

MiniMax M2.5 может работать на потребительском железе — но только при агрессивном квантовании. С помощью динамического 3-битного GGUF-квантования от Unsloth AI вы можете уменьшить модель полной точности объемом 457 ГБ примерно до 101 ГБ. В этом руководстве разобраны реальные требования к VRAM для разных уровней квантования, сопоставлены с конфигурациями конкретных GPU с указанием цен на облачные ресурсы Novita AI.
Введение в MiniMax M2.5
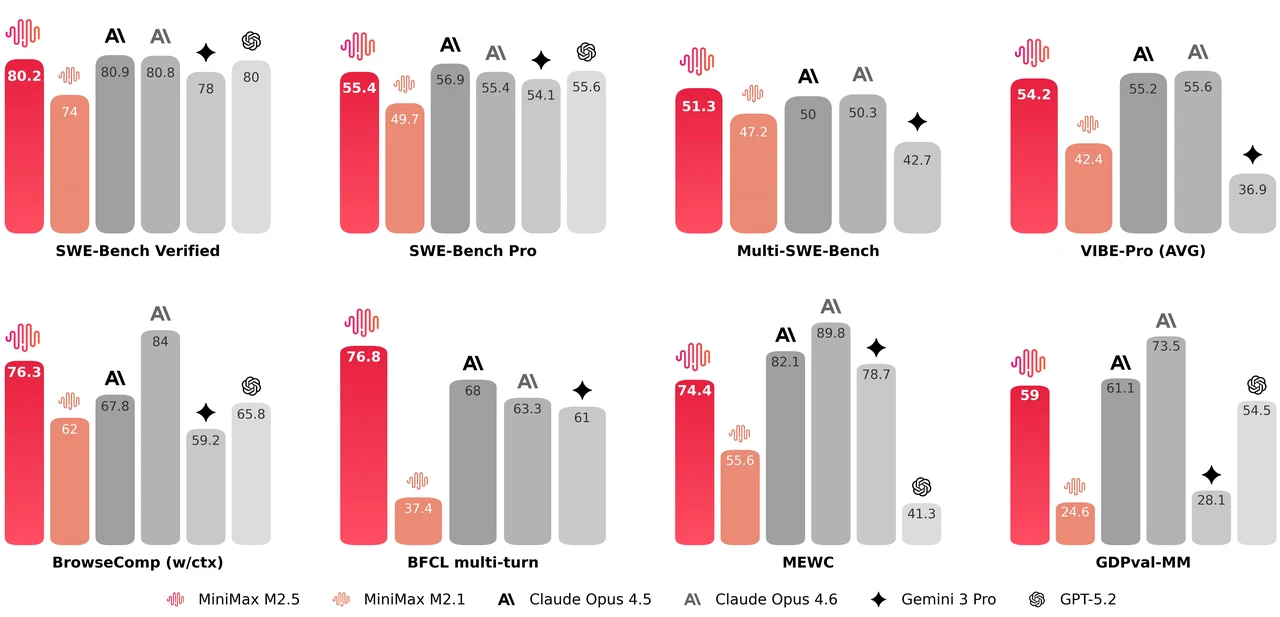
MiniMax M2.5 — это модель смеси экспертов с 229 млрд параметров, имеющая 256 слоев экспертов, активирующих 8 экспертов (примерно 10 млрд параметров) на токен. Она достигает 80,2% на SWE-Bench Verified, 51,3% на Multi-SWE-Bench и 76,3% на BrowseComp, что делает ее одной из самых сильных открытых моделей для агентного кодирования и использования инструментов. Модель поддерживает контекстное окно в 205K токенов и имеет лицензию MIT, разрешающую неограниченное коммерческое использование.
Источник: Huggingface
Источник: Huggingface
Источник: Huggingface
Требования к VRAM для MiniMax M2.5
Потребности в VRAM зависят от уровня точности. В таблице ниже указаны размеры файлов для GGUF-квантований от Unsloth и гибридных форматов AWQ — добавьте 4–10 ГБ накладных расходов для KV-кэша в зависимости от длины контекста и размера пакета.
| Конфигурация | Требуемый объем VRAM |
|---|---|
| BF16 (полная точность) | 457 ГБ |
| Q8_0 GGUF | 243 ГБ |
| Q6_K GGUF | 188 ГБ |
| Q4_K_M GGUF | 138 ГБ |
| IQ4_XS GGUF | 122 ГБ |
| Q3_K_M GGUF (динамическое 3-битное) | 109 ГБ |
| Q2_K GGUF | 83 ГБ |
| UD-IQ2_XXS GGUF (ультра-динамическое 2-битное) | 74 ГБ |
При гибридной схеме квантования (веса INT4 AWQ, внимание FP8 и откалиброванный KV-кэш FP8) MiniMax M2.5 может достигать контекста в 370K токенов на 192 ГБ VRAM и обеспечивать значительно более высокую пропускную способность пакетной обработки по сравнению со стандартным AWQ, который обычно ограничен объемом KV-кэша.
Рекомендации по GPU для MiniMax M2.5
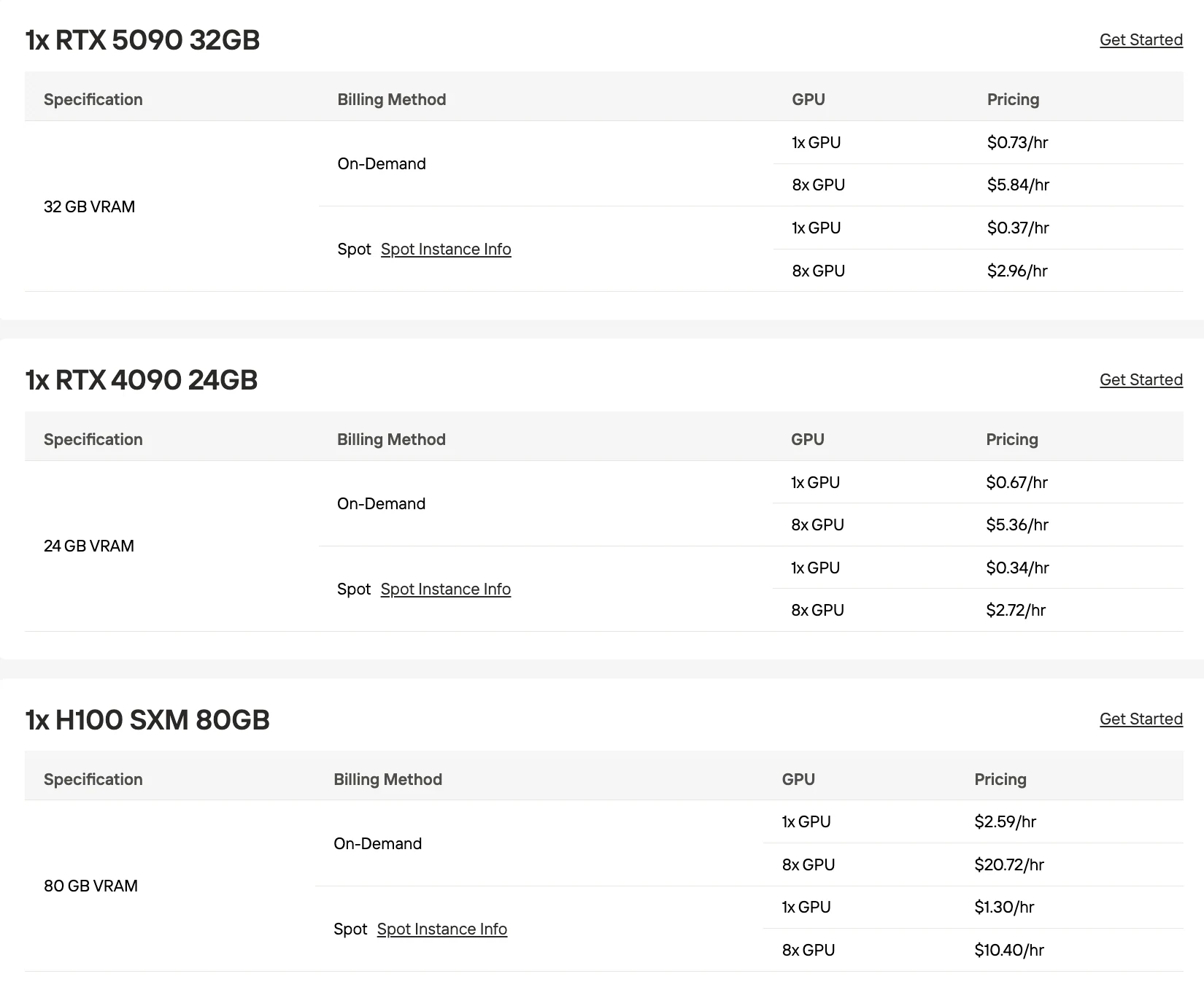
Все цены ниже указаны по тарифам Novita AI по требованию. Стоимость конфигураций с несколькими GPU рассчитывается как цена за один GPU × количество.
RTX 5090 (32 ГБ)
| Конфигурация | Общий объем VRAM | Квантование | Примечания |
|---|---|---|---|
| 3× RTX 5090 | 96 ГБ | Q2_K | Работает, но на грани возможностей памяти |
| 4× RTX 5090 | 128 ГБ | Q3_K_M динамическое 3-битное | Стабильная работа при умеренной пакетной обработке |
H100 (80 ГБ)
| Конфигурация | Общий объем VRAM | Квантование | Примечания |
|---|---|---|---|
| 2× H100 | 160 ГБ | Q4_K_M | Стабильное развертывание с более высоким качеством модели |
Не рекомендуется: Одиночный RTX 4090 или RTX 5090 не могут разместить MiniMax M2.5 даже при самом агрессивном квантовании. APU Strix Halo с Q3_K_M дает “практически непригодные” скорости, обрабатывая контекст в 80K токенов, но с непрактичной скоростью инференса.
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
Практические стратегии развертывания
Стратегия 1: Приоритет API с отказоустойчивостью на спотовых GPU
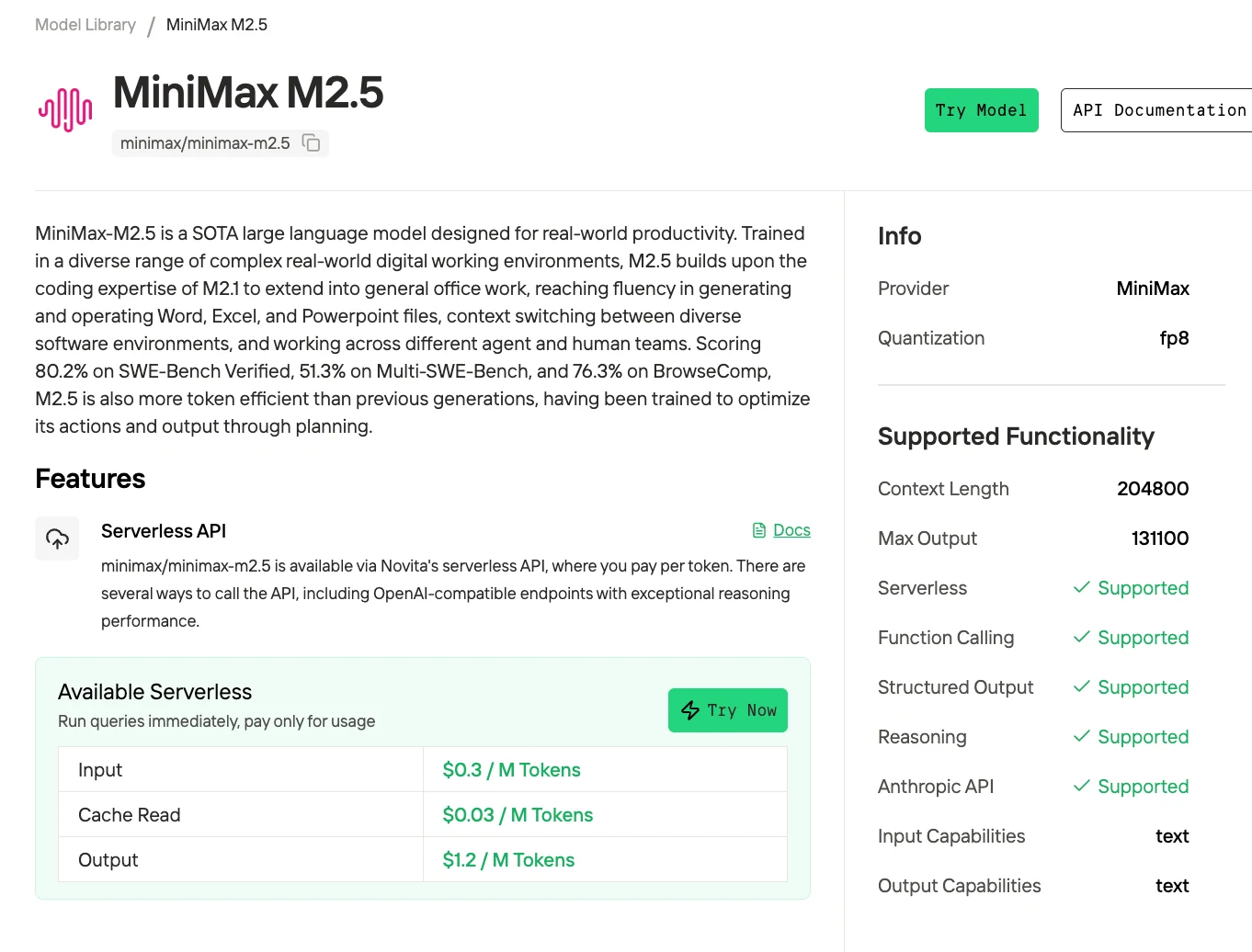
Начните с API Novita AI по тарифу $0.30/$1.20 за 1M токенов для разработки и легкого продакшена. Когда трафик превысит ~100M токенов в месяц (стоимость API $150 в месяц), разверните спотовые инстансы 2×H100 по $5.18 в час для пакетных задач обработки, оставив API для реального инференса, ориентированного на пользователей. Этот гибридный подход ограничивает расходы, сохраняя низкую задержку для интерактивного использования.
Для дальнейшего снижения затрат при масштабировании Novita предлагает низкие цены на API, а также скидки на чтение из кэша промптов. Когда промпты используются повторно (например, системные инструкции, шаблоны или повторяющийся контекст), токены из кэша обслуживаются по более низкой ставке вместо повторного вычисления — это снижает как задержку, так и стоимость. Это делает архитектуру с приоритетом API + пакетную обработку еще более эффективной, особенно для агентных рабочих процессов и частых запросов.
Попробуйте MiniMax M2.5 сейчас!
Стратегия 2: Самостоятельное развертывание с квантованием
Для команд с требованиями к конфиденциальности или большим объемом постоянных рабочих нагрузок разверните квантование Q3_K_M (динамическое 3-битное) или Q4_K_M на 2×H100. Используйте llama.cpp для форматов GGUF или vLLM с AWQ для оптимизации пропускной способности до уровня продакшена.
Как получить доступ к MiniMax M2.5 на облачных GPU?
Шаг 1: Зарегистрируйте аккаунт
Создайте аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел “Explore” (Обзор) в левой боковой панели, чтобы ознакомиться с нашими предложениями GPU и начать путь в разработке ИИ.

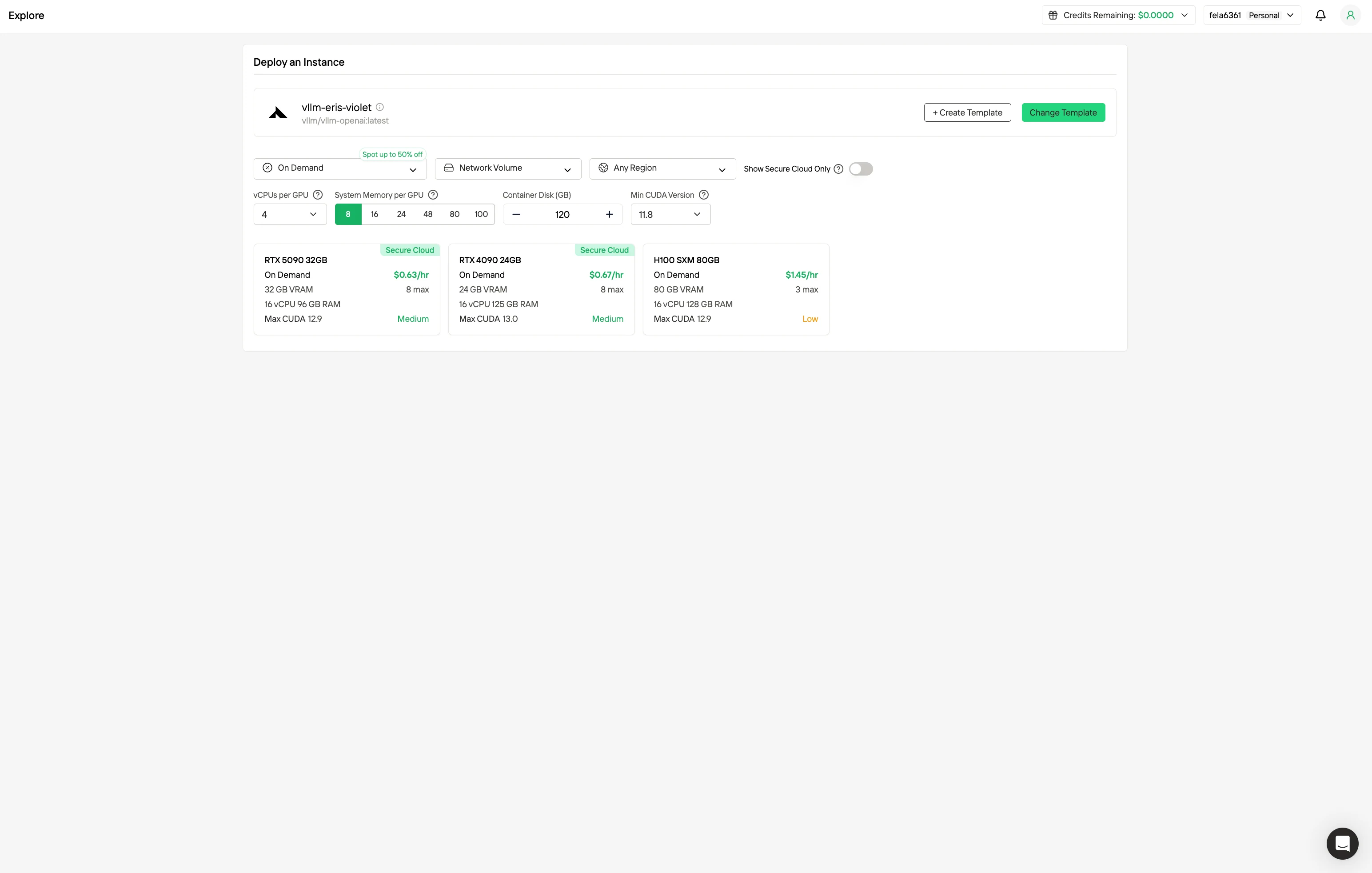
Шаг 2: Изучение шаблонов и GPU-серверов
Выбирайте из шаблонов, таких как PyTorch, TensorFlow или CUDA, соответствующих потребностям вашего проекта. Затем выберите нужную конфигурацию GPU — доступны мощные GPU с разными характеристиками по объему VRAM, оперативной памяти и хранилищу.
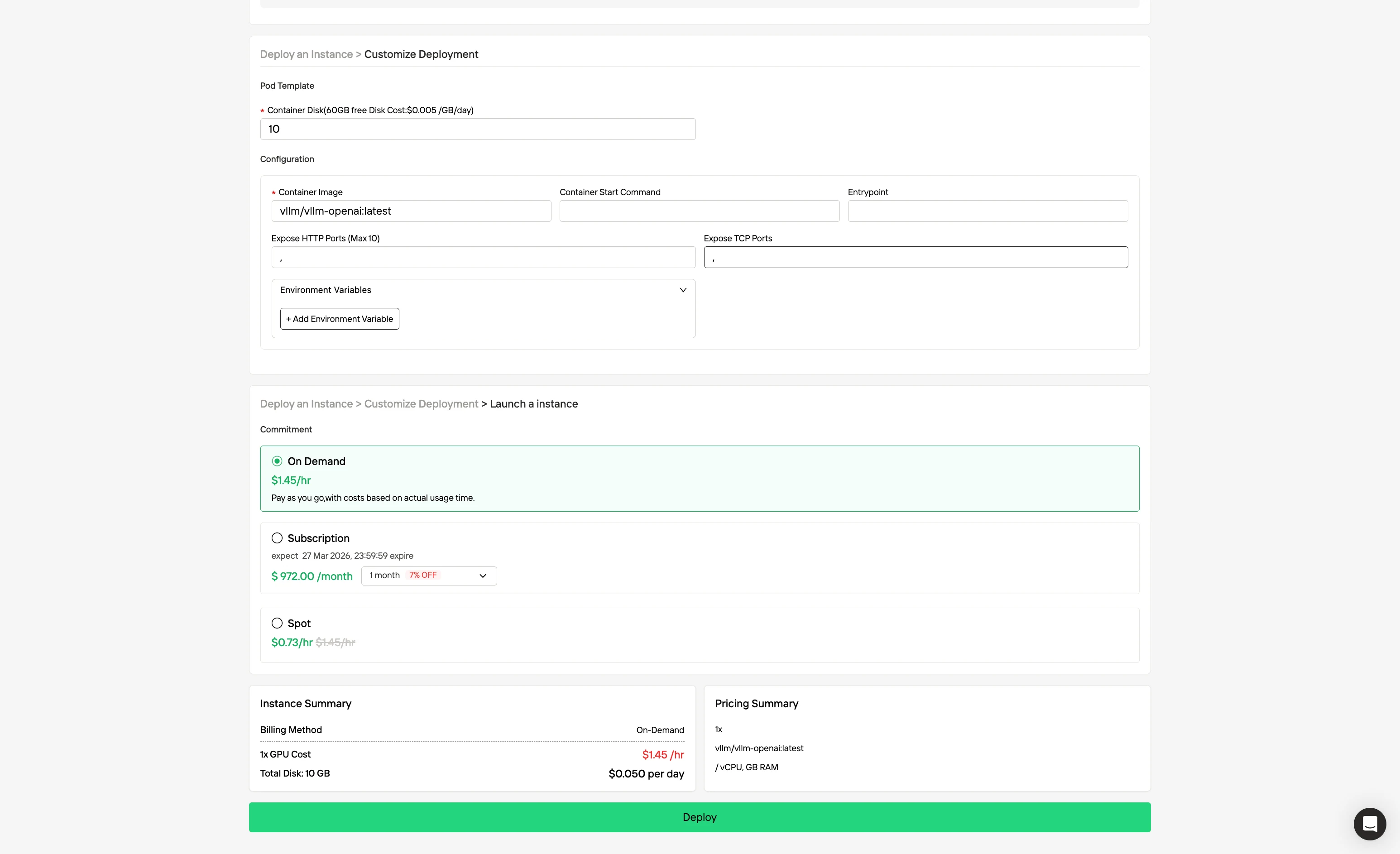
Шаг 3: Настройте развертывание под ваши нужды
Настройте окружение, выбрав предпочитаемую операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных рабочих нагрузок ИИ и потребностей в разработке.
Архитектура MoE MiniMax M2.5 с 229 млрд параметров обеспечивает передовую производительность в кодировании, но требует минимум 96 ГБ VRAM для 2-битного квантования или 128–160 ГБ для развертываний с производственным качеством при 3–4-битном квантовании. Для большинства разработчиков развертывание через API по тарифу $0.30/$1.20 за 1M токенов предлагает лучший баланс стоимости, производительности и простоты при объеме до 50M токенов в месяц.
Часто задаваемые вопросы
Можно ли запустить MiniMax M2.5 на одном RTX 4090?
Нет, MiniMax M2.5 требует минимум 74 ГБ VRAM даже при самом агрессивном 2-битном квантовании UD-IQ2_XXS. Одиночный RTX 4090 имеет только 24 ГБ VRAM. Вам потребуется минимум 3–4 потребительских GPU или 2×H100.
Какой уровень квантования сохраняет производственное качество вывода для MiniMax M2.5?
Q4_K_M (138 ГБ) или динамическое 3-битное Q3_K_M (109 ГБ) обеспечивают лучший баланс. Избегайте Q2_K (83 ГБ) для продакшена — пользователи Reddit сообщают о заметном снижении качества кодирования, несмотря на более высокую емкость контекста.
Как работает тарификация API MiniMax M2.5?
По тарифам Novita в $0.30 / $1.20 за 1M токенов обработка 1M токенов в день обходится примерно в $45 в месяц через API.
Novita AI — это облачная платформа для ИИ и агентов, которая помогает разработчикам и стартапам создавать, развертывать и масштабировать модели и агентные приложения с высокой производительностью, надежностью и эффективностью затрат.
Рекомендуемые материалы



