

MiniMax M2.5 peut fonctionner sur du matériel grand public — mais seulement avec une quantification agressive. Avec la quantification dynamique 3-bit GGUF d’Unsloth AI, vous pouvez réduire le modèle pleine précision de 457 Go à environ 101 Go. Ce guide détaille les exigences réelles en VRAM selon les niveaux de quantification, et les associe à des configurations GPU spécifiques avec les tarifs cloud de Novita AI.
Introduction à MiniMax M2.5
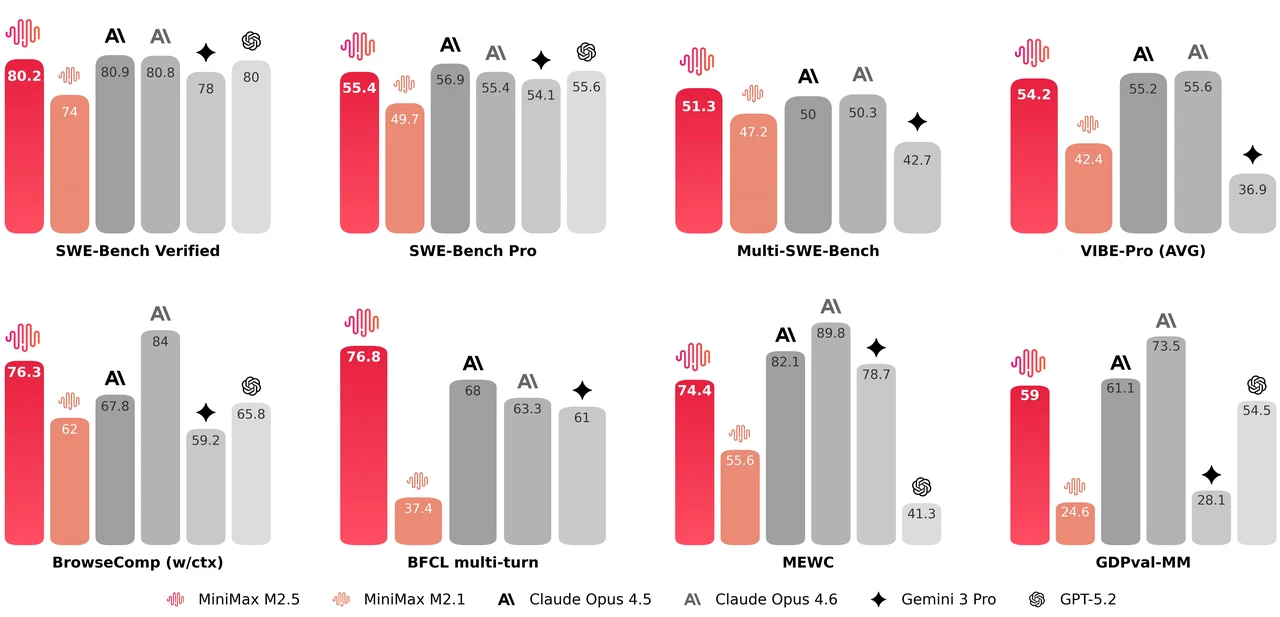
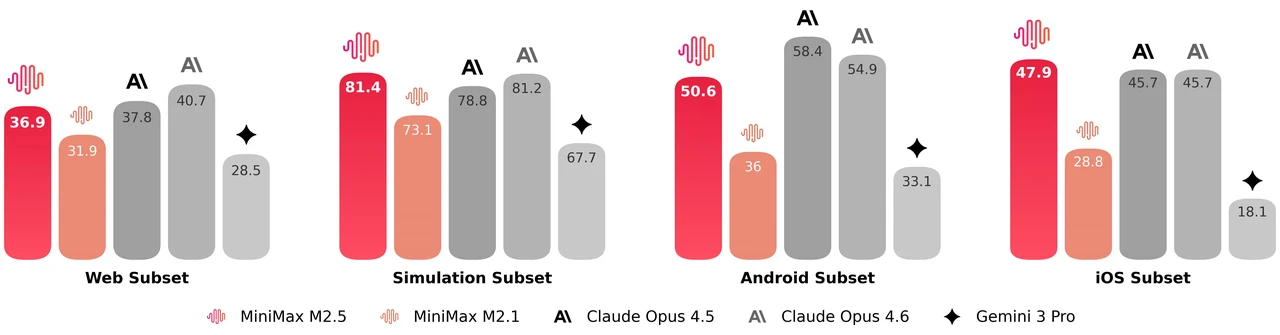
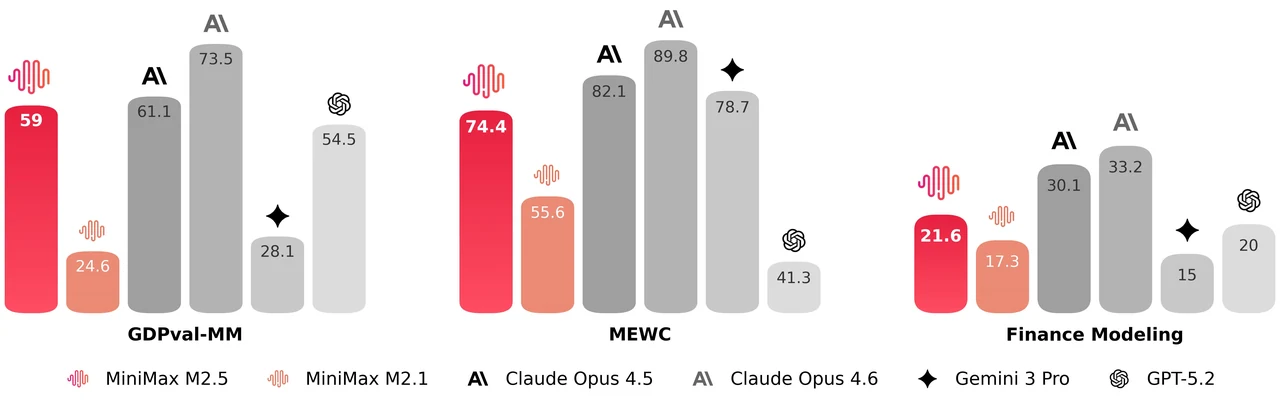
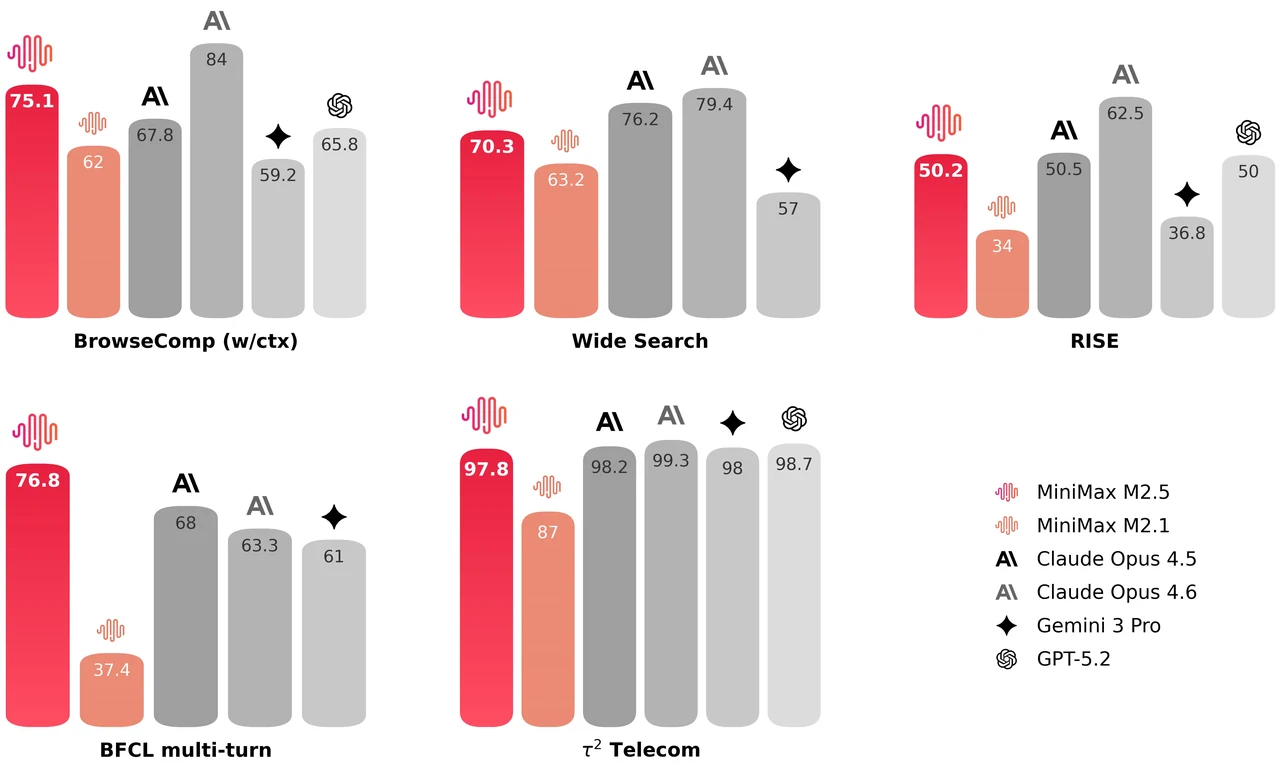
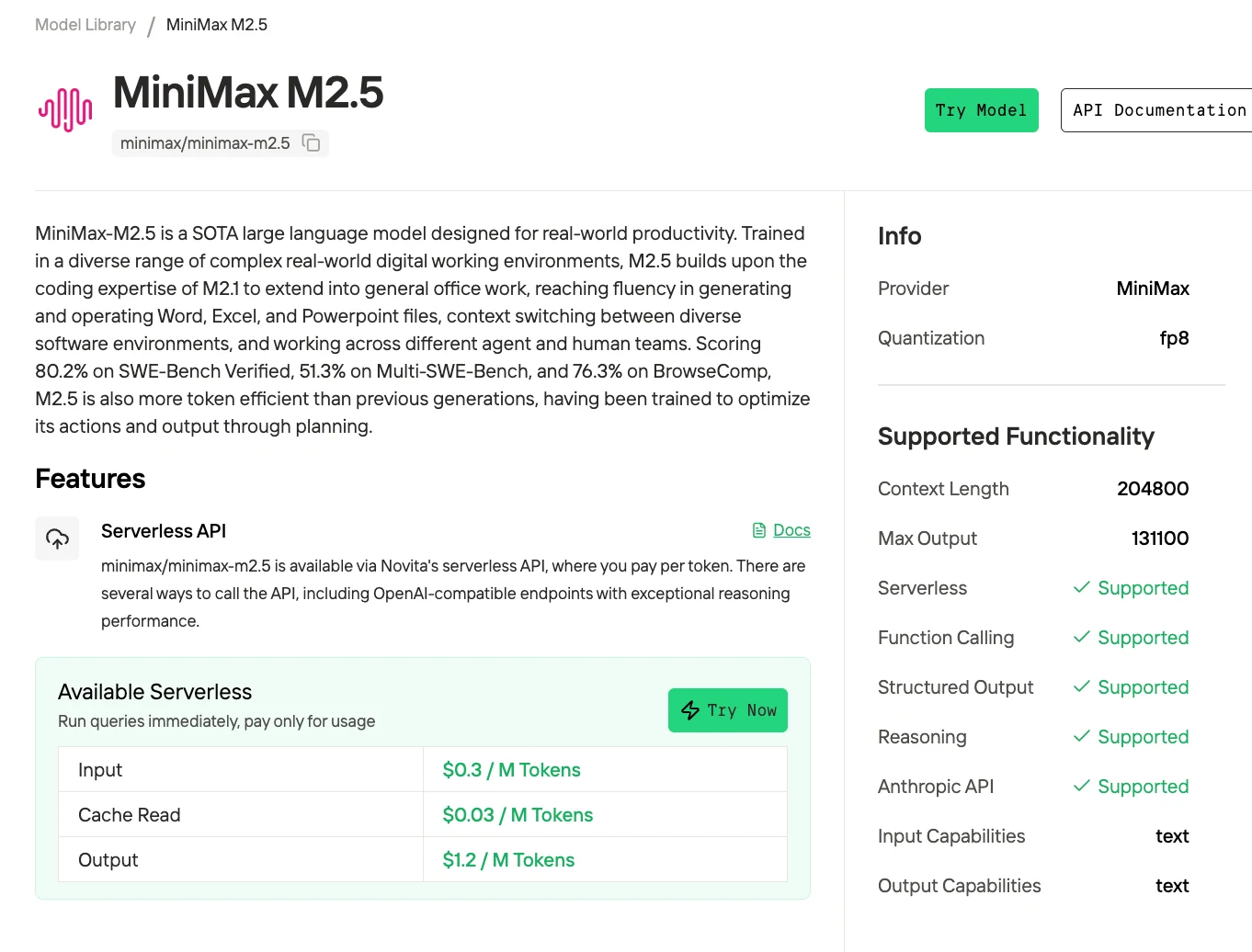
MiniMax M2.5 est un modèle mixture-of-experts (MoE) de 229 milliards de paramètres, avec 256 couches d’experts, activant 8 experts (environ 10 milliards de paramètres) par token. Il obtient 80,2 % sur SWE-Bench Verified, 51,3 % sur Multi-SWE-Bench et 76,3 % sur BrowseComp, ce qui en fait l’un des modèles open source les plus performants pour le codage agentique et l’utilisation d’outils. Le modèle prend en charge une fenêtre de contexte de 205 000 tokens et est sous licence MIT pour une utilisation commerciale libre.
De Huggingface
De Huggingface
De Huggingface
Exigences en VRAM pour MiniMax M2.5
Les besoins en VRAM évoluent selon le niveau de précision. Le tableau ci-dessous présente les tailles de fichiers des quantifications GGUF d’Unsloth et des formats hybrides AWQ — ajoutez 4 à 10 Go d’overhead pour le cache KV selon la longueur de contexte et la taille de batch.
| Configuration | VRAM requise |
|---|---|
| BF16 (pleine précision) | 457 Go |
| Q8_0 GGUF | 243 Go |
| Q6_K GGUF | 188 Go |
| Q4_K_M GGUF | 138 Go |
| IQ4_XS GGUF | 122 Go |
| Q3_K_M GGUF (quantification dynamique 3-bit) | 109 Go |
| Q2_K GGUF | 83 Go |
| UD-IQ2_XXS GGUF (quantification dynamique ultra 2-bit) | 74 Go |
Avec un schéma de quantification hybride (poids INT4 AWQ, attention FP8 et cache KV FP8 calibré), MiniMax M2.5 peut atteindre un contexte de 370K tokens sur 192 Go de VRAM et permettre un débit de traitement par batch significativement plus élevé que l’AWQ standard, qui est généralement limité par le cache KV.
Recommandations de GPU pour MiniMax M2.5
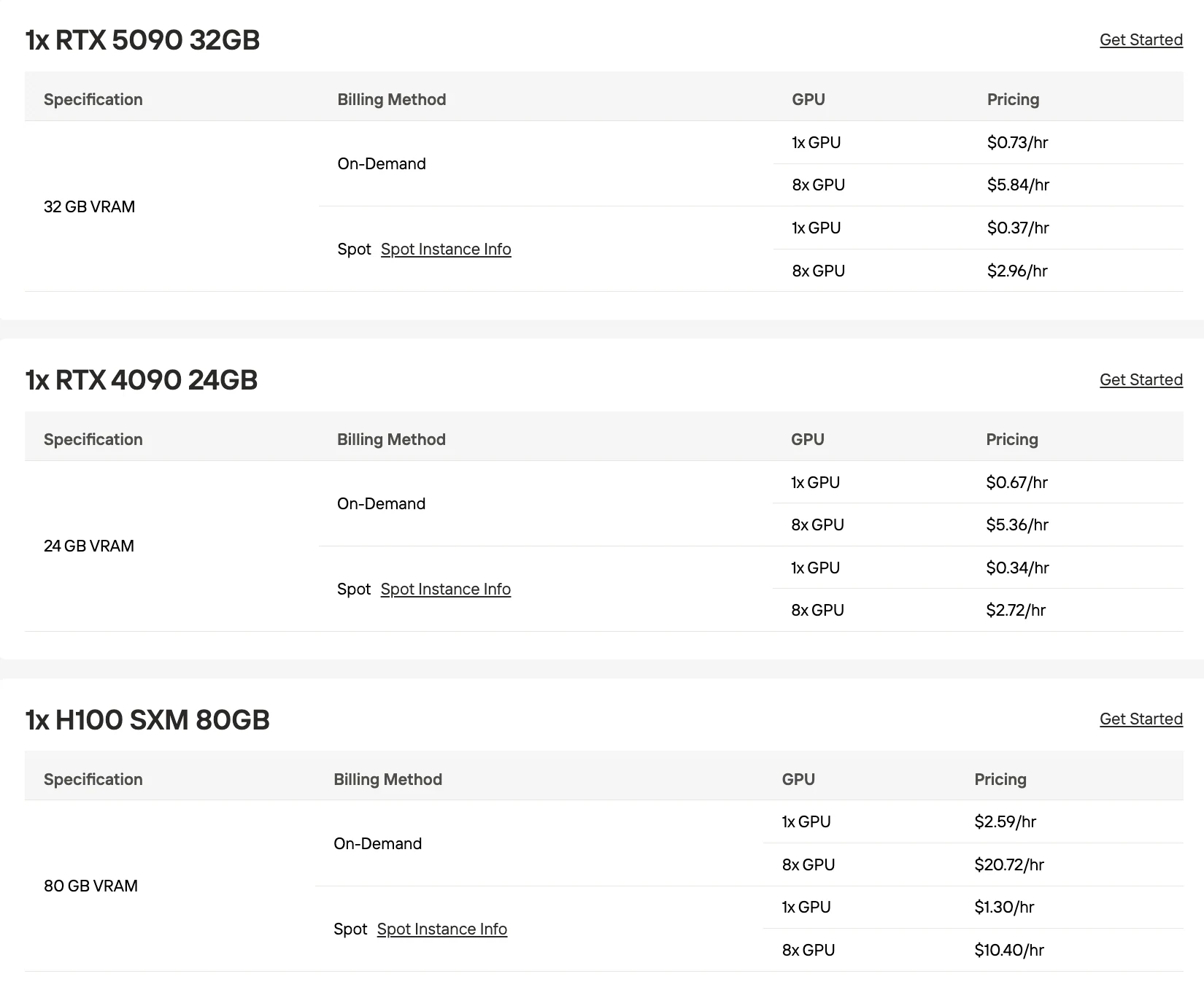
Tous les tarifs ci-dessous correspondent aux tarifs à la demande de Novita AI. Les coûts multi-GPU sont calculés comme le prix d’un GPU unique multiplié par le nombre de GPU.
RTX 5090 (32 Go)
| Configuration | VRAM totale | Quantification | Notes |
|---|---|---|---|
| 3× RTX 5090 | 96 Go | Q2_K | Fonctionne mais sollicite les limites de la mémoire |
| 4× RTX 5090 | 128 Go | Q3_K_M quantification dynamique 3-bit | Stable avec un traitement par batch modéré |
H100 (80 Go)
| Configuration | VRAM totale | Quantification | Notes |
|---|---|---|---|
| 2× H100 | 160 Go | Q4_K_M | Déploiement stable avec une qualité de modèle plus élevée |
Non recommandé : Une RTX 4090 ou RTX 5090 unique ne peut pas faire fonctionner MiniMax M2.5 même avec les quantifications les plus agressives. L’APU Strix Halo avec Q3_K_M donne des vitesses “presque inutilisables”, prenant en charge un contexte de 80K tokens mais à des vitesses d’inférence impraticables.
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
Stratégies de déploiement pratiques
Stratégie 1 : Priorité à l’API avec basculement sur des GPU spot
Commencez par l’API Novita AI à 0,30 $ / 1,20 $ par million de tokens pour le développement et la production légère. Lorsque le trafic dépasse environ 100 millions de tokens par mois (soit 150 $/mois de coût d’API), déployez des instances spot de 2×H100 à 5,18 $/h pour les tâches de traitement par batch, en conservant l’API pour les inférences en temps réel destinées aux utilisateurs. Cette approche hybride limite les coûts tout en maintenant une faible latence pour les usages interactifs.
Pour réduire encore les coûts à grande échelle, Novita propose des tarifs d’API bas ainsi que des lectures de cache de prompts à prix réduit. Lorsque les prompts sont réutilisés (par exemple, instructions système, modèles ou contexte répété), les tokens mis en cache sont servis à un tarif inférieur au lieu d’être recalculés — ce qui réduit à la fois la latence et le coût. Cela rend l’architecture priorité API + traitement par batch encore plus efficace, notamment pour les flux de travail agentiques et les requêtes à haute fréquence.
Essayez MiniMax M2.5 dès maintenant !
Stratégie 2 : Auto-hébergement avec quantification
Pour les équipes ayant des exigences de confidentialité ou des charges de travail soutenues à haut volume, déployez la quantification Q3_K_M dynamique 3-bit ou Q4_K_M sur 2×H100. Utilisez llama.cpp pour les formats GGUF ou vLLM avec AWQ pour une optimisation du débit de production.
Comment accéder à MiniMax M2.5 sur un GPU cloud ?
Étape 1 : Créer un compte
Créez votre compte Novita AI via notre site web. Après inscription, rendez-vous dans la section “Explorer” dans la barre latérale gauche pour consulter nos offres GPU et commencer votre développement IA.

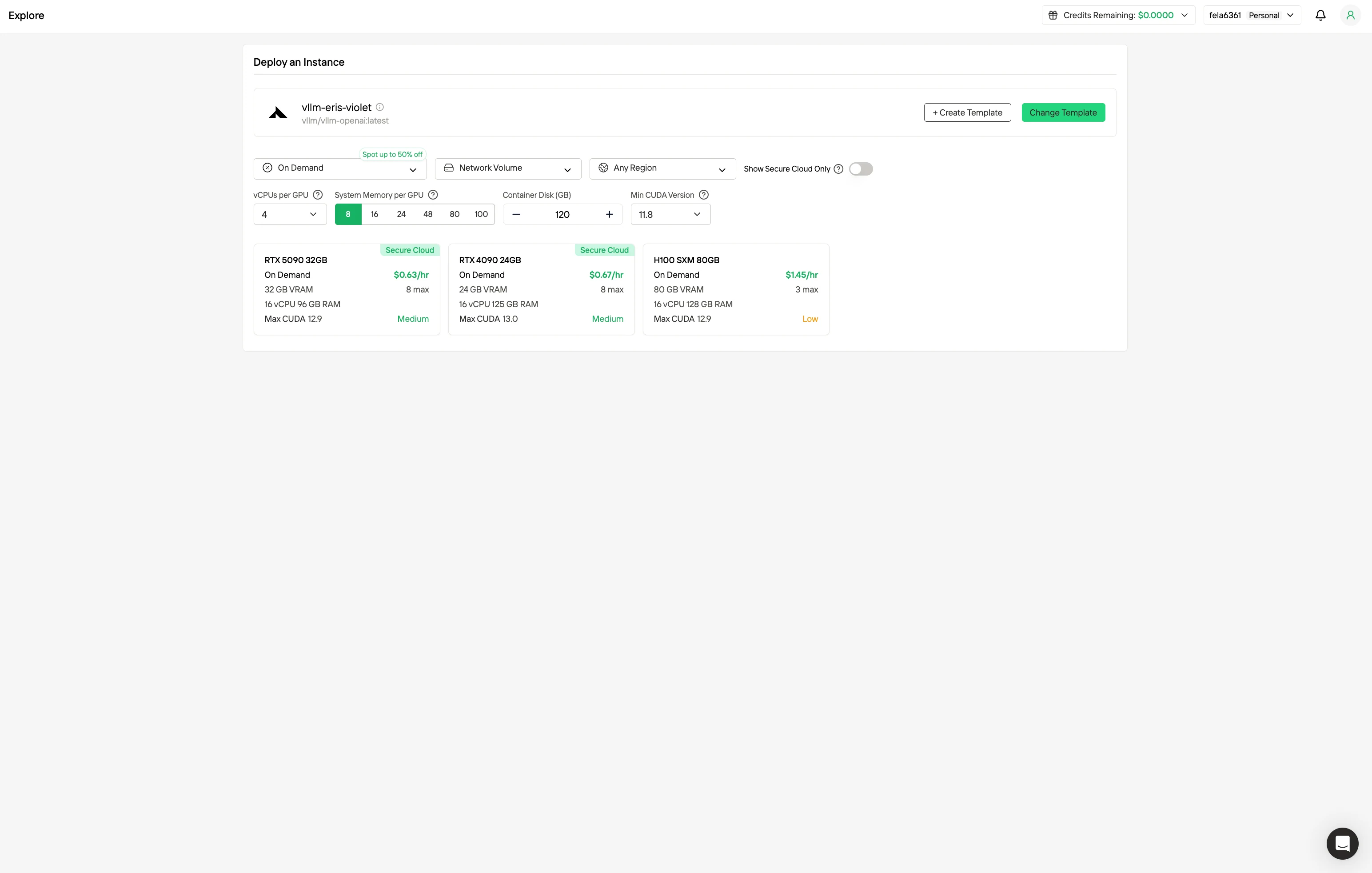
Étape 2 : Explorer les modèles et les serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA correspondant à vos besoins de projet. Sélectionnez ensuite votre configuration GPU préférée : les options incluent les GPU puissants, chacun avec des spécifications de VRAM, RAM et stockage différentes.
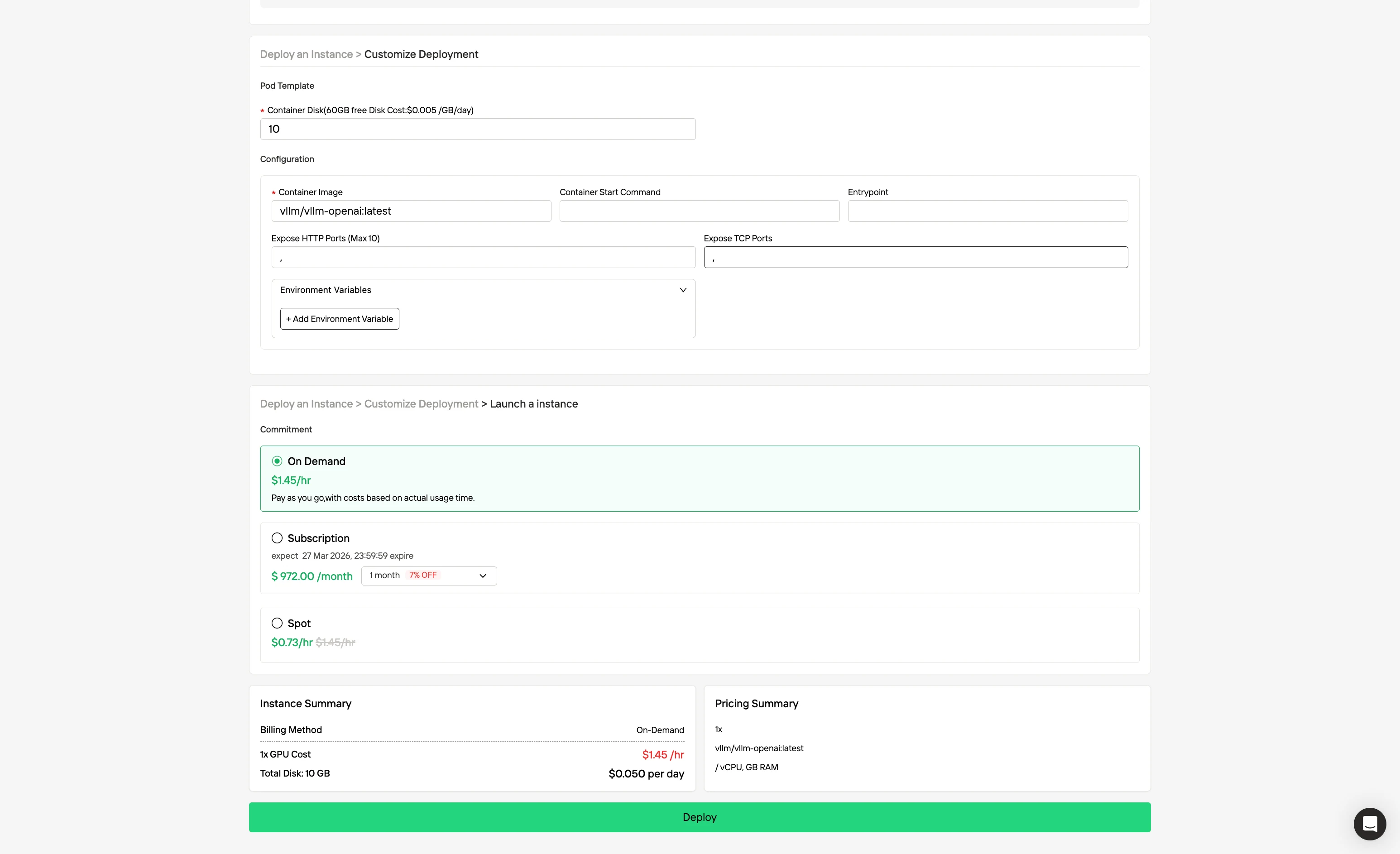
Étape 3 : Personnaliser votre déploiement
Personnalisez votre environnement en sélectionnant votre système d’exploitation et vos options de configuration préférés pour garantir des performances optimales pour vos charges de travail et besoins de développement IA spécifiques.
L’architecture MoE de 229 milliards de paramètres de MiniMax M2.5 permet des performances de codage de pointe, mais nécessite au minimum 96 Go de VRAM pour une quantification 2-bit, ou 128 à 160 Go pour des déploiements 3-4 bits de qualité production. Pour la plupart des développeurs, le déploiement via API à 0,30 $ / 1,20 $ par million de tokens offre le meilleur compromis coût-performance-simplicité jusqu’à 50 millions de tokens par mois.
Questions fréquentes
Puis-je faire fonctionner MiniMax M2.5 sur une seule RTX 4090 ?
Non, MiniMax M2.5 nécessite au minimum 74 Go de VRAM même avec la quantification 2-bit UD-IQ2_XXS la plus agressive. Une RTX 4090 unique ne dispose que de 24 Go de VRAM. Vous avez besoin d’au moins 3 à 4 GPU grand public ou de 2×H100.
Quel niveau de quantification permet d’obtenir des résultats de qualité production pour MiniMax M2.5 ?
Q4_K_M (138 Go) ou la quantification dynamique 3-bit Q3_K_M (109 Go) offrent le meilleur compromis. Évitez Q2_K (83 Go) pour la production : des utilisateurs Reddit rapportent une dégradation notable de la qualité de codage malgré une capacité de contexte plus élevée.
Comment fonctionne la tarification de l’API MiniMax M2.5 ?
Avec les tarifs de Novita à 0,30 $ / 1,20 $ par million de tokens, le traitement de 1 million de tokens par jour coûte environ 45 $/mois via l’API.
Novita AI est une plateforme cloud IA et agentique qui aide les développeurs et les startups à créer, déployer et mettre à l’échelle des modèles et des applications agentiques avec des performances élevées, une fiabilité et une efficacité de coûts.
Lectures recommandées



