DeepSeek 正式展開了為期五天的開源釋出計劃,第一個亮相的項目是 FlashMLA。FlashMLA 是一個專為 NVIDIA Hopper GPU(例如 H800 SXM5)設計的最佳化、高效能 MLA 解碼核心。其主要目標是加速大型模型的運算,尤其是在 NVIDIA 高階 GPU 上提升效能。

作為領先的 AI 基礎設施供應商,Novita AI 率先在主流 Hopper GPU(H100、H200)上評估 FlashMLA 的效能表現。
什麼是 MLA?
在深入探討評估結果之前,我們先花點時間了解相關的背景概念。
-
Hopper GPU:NVIDIA 的次世代高效能 GPU 架構,專為 AI 與高效能運算(HPC)而設計。憑藉先進製程與創新架構,Hopper GPU 在複雜運算任務中提供卓越的效能與能源效率。主流的 Hopper GPU 包括 H100 與 H200。
-
解碼核心:專為加速解碼任務而設計的硬體或軟體模組。在 AI 推論中,解碼核心能顯著提升模型推論的速度與效率,特別是在處理序列資料時。
-
鍵值對(Key-Value, KV)
- 鍵(Key):
- 代表輸入資料的壓縮版本,用於計算注意力權重(決定關注輸入中哪些部分)。
- 範例:在文字生成時,鍵幫助模型識別句子中哪些詞彙與當前生成的詞彙最相關。
- 值(Value):
- 包含每個輸入 token 的實際資訊,並根據注意力權重進行加權。
- 範例:值儲存詞彙的語義,根據注意力權重組合後產生輸出。
- 鍵(Key):
-
MLA(多頭潛在注意力):一種新穎的注意力機制,需要更輕量的 KV(鍵值)快取,使其在長序列處理上更具可擴展性。MLA 在可擴展性與效能上皆優於傳統的多頭注意力(MHA)機制。
MHA 與 MQA 與 GQA 與 MLA 的比較
| **模組 ** | ** 技術邏輯 ** | ** 推論速度 ** | ** 模型效能** |
|---|---|---|---|
| MHA | 多個頭獨立產生鍵與值,無共享(全維度運算)。 | ⭐️ | ⭐️⭐️⭐️ |
| MQA | 所有查詢頭共享單一鍵值對(單一 KV 組)。 | ⭐️⭐️⭐️ | ⭐️ |
| GQA | 查詢頭以分組方式共享鍵值對(多個 KV 組)。 | ⭐️⭐️ | ⭐️⭐️ |
| MLA | 將鍵值對壓縮為低維度潛在向量,並透過解耦的 RoPE 解碼以保留位置資訊。 | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA:是 MHA 的「簡化版」,專注於效率,但以資訊損失為代價。
- MLA:一個「升級版的壓縮版本」,在記憶體效率與資訊保留之間取得平衡,甚至超越 MHA 的表現。
- 架構創新:MLA 並非單純的最佳化,而是對注意力機制的重新構想,利用潛在變數從數學上重建注意力。它實現了效率與能力的雙贏。
Novita AI 對 FlashMLA 的效能評估
DeepSeek 宣布 FlashMLA 在 H800 SXM5 GPU 上可達到 **3000 GB/s 的記憶體頻寬極限 ** 與 **580 TFLOPS 的運算極限 。為了驗證這些數據,Novita AI ** 進行了全面評估,在不同參數設定下測試 FlashMLA。
為了更直觀地呈現結果,效能圖表中的橫軸代表以下參數配置:
- 批次大小
- 序列長度
- 注意力頭數
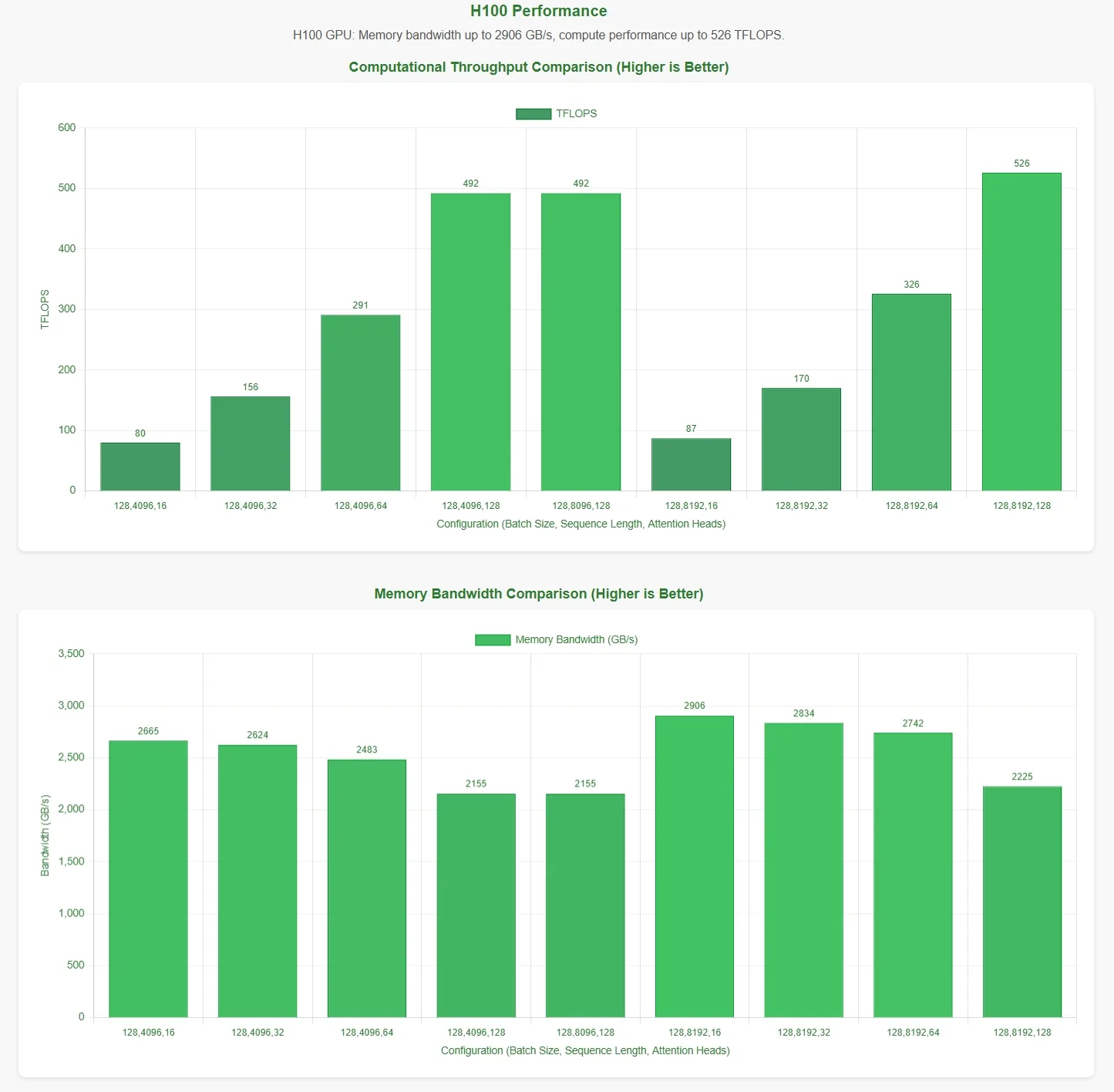
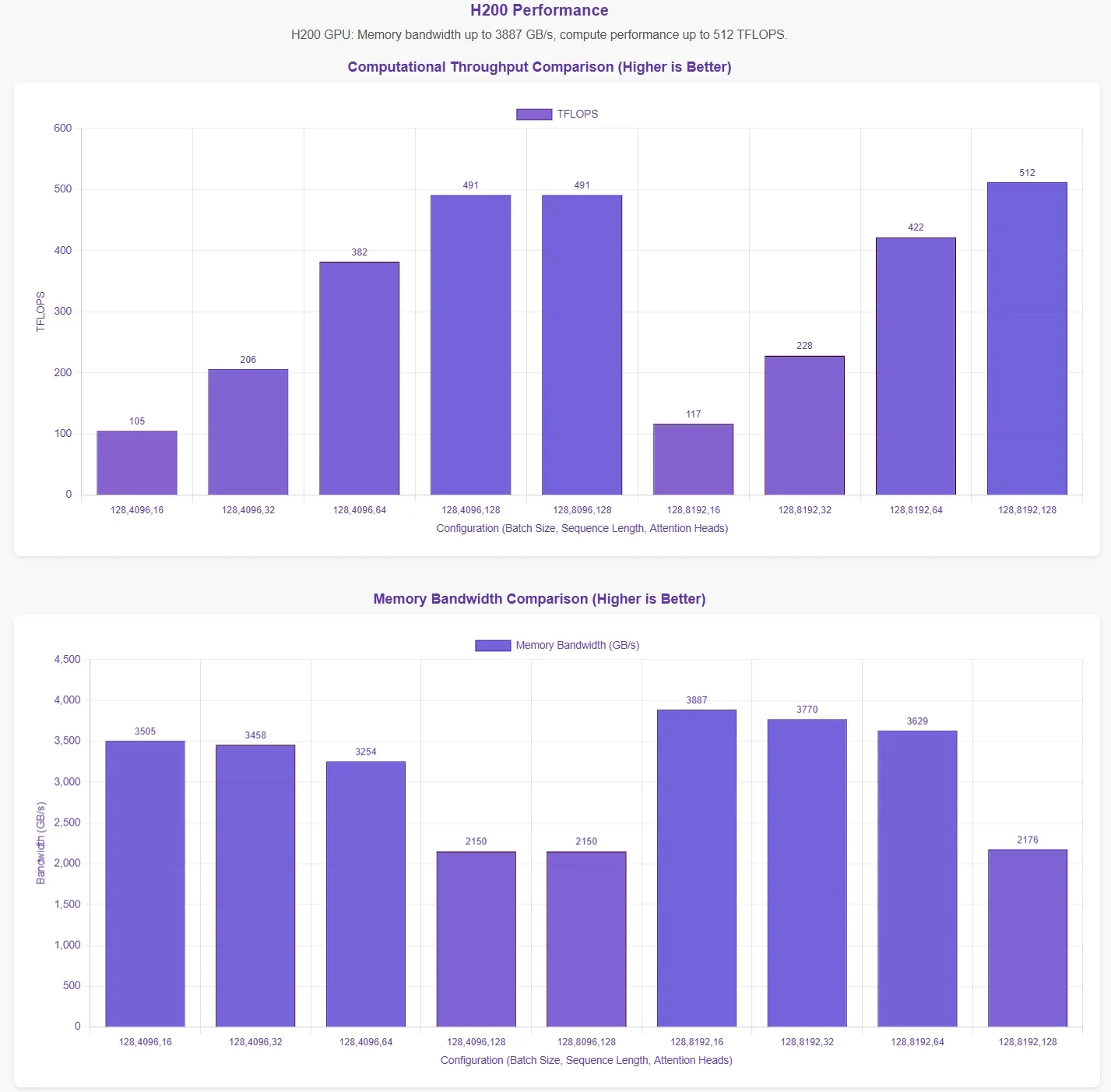
備註
這些結果是基於官方測試腳本。由於未掌握最佳參數配置,數據可能無法完全反映理論最大值。
FlashMLA 將帶來什麼影響?
FlashMLA 的發布不僅引起了開發者的興趣,也獲得了主流推論框架 vLLM 與 SGLang 的正面回應。
- vLLM 整合:
vLLM 團隊已宣布計劃盡快整合 FlashMLA。從技術上來說,FlashMLA 基於 PagedAttention,因此與 vLLM 的技術棧高度相容。整合後,FlashMLA 有望進一步提升 vLLM 的推論效能。 - SGLang 採用:
SGLang 將繼續使用已整合的 FlashInferMLA,經評估其效能與 FlashMLA 相當。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 輕鬆部署 AI 模型,同時也提供經濟實惠且可靠的 GPU 雲端服務,用於建構與擴展。