

MiniMax M2.5はコンシューマ向けハードウェアで動作可能ですが、積極的な量子化が必要です。 Unsloth AIのDynamic 3-bit GGUF量子化により、457GBのフルプレシジョンモデルを約101GBまで削減できます。このガイドでは、量子化レベルごとの実際のVRAM要件を詳しく解説し、それぞれをNovita AIのクラウド価格とともに特定のGPU構成にマッピングします。
MiniMax M2.5の紹介
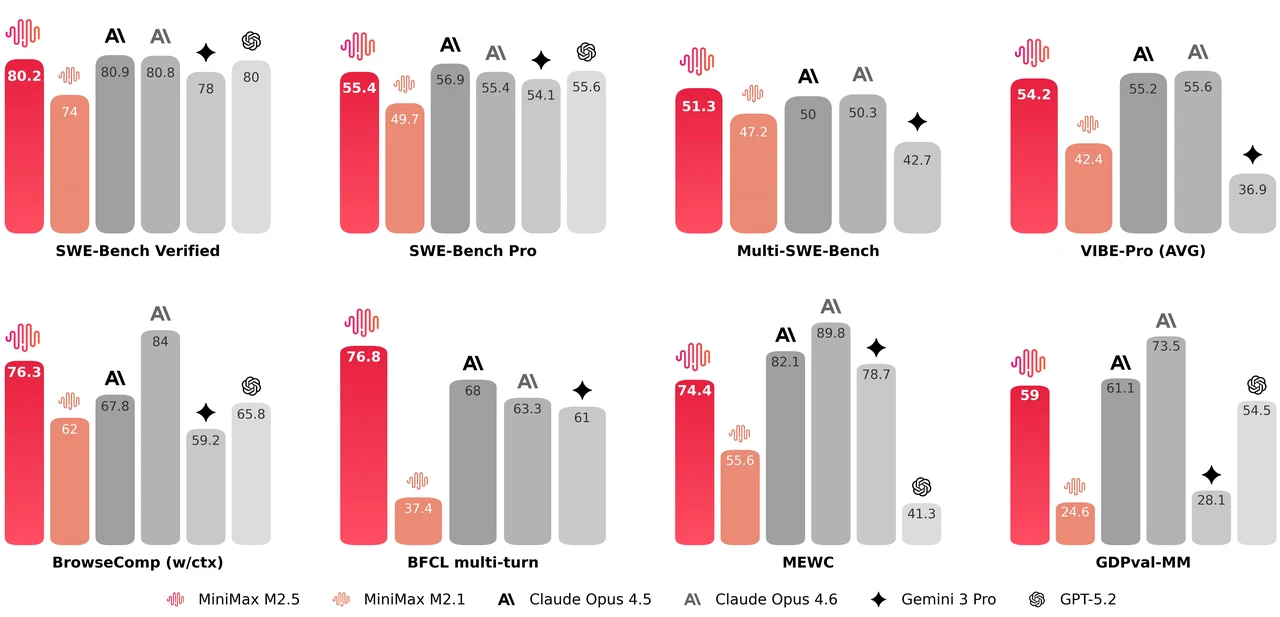
MiniMax M2.5は、256のエキスパート層を持つ229BパラメータのMixture-of-Expertsモデルで、トークンあたり8つのエキスパート(約10Bパラメータ)を活性化します。SWE-Bench Verifiedで80.2%、Multi-SWE-Benchで51.3%、BrowseCompで**76.3%**を達成し、エージェント型コーディングやツール使用において最も強力なオープンモデルの1つです。このモデルは205Kトークンのコンテキストウィンドウをサポートし、MITライセンスで商用利用に制限はありません。
出典: Huggingface
出典: Huggingface
出典: Huggingface
MiniMax M2.5のVRAM要件
VRAM要件は精度レベルに比例します。以下の表は、UnslothのGGUF量子化およびハイブリッドAWQフォーマットのファイルサイズを示しています。コンテキスト長とバッチサイズに応じて、KVキャッシュ用に4〜10GBのオーバーヘッドを追加してください。
| 構成 | 必要VRAM |
|---|---|
| BF16 (full precision) | 457 GB |
| Q8_0 GGUF | 243 GB |
| Q6_K GGUF | 188 GB |
| Q4_K_M GGUF | 138 GB |
| IQ4_XS GGUF | 122 GB |
| Q3_K_M GGUF (Dynamic 3-bit) | 109 GB |
| Q2_K GGUF | 83 GB |
| UD-IQ2_XXS GGUF (Ultra-Dynamic 2-bit) | 74 GB |
ハイブリッド量子化スキーム(INT4 AWQ重み、FP8アテンション、調整済みFP8 KVキャッシュ)を使用すると、MiniMax M2.5は192GB VRAMで370Kコンテキストに到達でき、通常KVキャッシュに制限される標準AWQと比較して、バッチスループットを大幅に向上させることができます。
MiniMax M2.5のGPU推奨構成
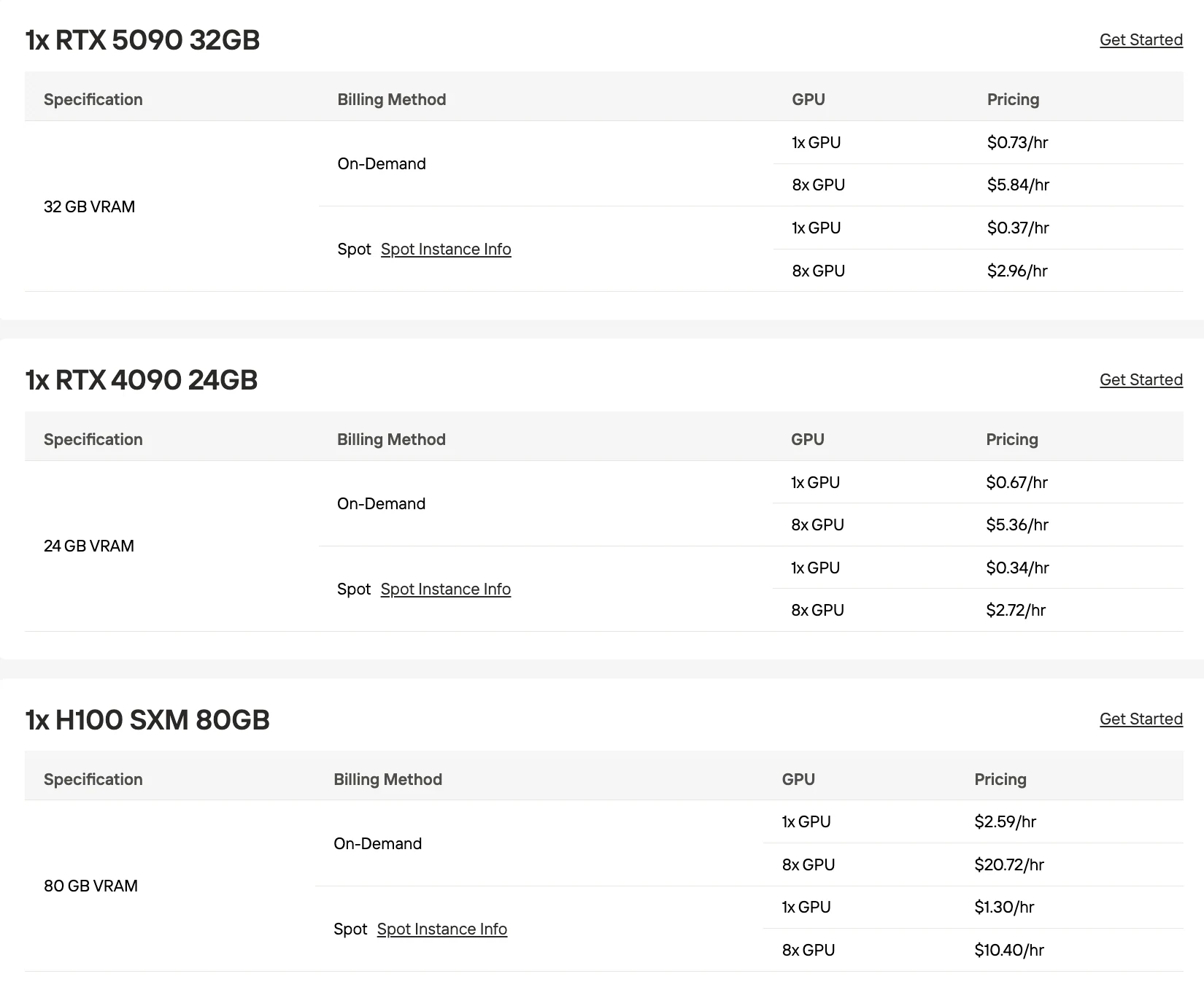
以下の価格はすべてNovita AIのオンデマンドレートを反映しています。マルチGPUコストは単一GPU価格×台数で計算されます。
RTX 5090 (32GB)
| 構成 | 合計VRAM | 量子化 | 備考 |
|---|---|---|---|
| 3× RTX 5090 | 96GB | Q2_K | 動作するがメモリ限界に近い |
| 4× RTX 5090 | 128GB | Q3_K_M Dynamic 3-bit | 適度なバッチングで安定 |
H100 (80GB)
| 構成 | 合計VRAM | 量子化 | 備考 |
|---|---|---|---|
| 2× H100 | 160GB | Q4_K_M | 高モデル品質で安定したデプロイ |
推奨しません: 単一のRTX 4090またはRTX 5090では、最も強力な量子化でもMiniMax M2.5を収容できません。Strix Halo APUでQ3_K_Mを使用した場合、「ほぼ使い物にならない」速度で、80Kコンテキストは処理できるものの、現実的な推論速度ではありません。
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
実践的なデプロイ戦略
戦略1: APIファーストとスポットGPUフェイルオーバー
開発および軽量プロダクション向けに、Novita AI APIを100万トークンあたり$0.30/$1.20で開始します。トラフィックが月間約1億トークン(APIコスト月$150)を超えた場合、バッチ処理ジョブ用にスポットインスタンスの2×H100を$5.18/時間で起動し、リアルタイムのユーザー向け推論にはAPIを維持します。このハイブリッドアプローチにより、対話型使用の低レイテンシを維持しながらコストを抑えます。
さらに大規模なコスト削減のために、Novitaは低コストのAPI料金と割引されたプロンプトキャッシュ読み取りを提供しています。プロンプトが再利用される場合(例:システム命令、テンプレート、繰り返しのコンテキスト)、キャッシュされたトークンは再計算される代わりに低料金で提供されるため、レイテンシとコストの両方が削減されます。これにより、特にエージェント型ワークフローや高頻度のクエリにおいて、APIファースト+バッチ処理アーキテクチャがさらに効率的になります。
戦略2: セルフホスティングと量子化
プライバシー要件や大量の持続的ワークロードがあるチーム向けには、2×H100上でQ3_K_M Dynamic 3-bitまたはQ4_K_M量子化をデプロイします。プロダクショングレードのスループット最適化には、GGUF形式にはllama.cpp、AWQにはvLLMを使用します。
クラウドGPUでMiniMax M2.5にアクセスする方法
ステップ1: アカウントを登録する
Novita AIのアカウントを当社ウェブサイトから作成します。登録後、左サイドバーの「Explore」セクションに移動してGPU提供プランを確認し、AI開発の旅を始めましょう。

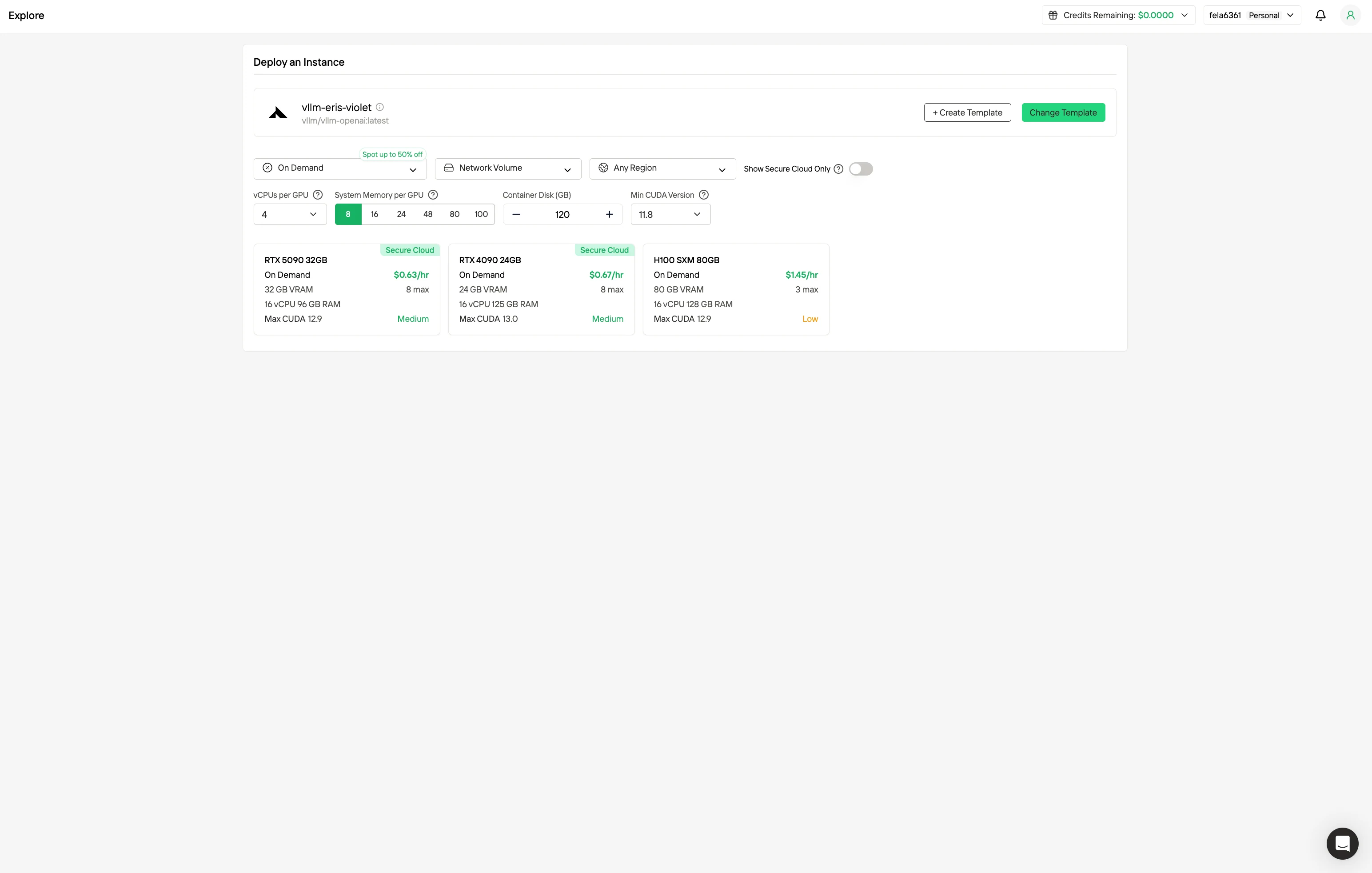
ステップ2: テンプレートとGPUサーバーの探索
プロジェクトのニーズに合ったPyTorch、TensorFlow、CUDAなどのテンプレートを選択します。次に、希望するGPU構成を選択します。オプションには強力なGPUがあり、それぞれ異なるVRAM、RAM、ストレージ仕様があります。
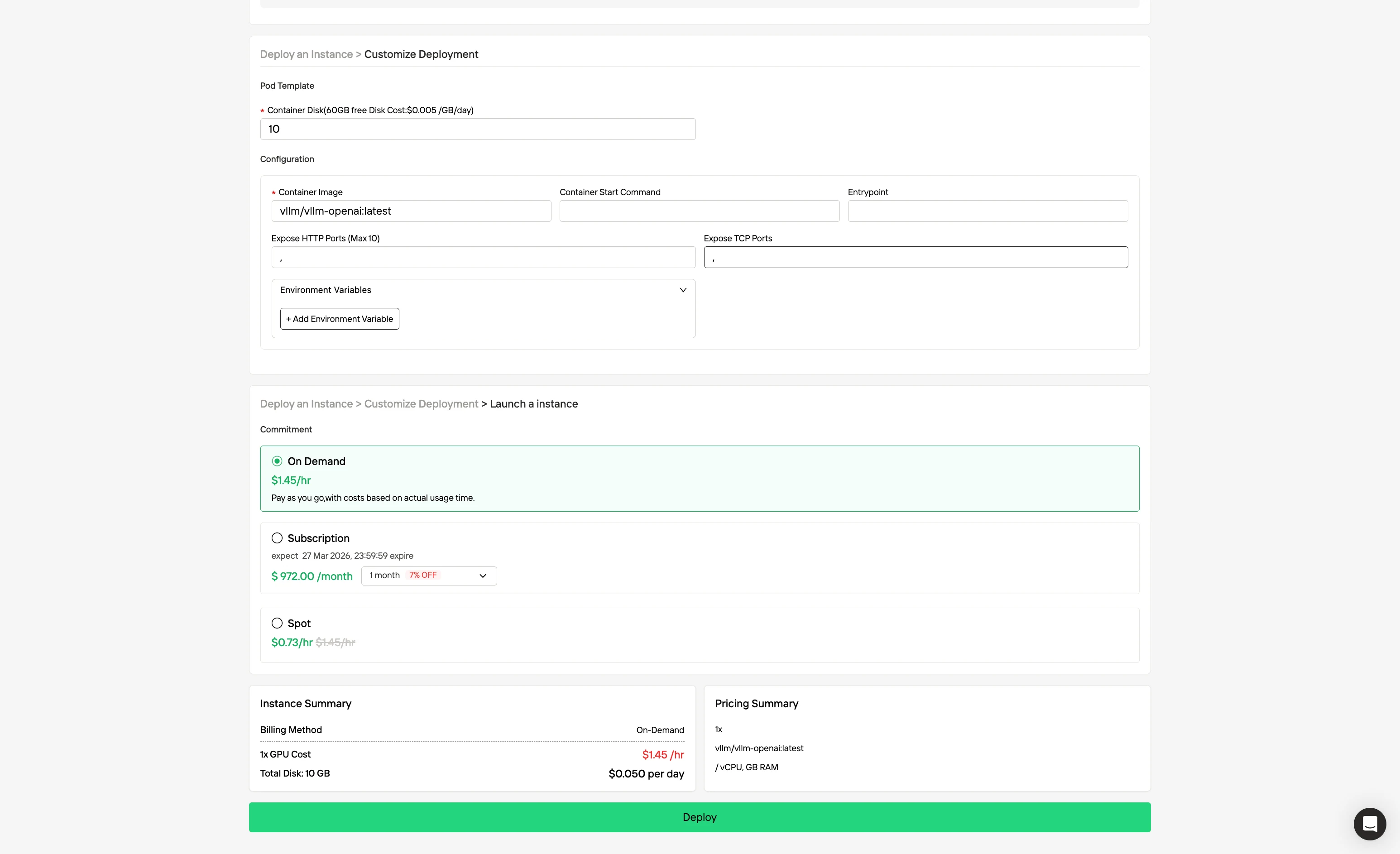
ステップ3: デプロイをカスタマイズする
お好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに最適なパフォーマンスを確保します。
MiniMax M2.5の229B MoEアーキテクチャは最先端のコーディング性能を実現しますが、2ビット量子化には最低96GBのVRAM、プロダクション品質の3〜4ビットデプロイには128〜160GBのVRAMが必要です。ほとんどの開発者にとって、100万トークンあたり$0.30/$1.20でのAPIデプロイは、月間5000万トークンまで最適なコスト・パフォーマンス・シンプルさのバランスを提供します。
よくある質問
単一のRTX 4090でMiniMax M2.5を実行できますか?
いいえ、MiniMax M2.5は最も積極的なUD-IQ2_XXS 2ビット量子化でも最低74GBのVRAMを必要とします。単一のRTX 4090はわずか24GBのVRAMしかありません。少なくとも3〜4台のコンシューマGPUまたは2×H100が必要です。
MiniMax M2.5でプロダクション品質の出力を維持する量子化レベルは?
Q4_K_M(138GB)またはDynamic 3-bit Q3_K_M(109GB)が最良のバランスを実現します。プロダクションではQ2_K(83GB)は避けてください — Redditユーザーは、より高いコンテキスト容量にもかかわらず、コーディング品質の顕著な低下を報告しています。
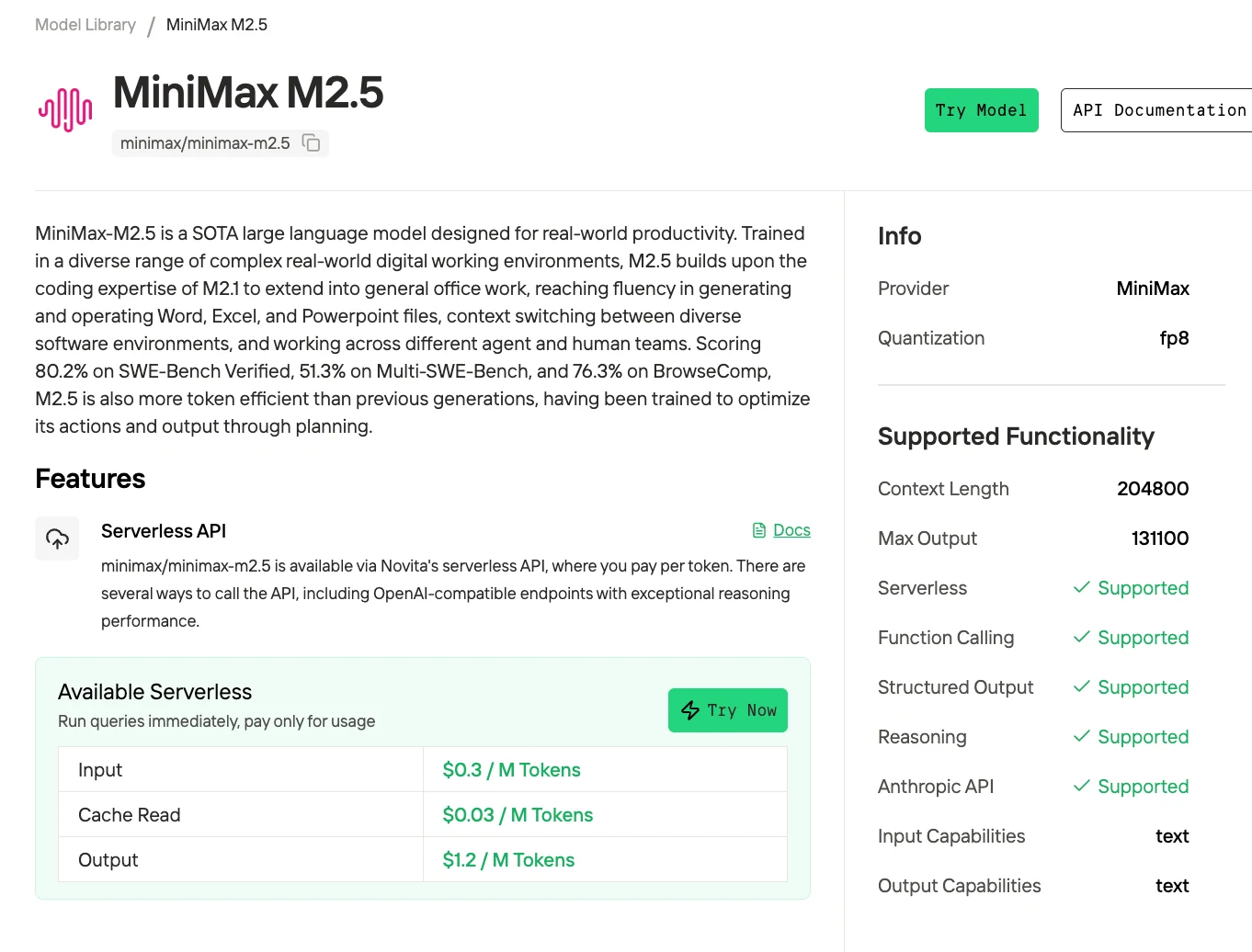
MiniMax M2.5 APIの料金体系は?
Novitaの100万トークンあたり$0.30/$1.20の場合、1日あたり100万トークンを処理するとAPI経由で約月額$45かかります。
Novita AIは、開発者やスタートアップが高性能、信頼性、コスト効率でモデルやエージェント型アプリケーションを構築、デプロイ、スケールするためのAI&エージェントクラウドプラットフォームです。
おすすめ記事



