

MiniMax M2.5 se puede ejecutar en hardware de consumo, pero solo con cuantización agresiva. Con la cuantización GGUF Dinámica de 3 bits de Unsloth AI, puedes reducir el modelo de precisión completa de 457 GB a aproximadamente 101 GB. Esta guía desglosa los requisitos reales de VRAM según los niveles de cuantización y los mapea a configuraciones de GPU específicas con los precios en la nube de Novita AI.
Introducción a MiniMax M2.5
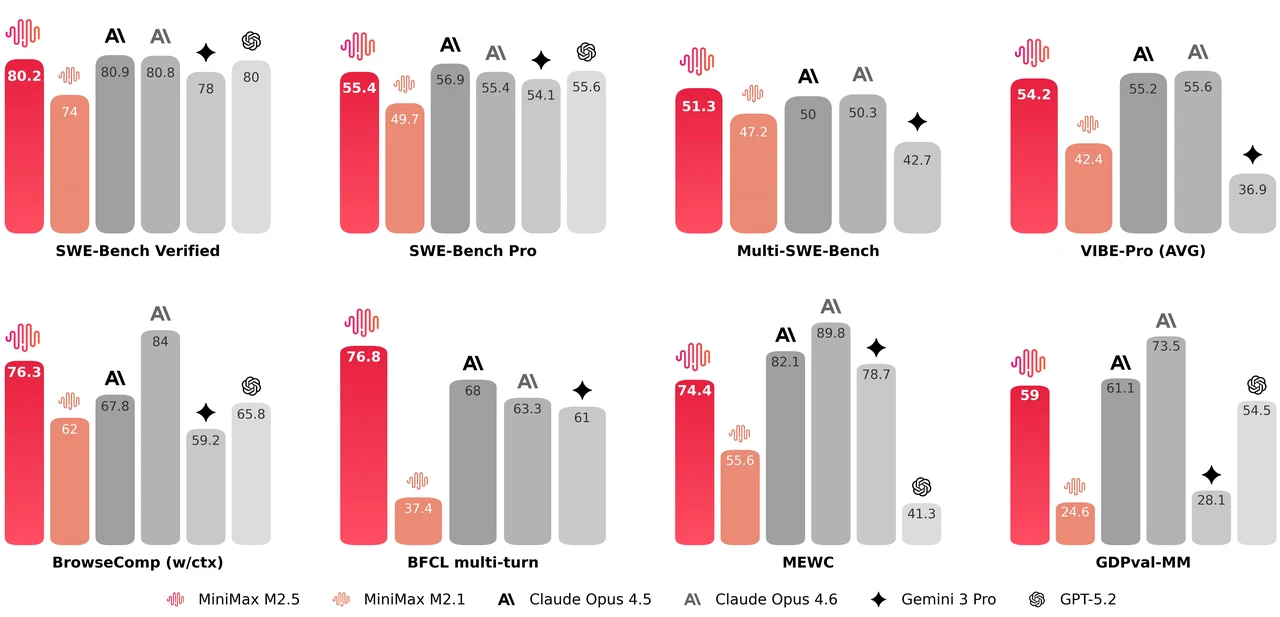
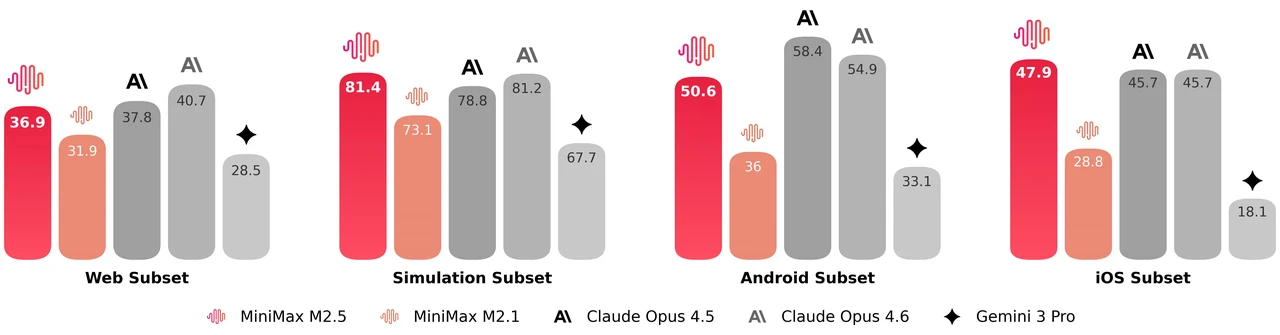
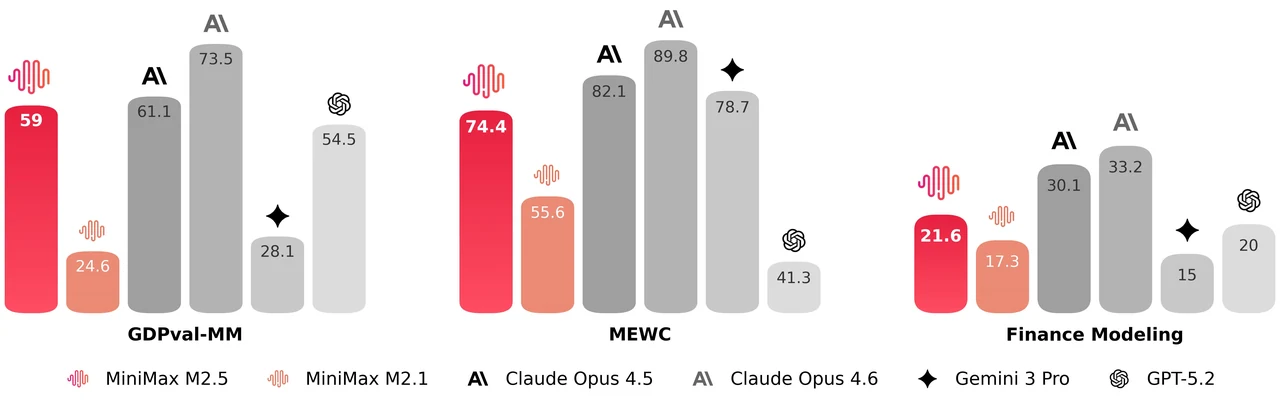
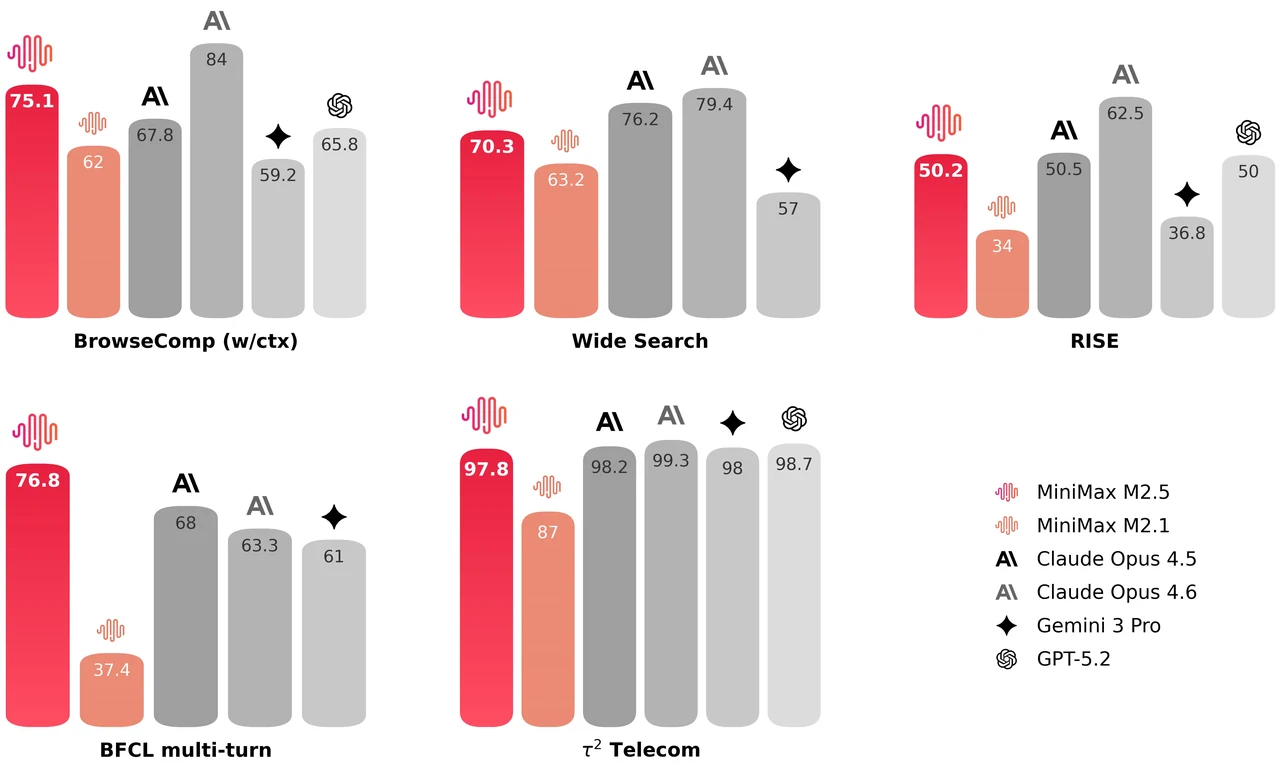
MiniMax M2.5 es un modelo de mezcla de expertos de 229B parámetros con 256 capas de expertos, activando 8 expertos (aproximadamente 10B parámetros) por token. Alcanza 80.2% en SWE-Bench Verified, 51.3% en Multi-SWE-Bench y 76.3% en BrowseComp, lo que lo convierte en uno de los modelos abiertos más potentes para codificación agente y uso de herramientas. El modelo admite una ventana de contexto de 205K tokens y tiene licencia MIT para uso comercial sin restricciones.
De Huggingface
De Huggingface
De Huggingface
Requisitos de VRAM de MiniMax M2.5
Las necesidades de VRAM escalan según el nivel de precisión. La tabla siguiente muestra los tamaños de archivo de las cuantizaciones GGUF de Unsloth y los formatos híbridos AWQ: añade de 4 a 10 GB de overhead para la caché KV según la longitud del contexto y el tamaño del lote.
| Configuración | VRAM requerida |
|---|---|
| BF16 (precisión completa) | 457 GB |
| Q8_0 GGUF | 243 GB |
| Q6_K GGUF | 188 GB |
| Q4_K_M GGUF | 138 GB |
| IQ4_XS GGUF | 122 GB |
| Q3_K_M GGUF (3 bits dinámicos) | 109 GB |
| Q2_K GGUF | 83 GB |
| UD-IQ2_XXS GGUF (2 bits ultra dinámicos) | 74 GB |
Con un esquema de cuantización híbrido (pesos INT4 AWQ, atención FP8 y caché KV calibrada en FP8), MiniMax M2.5 puede alcanzar 370K de contexto en 192 GB de VRAM y permitir un rendimiento de procesamiento por lotes significativamente mayor en comparación con AWQ estándar, que normalmente está limitado por la caché KV.
Recomendaciones de GPU para MiniMax M2.5
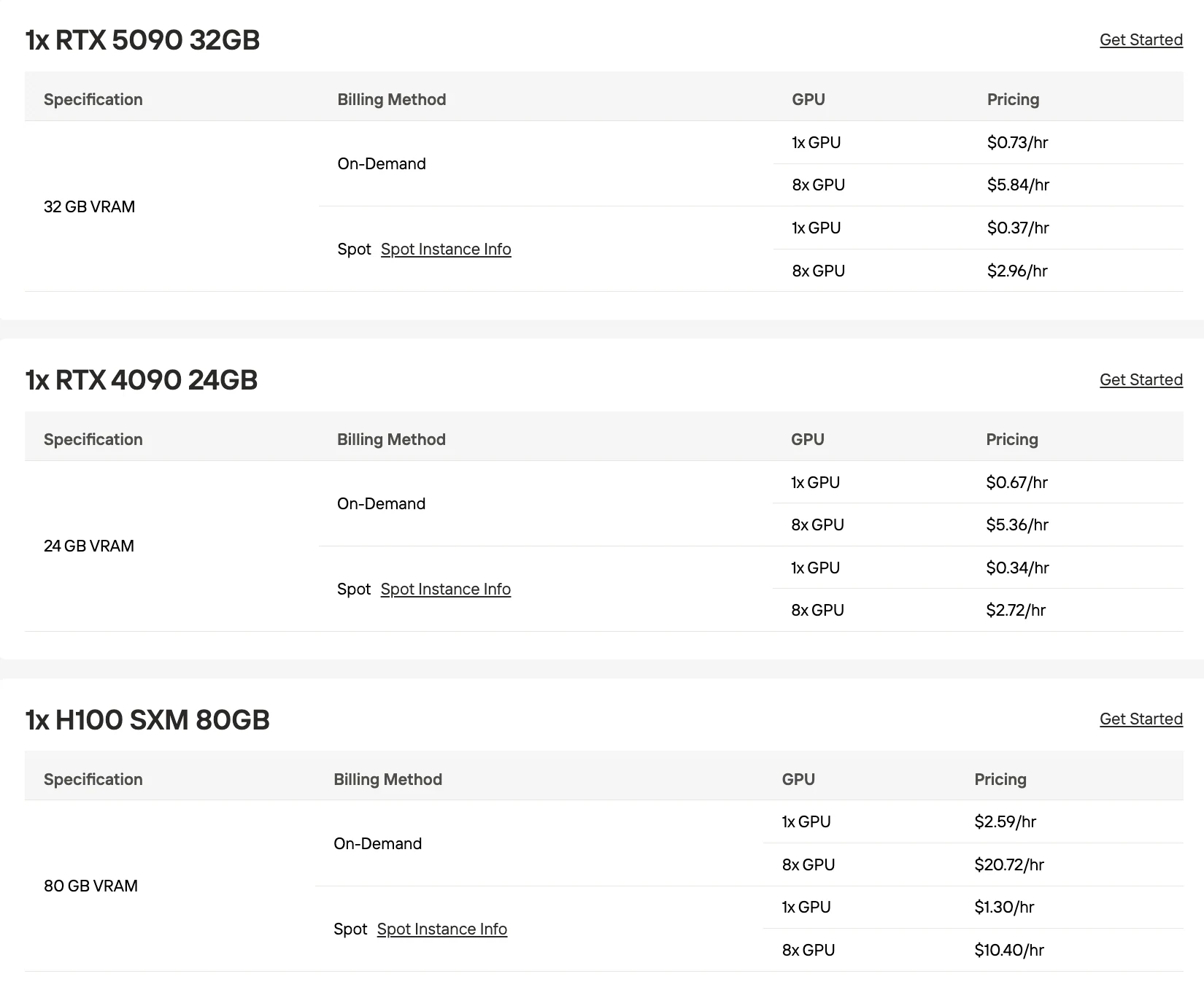
Todos los precios a continuación reflejan las tarifas bajo demanda de Novita AI. Los costos con múltiples GPU se calculan como precio de una GPU × cantidad.
RTX 5090 (32 GB)
| Configuración | VRAM total | Cuantización | Notas |
|---|---|---|---|
| 3× RTX 5090 | 96 GB | Q2_K | Funciona, pero al límite de memoria |
| 4× RTX 5090 | 128 GB | Q3_K_M 3 bits dinámicos | Estable con lotes moderados |
H100 (80 GB)
| Configuración | VRAM total | Cuantización | Notas |
|---|---|---|---|
| 2× H100 | 160 GB | Q4_K_M | Despliegue estable con mayor calidad de modelo |
No recomendado: Una sola RTX 4090 o RTX 5090 no puede alojar MiniMax M2.5 ni siquiera con las cuantizaciones más agresivas. La APU Strix Halo con Q3_K_M ofrece velocidades “casi inutilizables”, manejando 80K de contexto pero a velocidades de inferencia poco prácticas.
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
Estrategias prácticas de despliegue
Estrategia 1: API primero con failover de GPU spot
Comienza con la API de Novita AI a $0.30/$1.20 por 1M de tokens para desarrollo y producción ligera. Cuando el tráfico supere ~100M de tokens al mes ($150/mes en costo de API), levanta instancias spot de 2×H100 a $5.18/hora para trabajos de procesamiento por lotes, manteniendo la API para inferencia en tiempo real orientada al usuario. Este enfoque híbrido limita los costos mientras mantiene baja latencia para uso interactivo.
Para reducir aún más los costos a escala, Novita ofrece precios de API bajos junto con lecturas de caché de prompt con descuento. Cuando los prompts se reutilizan (por ejemplo, instrucciones del sistema, plantillas o contexto repetido), los tokens cacheados se sirven a una tarifa más baja en lugar de recalcularse, lo que reduce tanto la latencia como el costo. Esto hace que la arquitectura de API primero + procesamiento por lotes sea aún más eficiente, especialmente para flujos de trabajo agente y consultas de alta frecuencia.
Estrategia 2: Autoalojado con cuantización
Para equipos con requisitos de privacidad o cargas de trabajo sostenidas de alto volumen, despliega la cuantización Q3_K_M de 3 bits dinámicos o Q4_K_M en 2×H100. Usa llama.cpp para formatos GGUF o vLLM con AWQ para optimización de rendimiento a nivel de producción.
¿Cómo acceder a MiniMax M2.5 en GPU en la nube?
Paso 1: Registrarse
Crea tu cuenta de Novita AI a través de nuestro sitio web. Después del registro, navega a la sección “Explorar” en la barra lateral izquierda para ver nuestras ofertas de GPU y comenzar tu viaje en el desarrollo de IA.

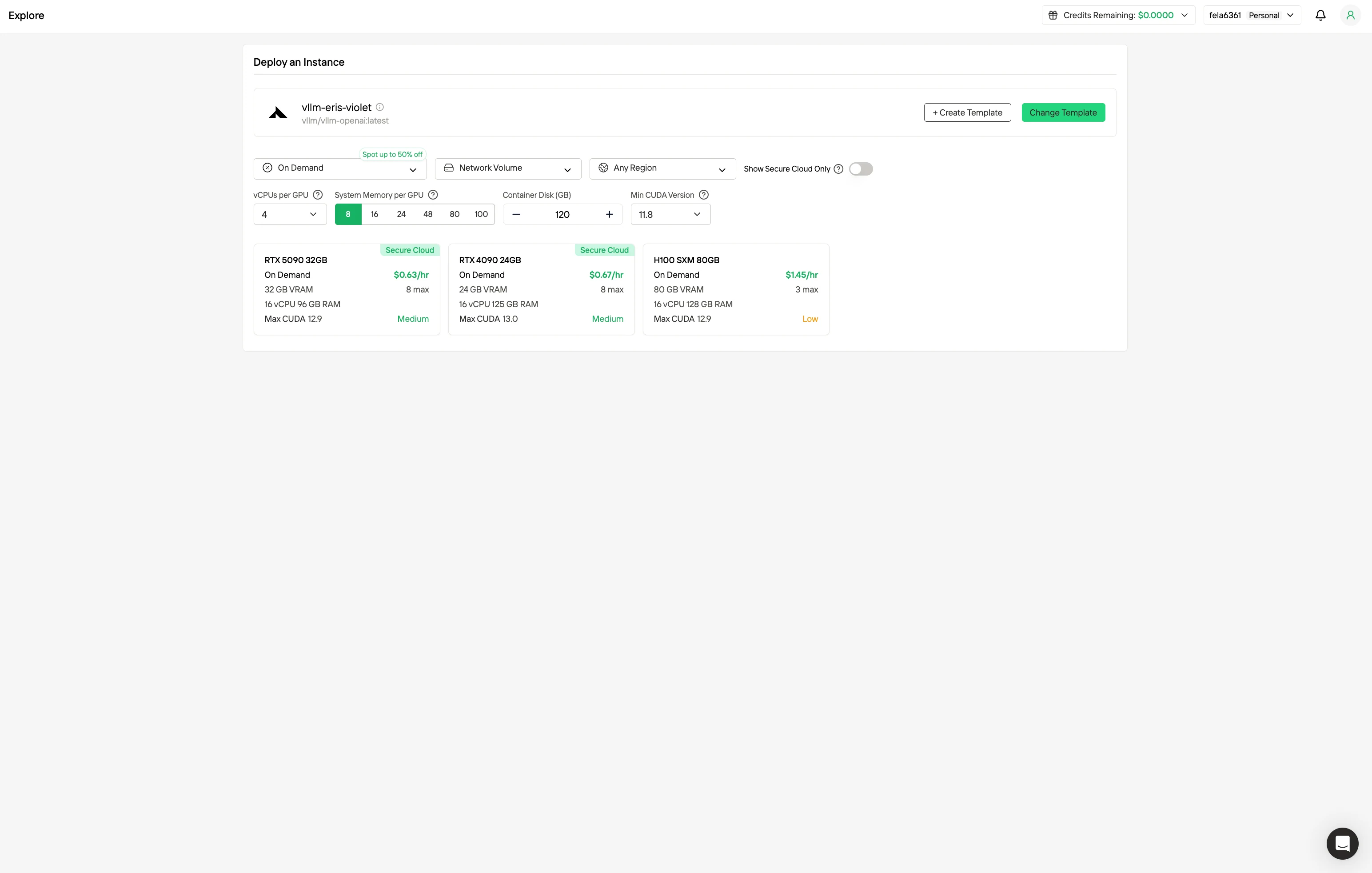
Paso 2: Explorar plantillas y servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se ajusten a las necesidades de tu proyecto. Luego selecciona la configuración de GPU que prefieras: las opciones incluyen la potente GPU, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.
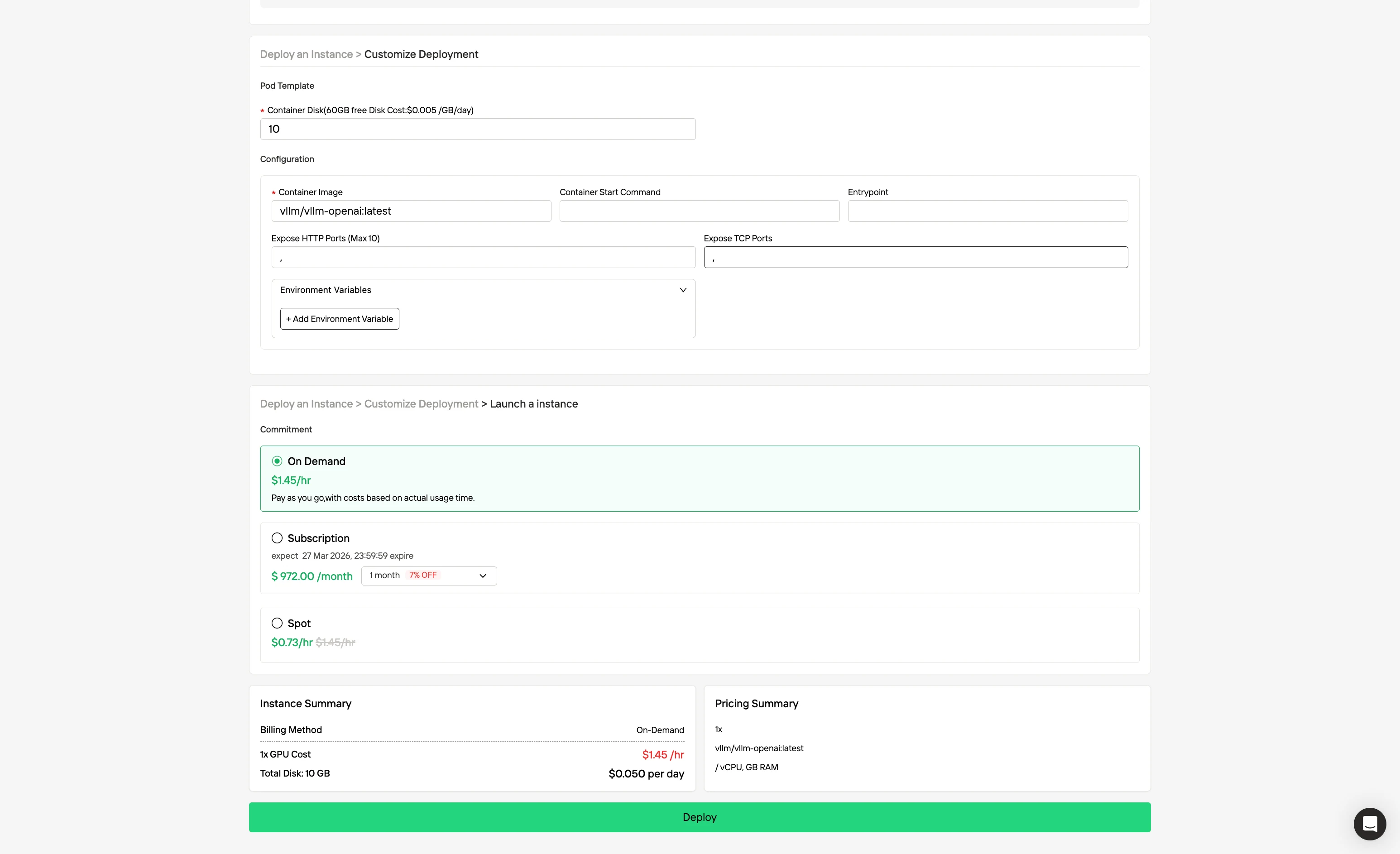
Paso 3: Personalizar tu despliegue
Personaliza tu entorno seleccionando tu sistema operativo preferido y opciones de configuración para garantizar un rendimiento óptimo para tus cargas de trabajo y necesidades de desarrollo de IA específicas.
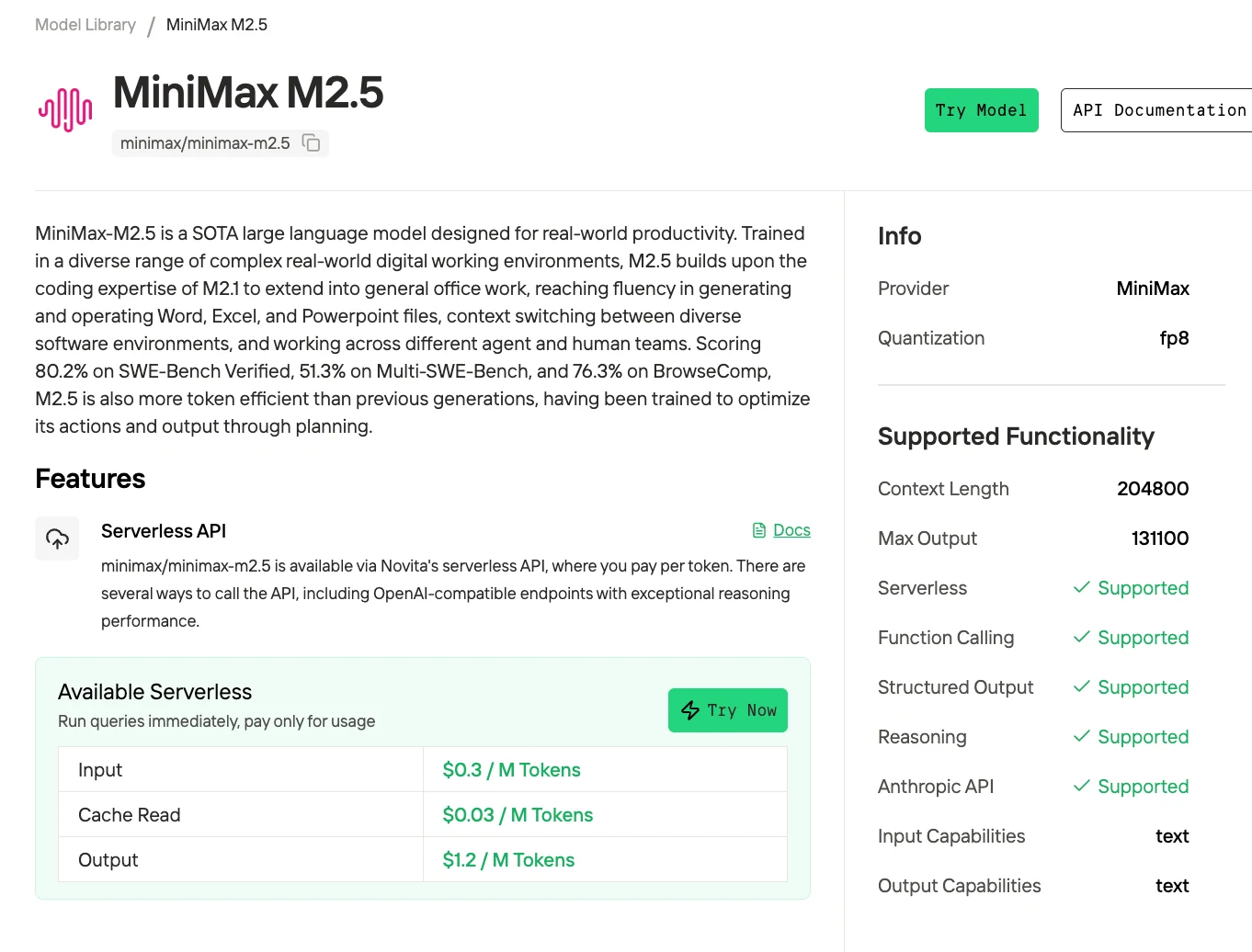
La arquitectura MoE de 229B de MiniMax M2.5 permite un rendimiento de codificación de vanguardia, pero exige al menos 96 GB de VRAM para cuantización de 2 bits o 128-160 GB para despliegues de 3-4 bits de calidad de producción. Para la mayoría de los desarrolladores, el despliegue por API a $0.30/$1.20 por 1M de tokens ofrece el mejor equilibrio entre costo, rendimiento y simplicidad hasta 50M de tokens al mes.
Preguntas frecuentes
¿Puedo ejecutar MiniMax M2.5 en una sola RTX 4090?
No, MiniMax M2.5 requiere un mínimo de 74 GB de VRAM incluso con la cuantización más agresiva de 2 bits UD-IQ2_XXS. Una sola RTX 4090 tiene solo 24 GB de VRAM. Necesitas al menos 3-4 GPU de consumo o 2×H100.
¿Qué nivel de cuantización mantiene la calidad de producción para MiniMax M2.5?
Q4_K_M (138 GB) o Q3_K_M de 3 bits dinámicos (109 GB) ofrecen el mejor equilibrio. Evita Q2_K (83 GB) para producción: usuarios de Reddit reportan una degradación notable en la calidad de codificación a pesar de la mayor capacidad de contexto.
¿Cómo funciona el precio de la API de MiniMax M2.5?
Con los precios de Novita de $0.30 / $1.20 por 1M de tokens, procesar 1M de tokens por día cuesta aproximadamente $45 al mes a través de la API.
Novita AI es una plataforma en la nube de IA y agentes que ayuda a desarrolladores y startups a construir, desplegar y escalar modelos y aplicaciones agente con alto rendimiento, confiabilidad y eficiencia de costos.
Lecturas recomendadas



