

MiniMax M2.5 可以在消費級硬體上運行——但僅限於使用高壓縮量化技術。 透過 Unsloth AI 的動態 3 位元 GGUF 量化,可將 457GB 的全精度模型壓縮至約 101GB。本指南將拆解不同量化等級的實際 VRAM 需求,並結合 Novita AI 雲端計費對應到特定 GPU配置。
MiniMax M2.5 簡介
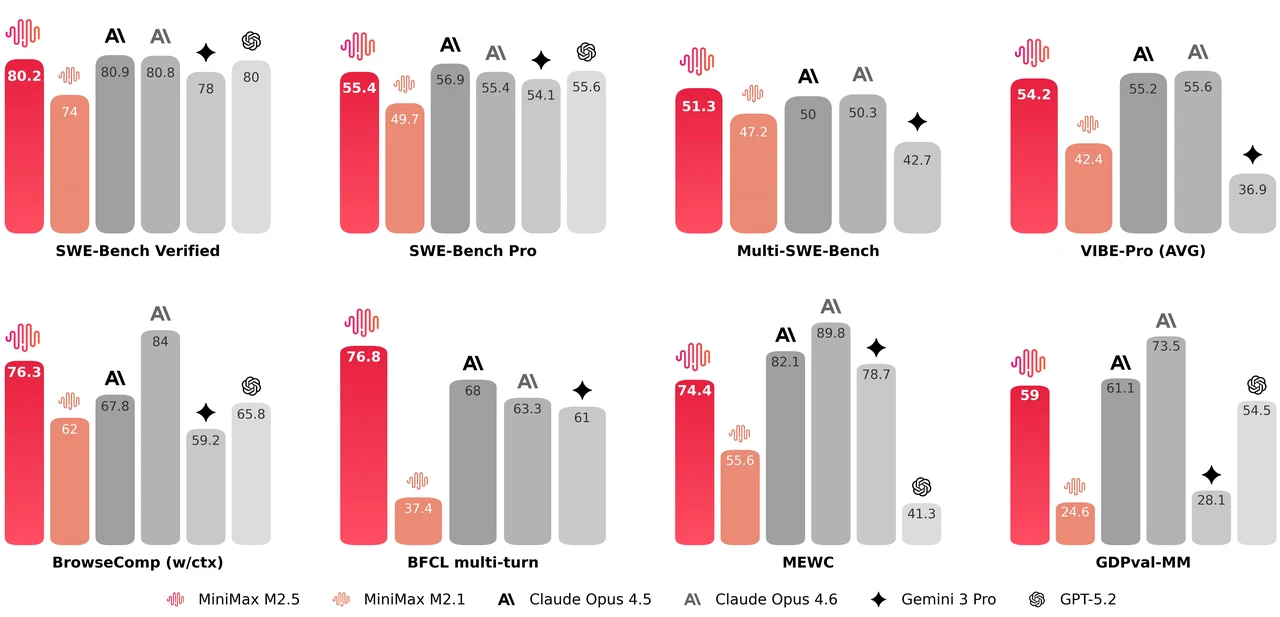
MiniMax M2.5 是擁有 2290 億參數的混合專家(MoE)模型,共 256 層專家層,每個 token 會啟動 8 個專家(約 100 億參數)。它在 SWE-Bench Verified 上獲得 80.2% 的分數、Multi-SWE-Bench 51.3%、BrowseComp 76.3%,是當前最強的开源代理編碼與工具使用模型之一。該模型支援 20.5 萬 token 的上下文視窗,並採用 MIT 授權,可無限制用於商業用途。
From Huggingface
From Huggingface
From Huggingface
MiniMax M2.5 的 VRAM 需求
VRAM 需求會隨精度等級而變化。下表列出 Unsloth 的 GGUF 量化與混合 AWQ 格式的檔案大小——根據上下文長度與批次大小,還需額外增加 4-10GB 的 KV 快取開銷。
| 配置 | 所需 VRAM |
|---|---|
| BF16(全精度) | 457 GB |
| Q8_0 GGUF | 243 GB |
| Q6_K GGUF | 188 GB |
| Q4_K_M GGUF | 138 GB |
| IQ4_XS GGUF | 122 GB |
| Q3_K_M GGUF(動態 3 位元) | 109 GB |
| Q2_K GGUF | 83 GB |
| UD-IQ2_XXS GGUF(超動態 2 位元) | 74 GB |
透過混合量化方案(INT4 AWQ 權重、FP8 注意力機制,以及校準過的 FP8 KV 快取),MiniMax M2.5 在 192GB VRAM 上可達到 37 萬 token 的上下文長度,且批次處理吞吐量遠高於標準 AWQ(標準 AWQ 通常會受到 KV 快取限制)。
MiniMax M2.5 的 GPU 建議配置
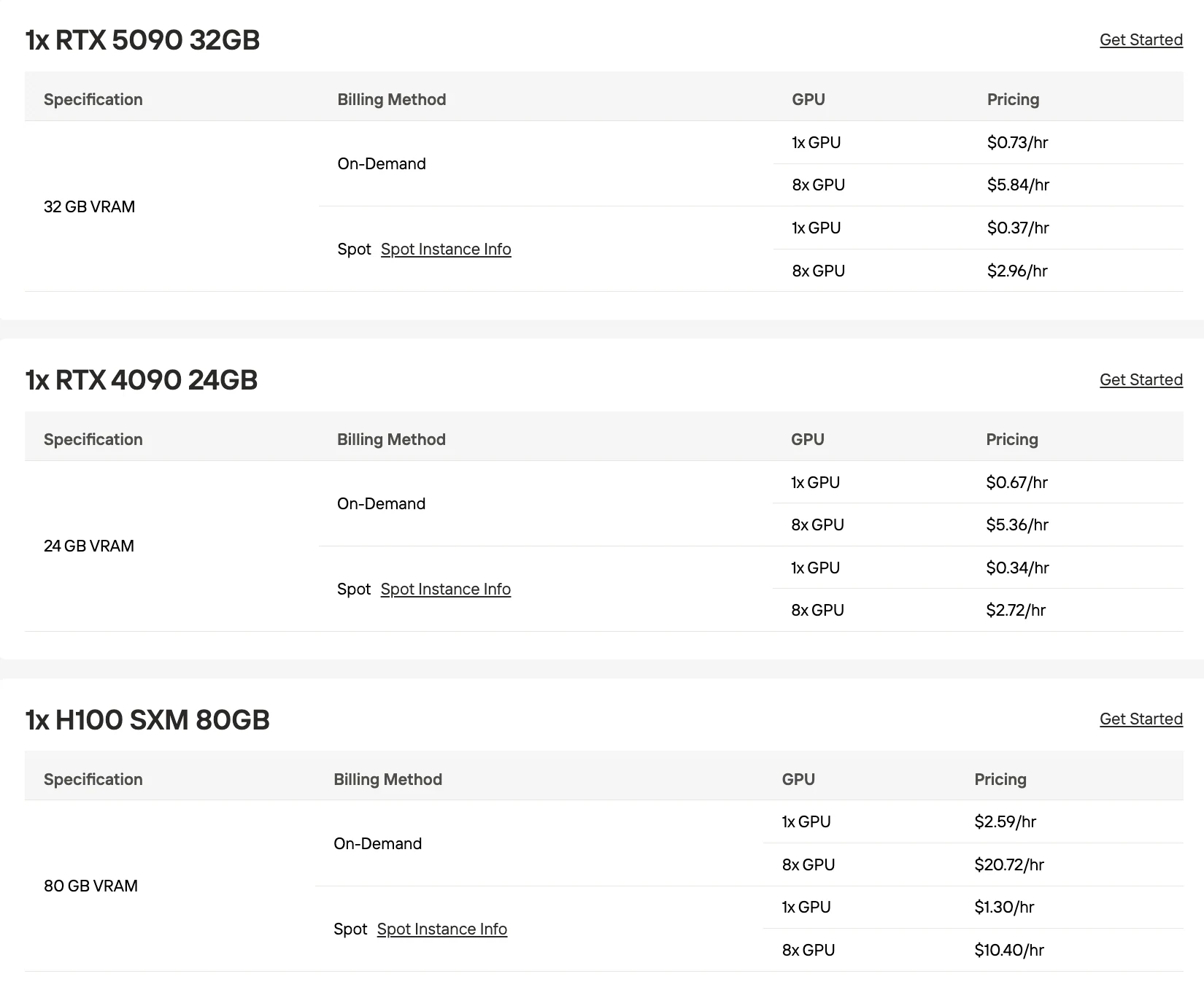
以下所有計價均為 Novita AI 隨需計費價格,多 GPU 成本計算方式為單 GPU 價格 × 數量。
RTX 5090 (32GB)
| 配置 | 總 VRAM | 量化方式 | 備註 |
|---|---|---|---|
| 3× RTX 5090 | 96GB | Q2_K | 可運行但會逼近記憶體極限 |
| 4× RTX 5090 | 128GB | Q3_K_M 動態 3 位元 | 搭配適中批次大小時運行穩定 |
H100 (80GB)
| 配置 | 總 VRAM | 量化方式 | 備註 |
|---|---|---|---|
| 2× H100 | 160GB | Q4_K_M | 運行穩定,模型品質更高 |
不建議使用: 單張 RTX 4090 或 RTX 5090 即便使用最激進的量化方式也無法容納 MiniMax M2.5。使用 Q3_K_M 量化的 Strix Halo APU 運行速度「幾乎無法使用」,雖能處理 8 萬 token 上下文,但推論速度不切實際。
https://www.reddit.com/r/LocalLLaMA/comments/1r8rgcp/minimax\_25\_on\_strix\_halo\_thread/
實際部署策略
策略一:優先使用 API,搭配 Spot GPU 故障轉移
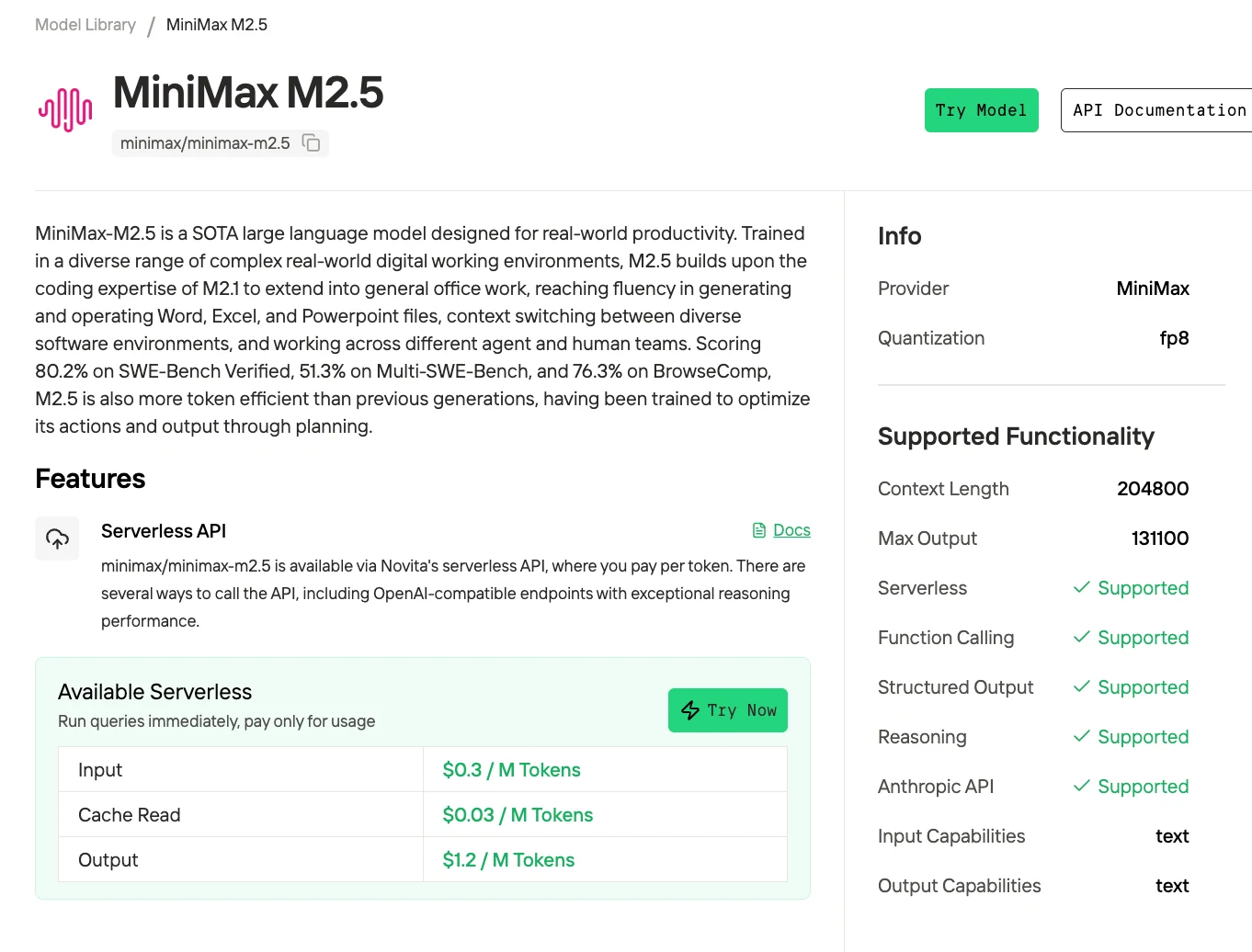
開發與輕量生產場景可優先使用 Novita AI API,計費為每 100 萬 token 0.3 美元/1.2 美元。當流量超過每月約 1 億 token(API 月成本約 150 美元)時,可啟動每小時 5.18 美元的2×H100 Spot 執行個體處理批次任務,同時保留 API 處理即時使用者面向的推論。這種混合方式能在控制成本的同時,維持互動應用的低延遲。
為進一步降低大規模使用成本,Novita 提供低價 API 計費,同時對重複讀取的提示快取提供折扣。當提示被重複使用時(例如系統指令、模板或重複上下文),快取中的 token 會以更低的費率提供,無需重新計算——同時降低延遲與成本。這種「優先 API + 批次處理」的架構效率更高,特別適合代理工作流程與高頻查詢場景。
策略二:搭配量化技術自主部署
對於有隱私需求或高流量持續運算的團隊,可部署在2×H100上運行 Q3_K_M 動態 3 位元或 Q4_K_M 量化版本。GGUF 格式可使用 llama.cpp 部署,生產環境吞吐量最佳化則可搭配 vLLM 與 AWQ 技術。
如何在雲端 GPU 上使用 MiniMax M2.5?
步驟 1:註冊帳號
透過我們的官方網站建立 Novita AI 帳號,註冊完成後,點擊左側邊欄的「探索」選項,即可查看我們的GPU 產品,開始你的 AI 開發之旅。

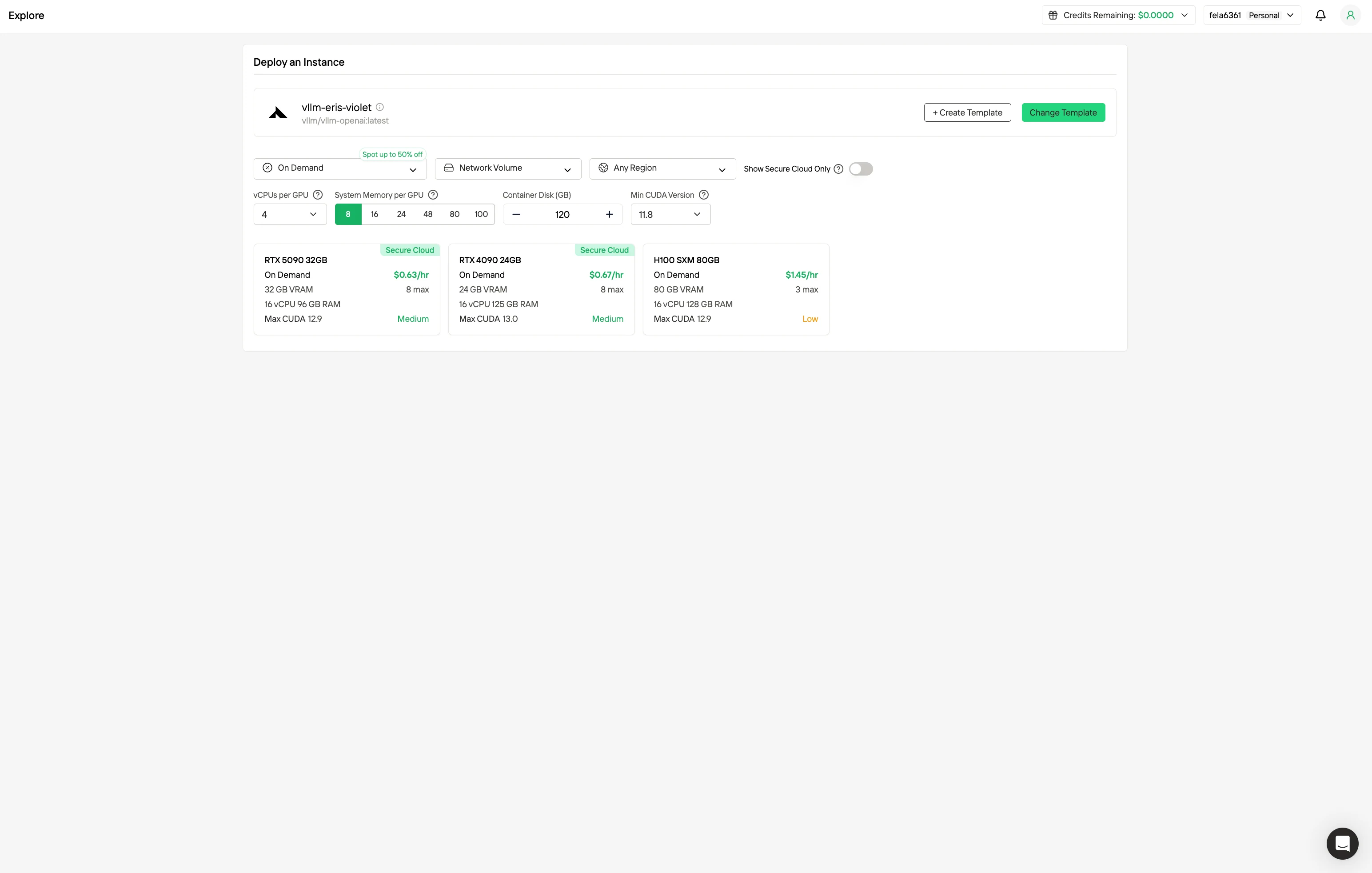
步驟 2:探索模板與 GPU 伺服器
根據專案需求選擇對應的模板,例如 PyTorch、TensorFlow 或 CUDA,接著選擇你偏好的 GPU 配置——我們提供多款高效能 GPU 選項,各自搭載不同的 VRAM、RAM 與儲存規格。
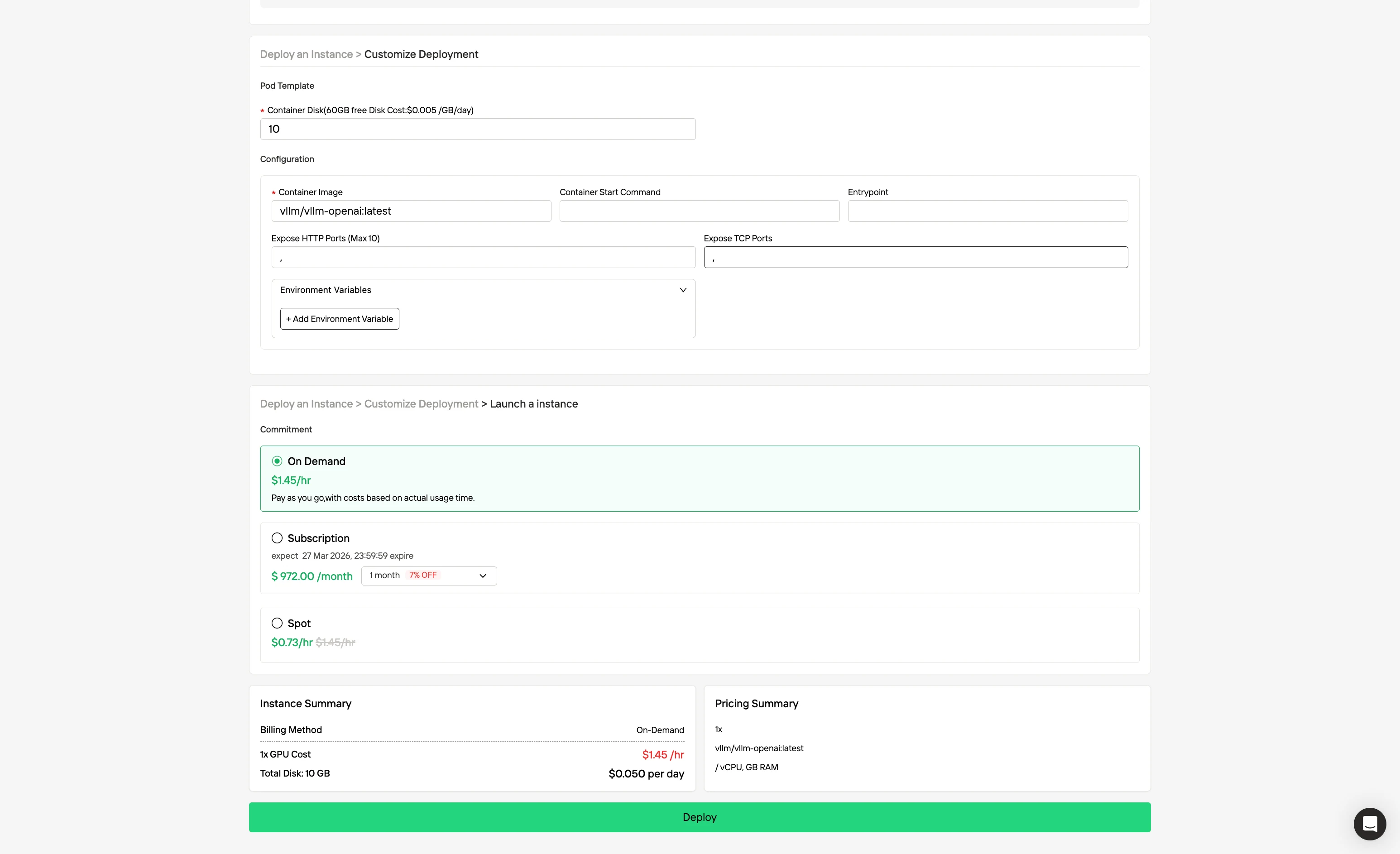
步驟 3:自訂你的部署環境
選擇你偏好的作業系統與配置選項,自訂你的部署環境,確保能為你的特定 AI 工作負載與開發需求發揮最佳效能。
MiniMax M2.5 的 2290 億參數 MoE 架構能提供頂尖的編碼效能,但 2 位元量化至少需要 96GB VRAM,生產級 3-4 位元部署則需要 128-160GB VRAM。對大多數開發者而言,在每月 5000 萬 token 以內的用量下,採用每 100 萬 token 0.3 美元/1.2 美元的 API 部署,是成本、效能與簡易性最佳平衡的方案。
常見問題
我可以在一張單獨的 RTX 4090 上運行 MiniMax M2.5 嗎?
不行,MiniMax M2.5 即便使用最激進的 UD-IQ2_XXS 2 位元量化,至少也需要 74GB VRAM。單張 RTX 4090 僅有 24GB VRAM,你至少需要 3-4 張消費級 GPU,或是 2 張 H100。
哪種量化等級能維持 MiniMax M2.5 的生產級輸出品質?
Q4_K_M(138GB)或動態 3 位元 Q3_K_M(109GB)是平衡性最佳的選擇。生產環境請避免使用 Q2_K(83GB)——儘管其上下文容量更高,但 Reddit 使用者回報其編碼品質會出現明顯下降。
MiniMax M2.5 的 API 計費方式是如何運作的?
使用 Novita 的計費方案(每 100 萬 token 0.3 美元/1.2 美元),每天處理 100 萬 token 的話,透過 API 每月成本約為 45 美元。
Novita AI 是 AI 與代理雲端平台,協助開發者與新創公司高效能、高可靠、低成本地建構、部署與擴展模型與代理應用程式。
推薦閱讀



