

MiniMax M2.5는 소비자 하드웨어에서 실행할 수 있습니다. 단, 강력한 양자화가 필요합니다. Unsloth AI의 Dynamic 3-bit GGUF 양자화를 사용하면 457GB의 전체 정밀도 모델을 약 101GB로 줄일 수 있습니다. 이 가이드는 양자화 수준별 실제 VRAM 요구 사항을 분석하고, Novita AI 클라우드 가격과 함께 특정 GPU 구성에 매핑합니다.
MiniMax M2.5 소개
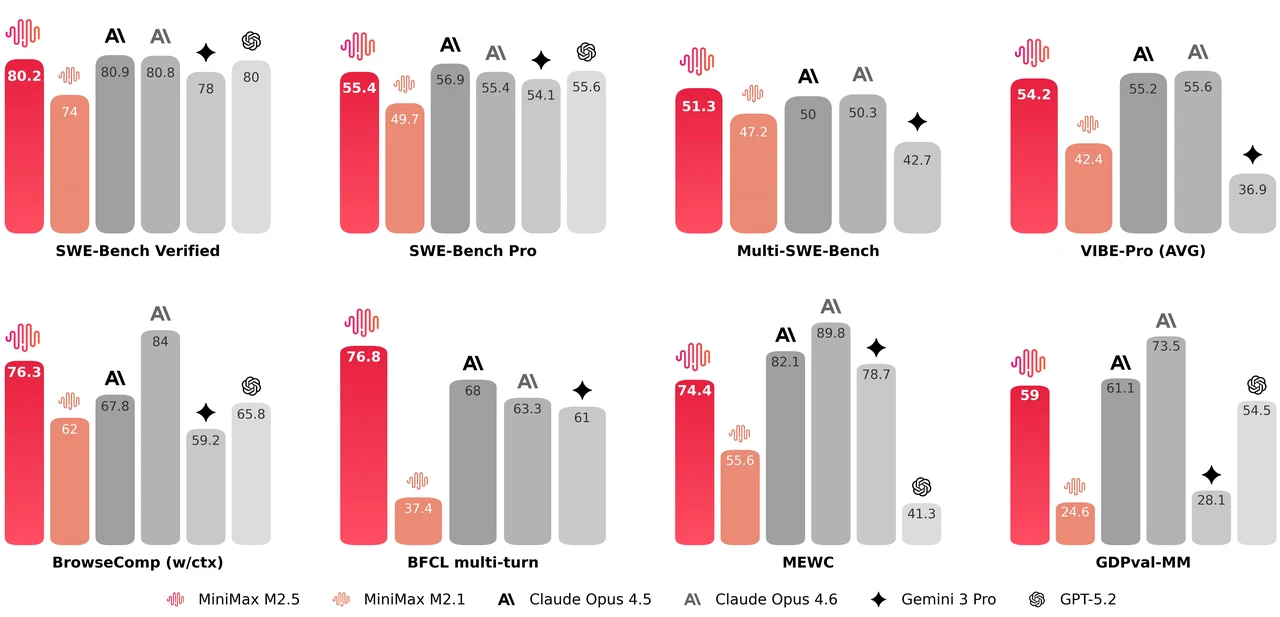
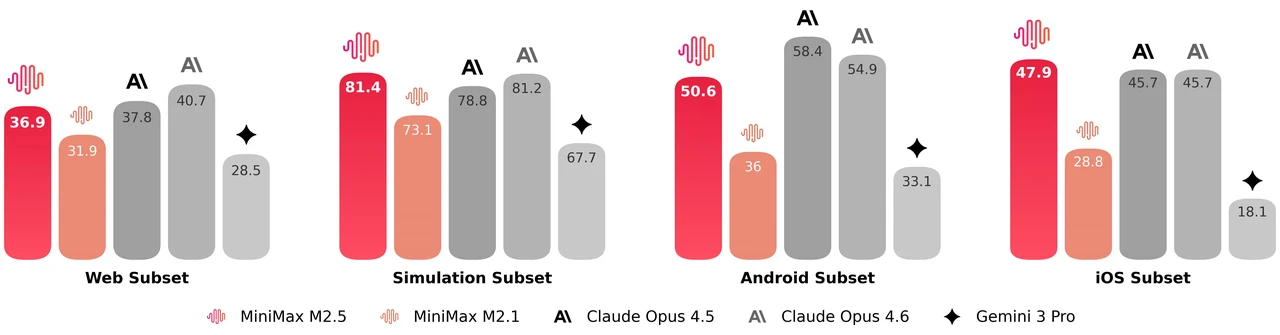
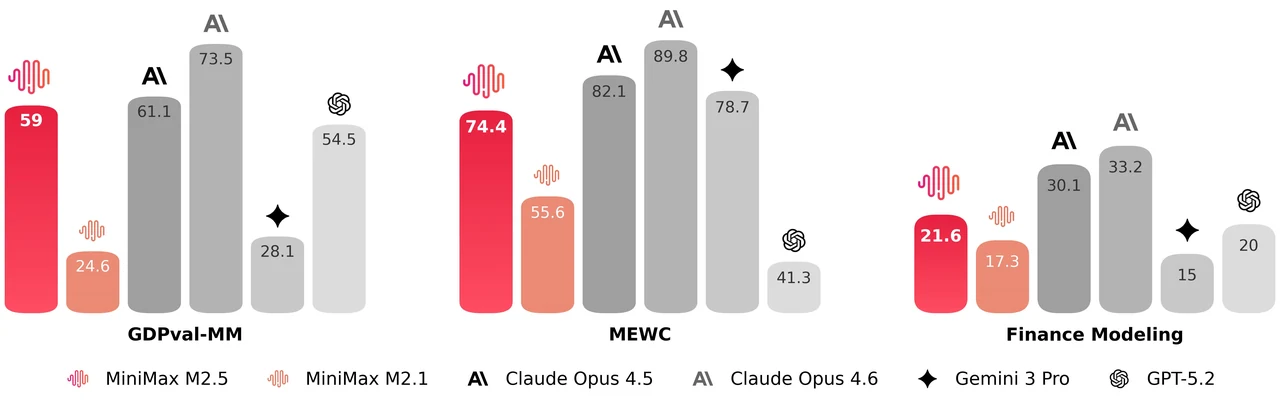
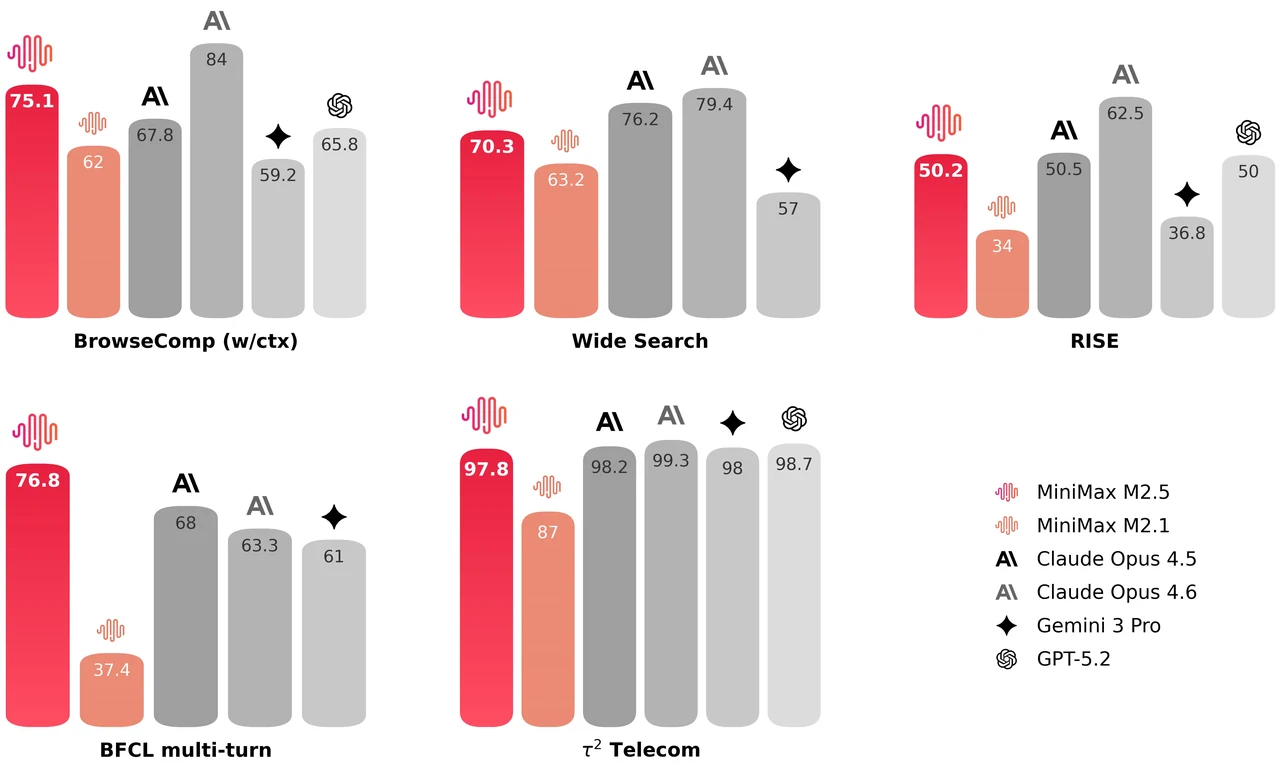
MiniMax M2.5는 229B 파라미터 혼합 전문가(MoE) 모델로, 256개의 전문가 레이어를 가지며 토큰당 8개의 전문가(약 10B 파라미터)를 활성화합니다. SWE-Bench Verified에서 80.2%, Multi-SWE-Bench에서 51.3%, BrowseComp에서 76.3% 를 달성하여 에이전트 코딩 및 도구 사용에 가장 강력한 오픈 모델 중 하나입니다. 이 모델은 205K 토큰 컨텍스트 윈도우를 지원하며 MIT 라이선스로 상업적 사용에 제한이 없습니다.
Huggingface에서 가져옴
Huggingface에서 가져옴
Huggingface에서 가져옴
MiniMax M2.5의 VRAM 요구 사항
VRAM 필요량은 정밀도 수준에 따라 달라집니다. 아래 표는 Unsloth의 GGUF 양자화 및 하이브리드 AWQ 형식의 파일 크기를 보여줍니다. 컨텍스트 길이와 배치 크기에 따라 KV 캐시에 4~10GB의 오버헤드를 추가하세요.
| 구성 | 필요 VRAM |
|---|---|
| BF16 (전체 정밀도) | 457 GB |
| Q8_0 GGUF | 243 GB |
| Q6_K GGUF | 188 GB |
| Q4_K_M GGUF | 138 GB |
| IQ4_XS GGUF | 122 GB |
| Q3_K_M GGUF (Dynamic 3-bit) | 109 GB |
| Q2_K GGUF | 83 GB |
| UD-IQ2_XXS GGUF (Ultra-Dynamic 2-bit) | 74 GB |
하이브리드 양자화 방식(INT4 AWQ 가중치, FP8 어텐션, 보정된 FP8 KV 캐시)을 사용하면 MiniMax M2.5는 192GB VRAM에서 370K 컨텍스트에 도달할 수 있으며, 일반적으로 KV 캐시에 제한되는 표준 AWQ에 비해 배치 처리량이 크게 향상됩니다.
MiniMax M2.5의 GPU 권장 사항
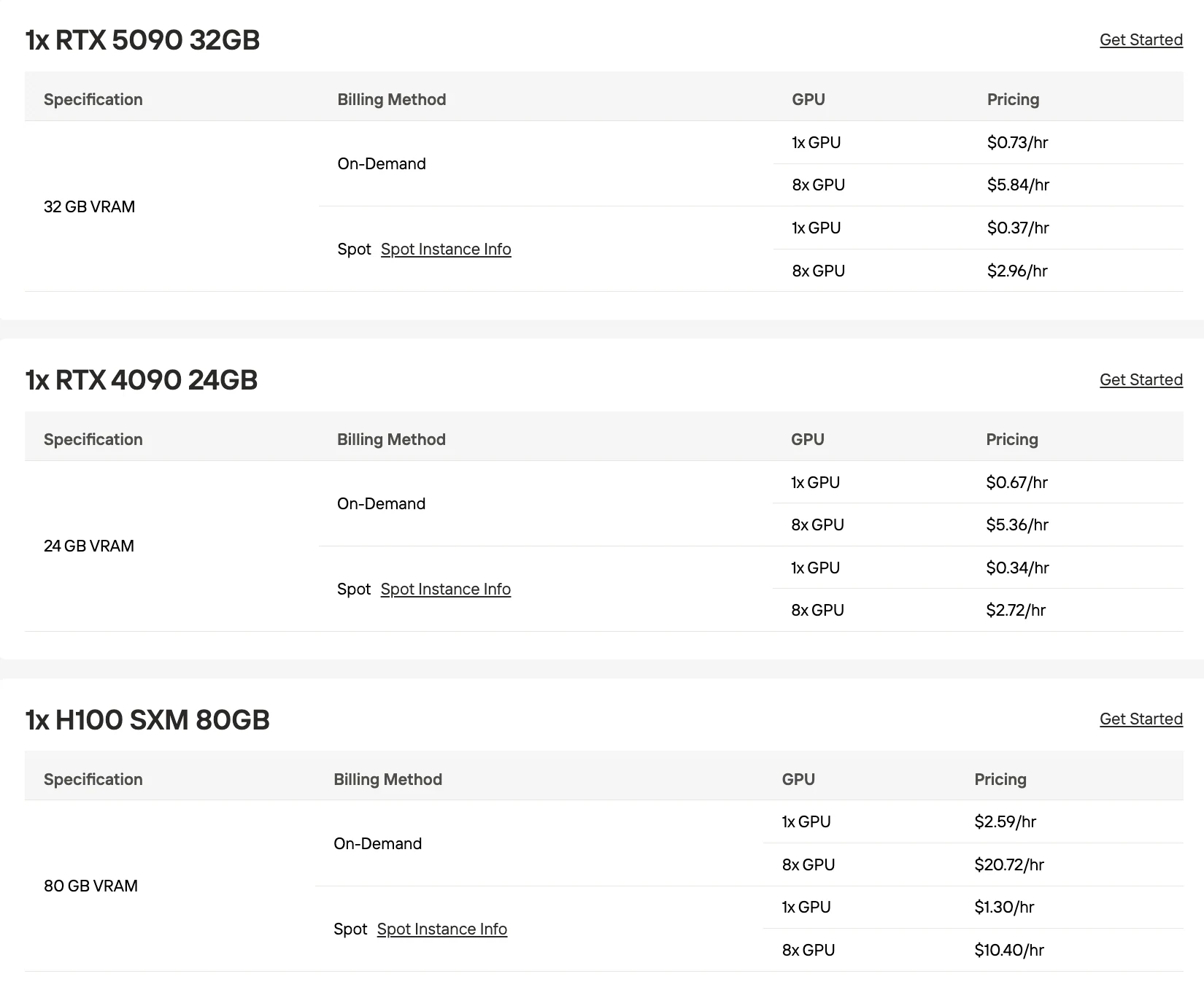
아래 모든 가격은 Novita AI 온디맨드 요금을 반영합니다. 멀티 GPU 비용은 단일 GPU 가격 × 개수로 계산됩니다.
RTX 5090 (32GB)
| 구성 | 총 VRAM | 양자화 | 참고 |
|---|---|---|---|
| 3× RTX 5090 | 96GB | Q2_K | 작동하지만 메모리 한계에 도달 |
| 4× RTX 5090 | 128GB | Q3_K_M Dynamic 3-bit | 적당한 배치에서 안정적 |
H100 (80GB)
| 구성 | 총 VRAM | 양자화 | 참고 |
|---|---|---|---|
| 2× H100 | 160GB | Q4_K_M | 더 높은 모델 품질로 안정적인 배포 |
권장하지 않음: 단일 RTX 4090 또는 RTX 5090은 가장 공격적인 양자화에서도 MiniMax M2.5를 수용할 수 없습니다. Q3_K_M을 사용한 Strix Halo APU는 “거의 사용할 수 없는” 속도를 제공하며, 80K 컨텍스트를 처리하지만 비실용적인 추론 속도를 보입니다.
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
실용적인 배포 전략
전략 1: API 우선 + 스팟 GPU 장애 조치
개발 및 가벼운 프로덕션용으로 토큰 100만 개당 $0.30/$1.20의 Novita AI API로 시작하세요. 트래픽이 월 약 1억 토큰(API 비용 월 $150)을 초과하면 배치 처리 작업을 위해 2×H100의 스팟 인스턴스를 시간당 $5.18로 가동하고, 실시간 사용자 대상 추론에는 API를 유지하세요. 이 하이브리드 접근 방식은 대화형 사용에 대한 낮은 지연 시간을 유지하면서 비용을 최대한 절감합니다.
규모에서 비용을 더욱 줄이기 위해 Novita는 저렴한 API 가격과 함께 할인된 프롬프트 캐시 읽기를 제공합니다. 프롬프트가 재사용되는 경우(예: 시스템 지침, 템플릿 또는 반복되는 컨텍스트) 캐시된 토큰이 다시 계산되는 대신 더 낮은 요율로 제공되어 지연 시간과 비용을 모두 줄입니다. 이는 특히 에이전트 워크플로 및 고빈도 쿼리의 경우 API 우선 + 배치 아키텍처를 더욱 효율적으로 만듭니다.
전략 2: 양자화를 통한 자체 호스팅
개인 정보 보호 요구 사항이나 대량 지속 워크로드가 있는 팀의 경우 2×H100에 Q3_K_M Dynamic 3-bit 또는 Q4_K_M 양자화를 배포하세요. 프로덕션급 처리량 최적화를 위해 GGUF 형식에는 llama.cpp를, AWQ에는 vLLM을 사용하세요.
클라우드 GPU에서 MiniMax M2.5에 액세스하는 방법
1단계: 계정 등록
웹사이트를 통해 Novita AI 계정을 만드세요. 등록 후 왼쪽 사이드바에서 “Explore” 섹션으로 이동하여 GPU 제품을 확인하고 AI 개발 여정을 시작하세요.

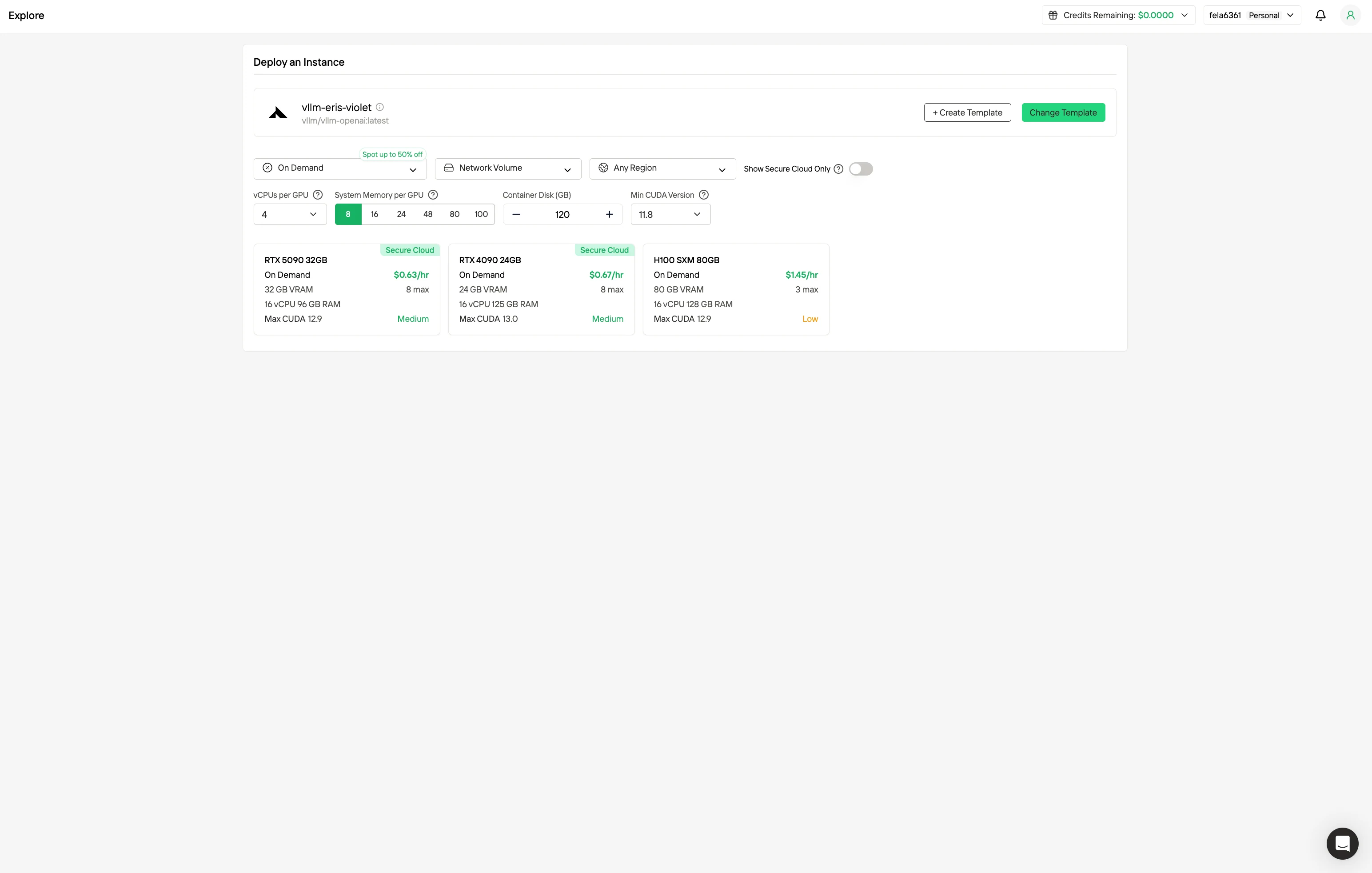
2단계: 템플릿 및 GPU 서버 탐색
프로젝트 요구 사항에 맞는 PyTorch, TensorFlow 또는 CUDA와 같은 템플릿을 선택하세요. 그런 다음 원하는 GPU 구성을 선택하세요. 옵션에는 각각 다른 VRAM, RAM 및 스토리지 사양을 가진 강력한 GPU가 포함됩니다.
3단계: 배포 맞춤 설정
선호하는 운영 체제와 구성 옵션을 선택하여 특정 AI 워크로드 및 개발 요구 사항에 대한 최적의 성능을 보장하도록 환경을 사용자 지정하세요.
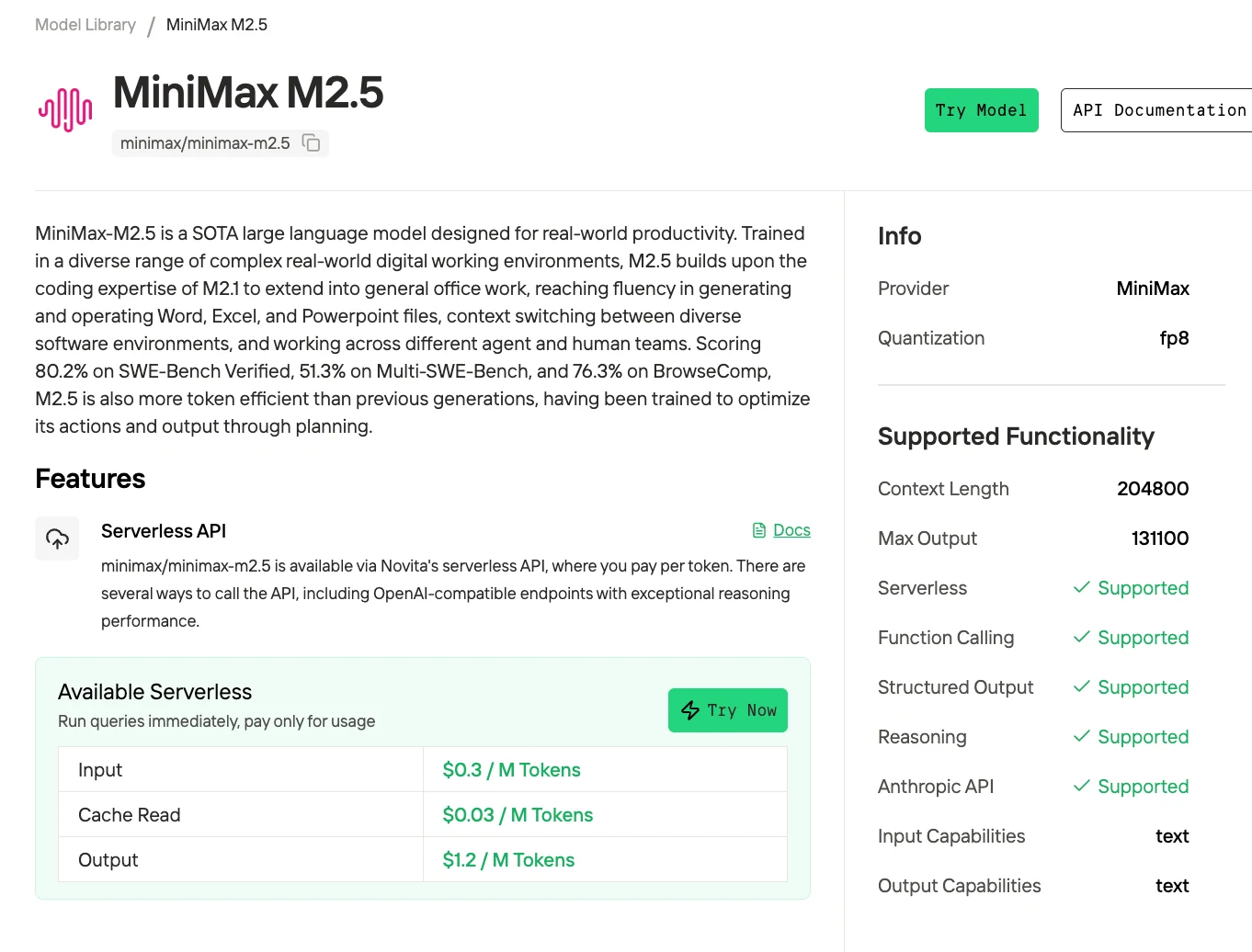
MiniMax M2.5의 229B MoE 아키텍처는 최첨단 코딩 성능을 가능하게 하지만, 2비트 양자화에는 최소 96GB VRAM, 프로덕션 품질의 3~4비트 배포에는 128~160GB VRAM이 필요합니다. 대부분의 개발자에게 토큰 100만 개당 $0.30/$1.20의 API 배포는 월 최대 5000만 토큰까지 최고의 비용-성능-단순성 균형을 제공합니다.
자주 묻는 질문
MiniMax M2.5를 단일 RTX 4090에서 실행할 수 있나요?
아니요, MiniMax M2.5는 가장 공격적인 UD-IQ2_XXS 2비트 양자화에서도 최소 74GB VRAM이 필요합니다. 단일 RTX 4090은 24GB VRAM만 있습니다. 최소 3~4개의 소비자 GPU 또는 2×H100이 필요합니다.
MiniMax M2.5에 대해 프로덕션 품질 출력을 유지하는 양자화 수준은 무엇인가요?
Q4_K_M (138GB) 또는 Dynamic 3-bit Q3_K_M (109GB)이 최상의 균형을 제공합니다. 프로덕션에서는 Q2_K (83GB)를 피하세요. Reddit 사용자들은 더 높은 컨텍스트 용량에도 불구하고 코딩 품질이 눈에 띄게 저하된다고 보고합니다.
MiniMax M2.5 API 가격은 어떻게 작동하나요?
Novita의 토큰 100만 개당 $0.30 / $1.20 요금제에서 하루 100만 토큰을 처리하면 API를 통해 월 약 $45의 비용이 발생합니다.
Novita AI는 개발자와 스타트업이 고성능, 신뢰성, 비용 효율성으로 모델 및 에이전트 애플리케이션을 구축, 배포 및 확장할 수 있도록 지원하는 AI 및 에이전트 클라우드 플랫폼입니다.
추천 읽을거리



