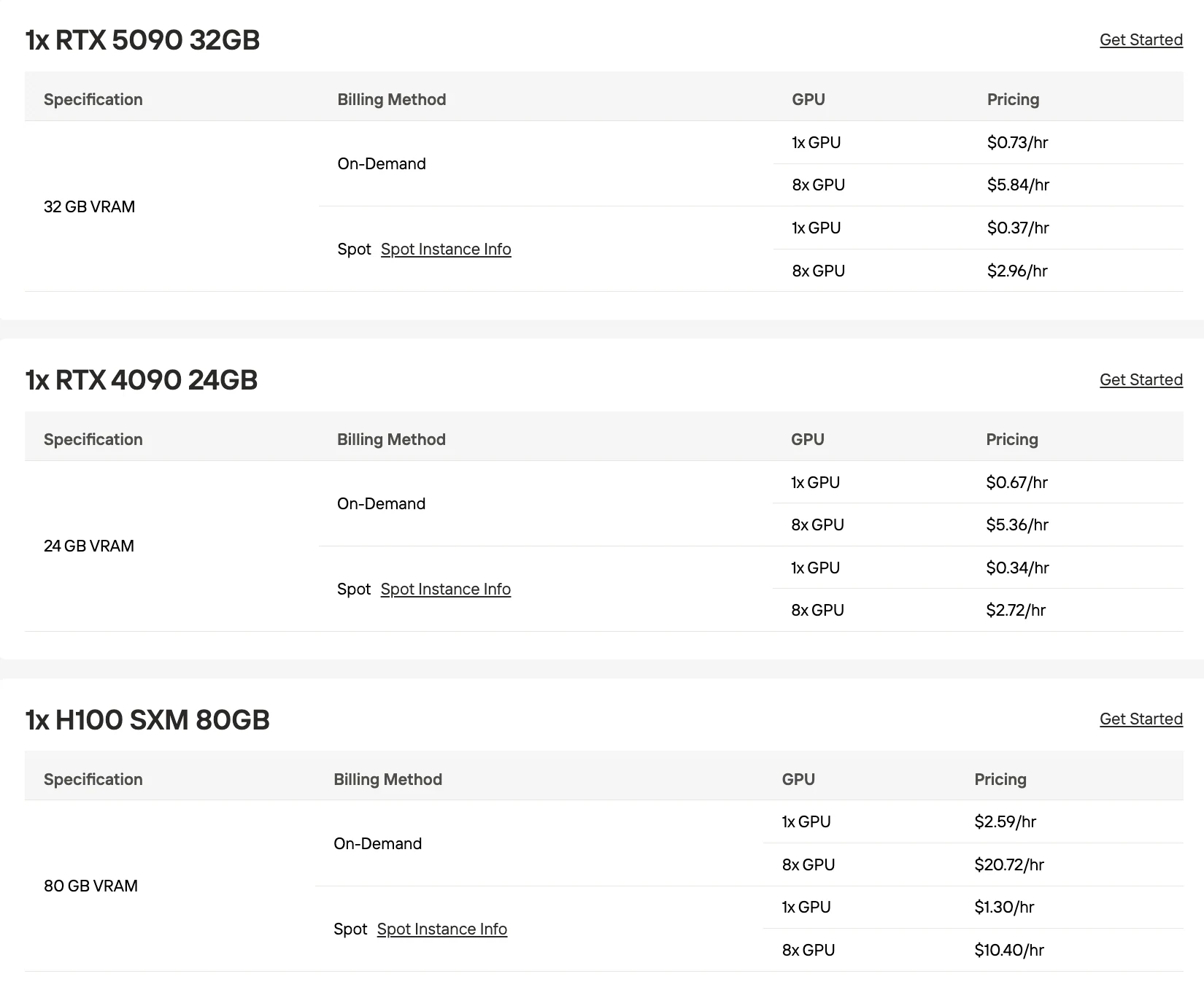
以下定价均采用 Novita AI 按需费率。多 GPU 成本按单 GPU 价格 × 数量计算。
RTX 5090(32GB)
| 配置 | 总 VRAM | 量化方案 | 备注 |
|---|---|---|---|
| 3× RTX 5090 | 96GB | Q2_K | 可用但接近内存极限 |
| 4× RTX 5090 | 128GB | Q3_K_M 动态 3 位 | 中等批处理下稳定运行 |
H100(80GB)
| 配置 | 总 VRAM | 量化方案 | 备注 |
|---|---|---|---|
| 2× H100 | 160GB | Q4_K_M | 稳定部署,模型质量更高 |
不推荐: 单张 RTX 4090 或 RTX 5090 即使采用最激进的量化也无法容纳 MiniMax M2.5。Strix Halo APU 搭配 Q3_K_M 的速度“几乎不可用”,虽能处理 80K 上下文,但推理速度不切实际。
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
实际部署策略
策略一:API 优先 + 竞价 GPU 故障转移
开发和轻量生产阶段使用 Novita AI API,每百万 token 价格约 $0.30/$1.20。当流量超过每月约 1 亿 token(API 成本约 $150/月)时,启动 2×H100 的竞价实例($5.18/hr)用于批量处理作业,同时保留 API 用于实时面向用户的推理。这种混合架构既能控制成本,又能保持交互式使用的低延迟。
为进一步降低大规模应用的成本,Novita 在 API 定价基础上还提供折扣的提示缓存读取。当提示被复用(如系统指令、模板或重复上下文)时,缓存的 token 将以更低费率提供服务,无需重新计算——从而同时降低延迟和成本。这使得“API 优先 + 批处理”架构更加高效,尤其适用于智能体工作流和高频查询场景。
策略二:量化自托管
对于有隐私需求或高负载持续工作负载的团队,可在 2×H100 上部署 Q3_K_M 动态 3 位或 Q4_K_M 量化方案。使用 llama.cpp 处理 GGUF 格式,或使用 vLLM 配合 AWQ 实现生产级吞吐优化。
如何在云 GPU 上访问 MiniMax M2.5?
第一步:注册账户
通过我们的网站创建 Novita AI 账户。注册后,在左侧边栏导航至“探索”部分,查看我们的 GPU 产品,开启 AI 开发之旅。

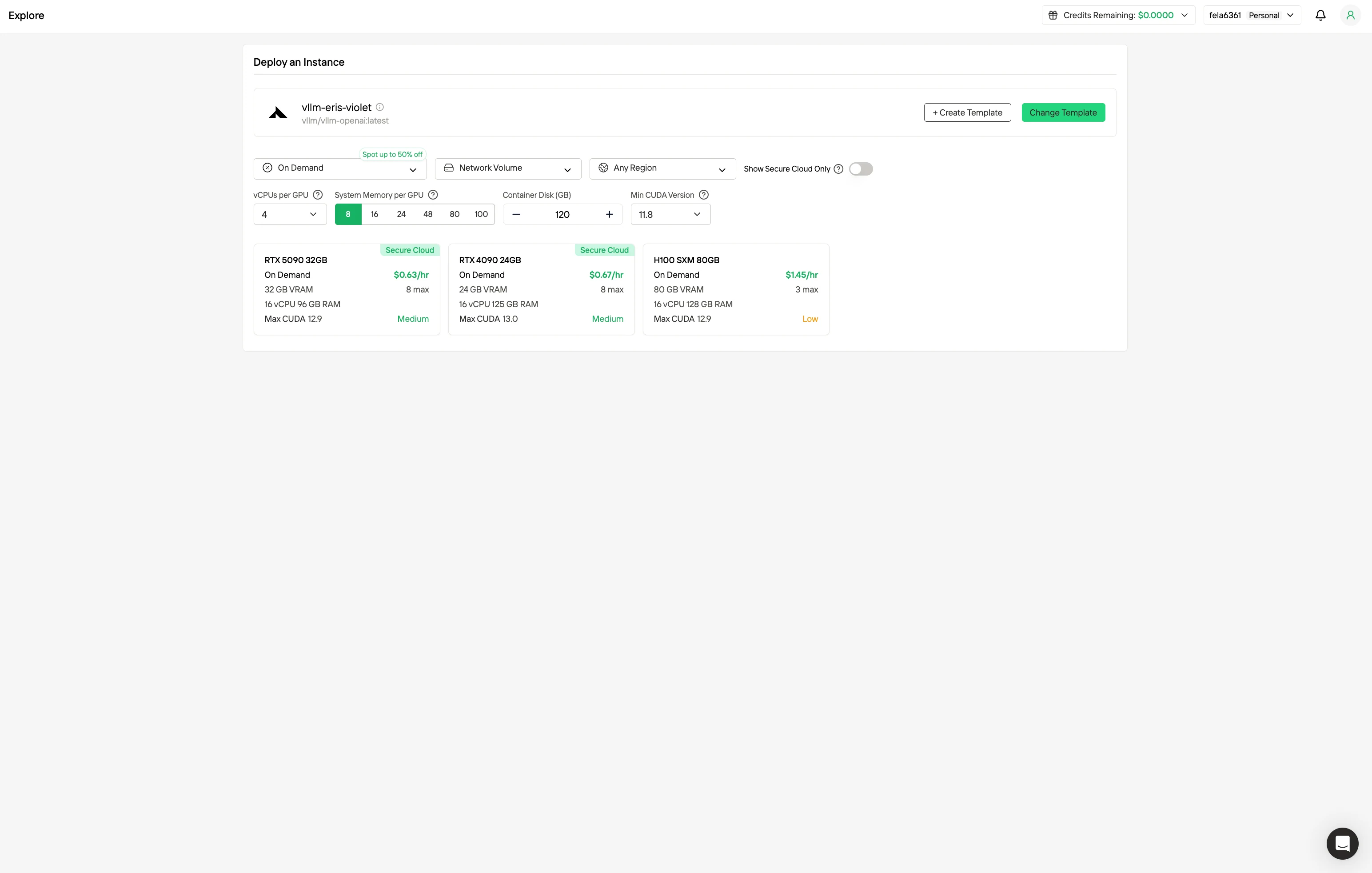
第二步:探索模板与 GPU 服务器
选择符合项目需求的模板(如 PyTorch、TensorFlow 或 CUDA)。然后选择你偏好的 GPU 配置——选项包括强大的 GPU,各自具有不同的 VRAM、内存和存储规格。
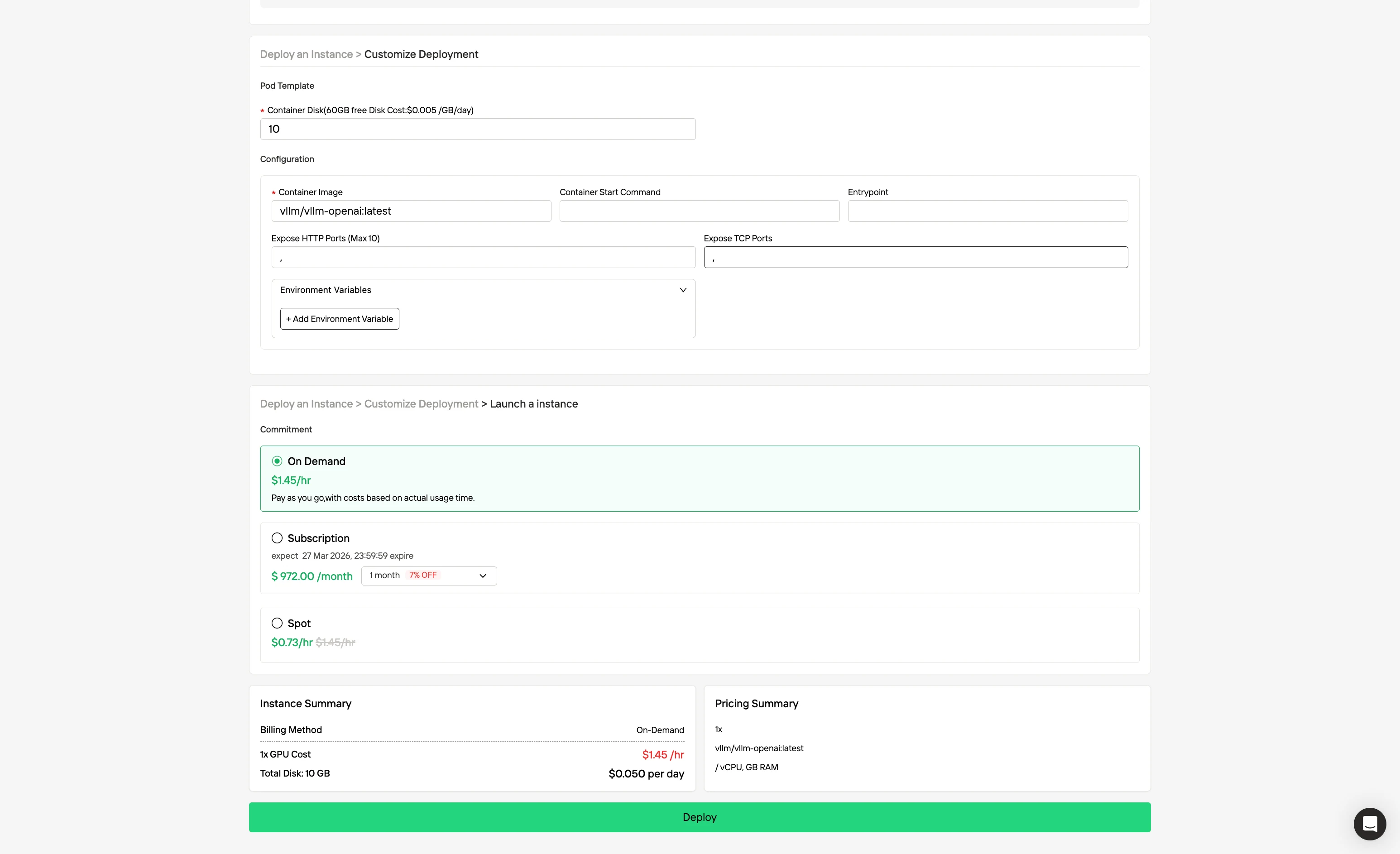
第三步:定制部署
通过选择偏好的操作系统和配置选项来自定义环境,确保针对特定 AI 工作负载和开发需求达到最佳性能。
MiniMax M2.5 的 229B MoE 架构带来了顶尖的编程性能,但至少需要 96GB VRAM 来实现 2 位量化,或 128-160GB 用于生产级的 3-4 位部署。对于大多数开发者而言,API 部署(每百万 token $0.30/$1.20)在每月 5000 万 token 以下提供了最佳的成本、性能与简单性平衡。
常见问题
我能在单张 RTX 4090 上运行 MiniMax M2.5 吗?
不能。即使采用最激进的 UD-IQ2_XXS 2 位量化,MiniMax M2.5 也至少需要 74GB VRAM。单张 RTX 4090 仅有 24GB VRAM。你至少需要 3-4 张消费级 GPU 或 2 张 H100。
哪种量化等级能保持 MiniMax M2.5 的生产级输出质量?
Q4_K_M(138GB)或动态 3 位 Q3_K_M(109GB)是平衡最佳选择。避免在生产环境中使用 Q2_K(83GB)——Reddit 用户报告尽管上下文容量更高,但编码质量有明显下降。
MiniMax M2.5 API 定价如何运作?
按 Novita 每百万 token $0.30/$1.20 计算,每天处理 100 万 token 的 API 成本约为 每月 $45。
Novita AI 是一个 AI 及智能体云平台,帮助开发者和初创企业构建、部署和扩展模型及智能体应用,具备高性能、可靠性和成本效益。
推荐阅读



