

Компания DeepSeek официально запустила пятидневную инициативу по выпуску open-source проектов, и первым представленным проектом стал FlashMLA. FlashMLA — это оптимизированное, высокоэффективное ядро декодирования MLA, специально разработанное для графических процессоров NVIDIA Hopper (например, H800 SXM5). Его основная цель — ускорить вычисления для крупномасштабных моделей, особенно повышая производительность на высококлассных GPU NVIDIA.

Будучи ведущим поставщиком AI-инфраструктуры, Novita AI одной из первых оценила производительность FlashMLA на основных GPU Hopper (H100, H200).
Что такое MLA?
Прежде чем перейти к результатам оценки, давайте кратко разберём соответствующие базовые понятия.
- GPU Hopper: высокопроизводительная архитектура GPU следующего поколения от NVIDIA, разработанная для искусственного интеллекта и высокопроизводительных вычислений (HPC). Благодаря передовым технологиям производства и инновационной архитектуре, GPU Hopper обеспечивают исключительную производительность и энергоэффективность при решении сложных вычислительных задач. Основные модели GPU Hopper — H100 и H200.
- Ядро декодирования: аппаратный или программный модуль, специально предназначенный для ускорения задач декодирования. В AI-инференсе ядра декодирования значительно повышают скорость и эффективность инференса моделей, особенно при обработке последовательных данных.
- Пары ключ-значение (KV):
- Key (ключ):
- Представляет сжатую версию входных данных, используемую для вычисления весов внимания (насколько сильно модель фокусируется на различных частях входных данных).
- Пример: при генерации текста ключи помогают модели определить, какие слова в предложении наиболее релевантны текущему генерируемому слову.
- Value (значение):
- Содержит фактическую информацию, связанную с каждым входным токеном, взвешенную по оценкам внимания.
- Пример: значения хранят семантический смысл слов, которые комбинируются на основе весов внимания для получения выходных данных.
- Key (ключ):
- MLA (Multi-head Latent Attention): новый механизм внимания, требующий более лёгкого кэширования KV (ключ-значение), что делает его более масштабируемым для обработки длинных последовательностей. MLA превосходит традиционные механизмы Multi-Head Attention (MHA) как по масштабируемости, так и по производительности.
MHA vs MQA vs GQA vs MLA
| Модуль | Техническая логика | Скорость инференса | Производительность модели |
|---|---|---|---|
| MHA | Несколько головок независимо генерируют ключи и значения, без разделения (полноразмерные вычисления). | ⭐️ | ⭐️⭐️⭐️ |
| MQA | Все головки запросов разделяют одну пару ключ-значение (одна группа KV). | ⭐️⭐️⭐️ | ⭐️ |
| GQA | Головки запросов разделяют пары ключ-значение группами (несколько групп KV). | ⭐️⭐️ | ⭐️⭐️ |
| MLA | Пары ключ-значение сжимаются в низкоразмерные латентные векторы и декодируются с использованием развязанного RoPE для сохранения позиционной информации. | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA: «упрощённая версия» MHA, ориентированная на эффективность ценой потери информации.
- MLA: «улучшенная сжатая версия», которая балансирует между эффективностью памяти и сохранением информации, даже превосходя MHA.
- Архитектурная инновация: MLA — это не просто оптимизация, а переосмысление механизмов внимания, использующее латентные переменные для их математической реконструкции. Он достигает наилучшего из двух миров: эффективности и производительности.
Оценка производительности FlashMLA от Novita AI
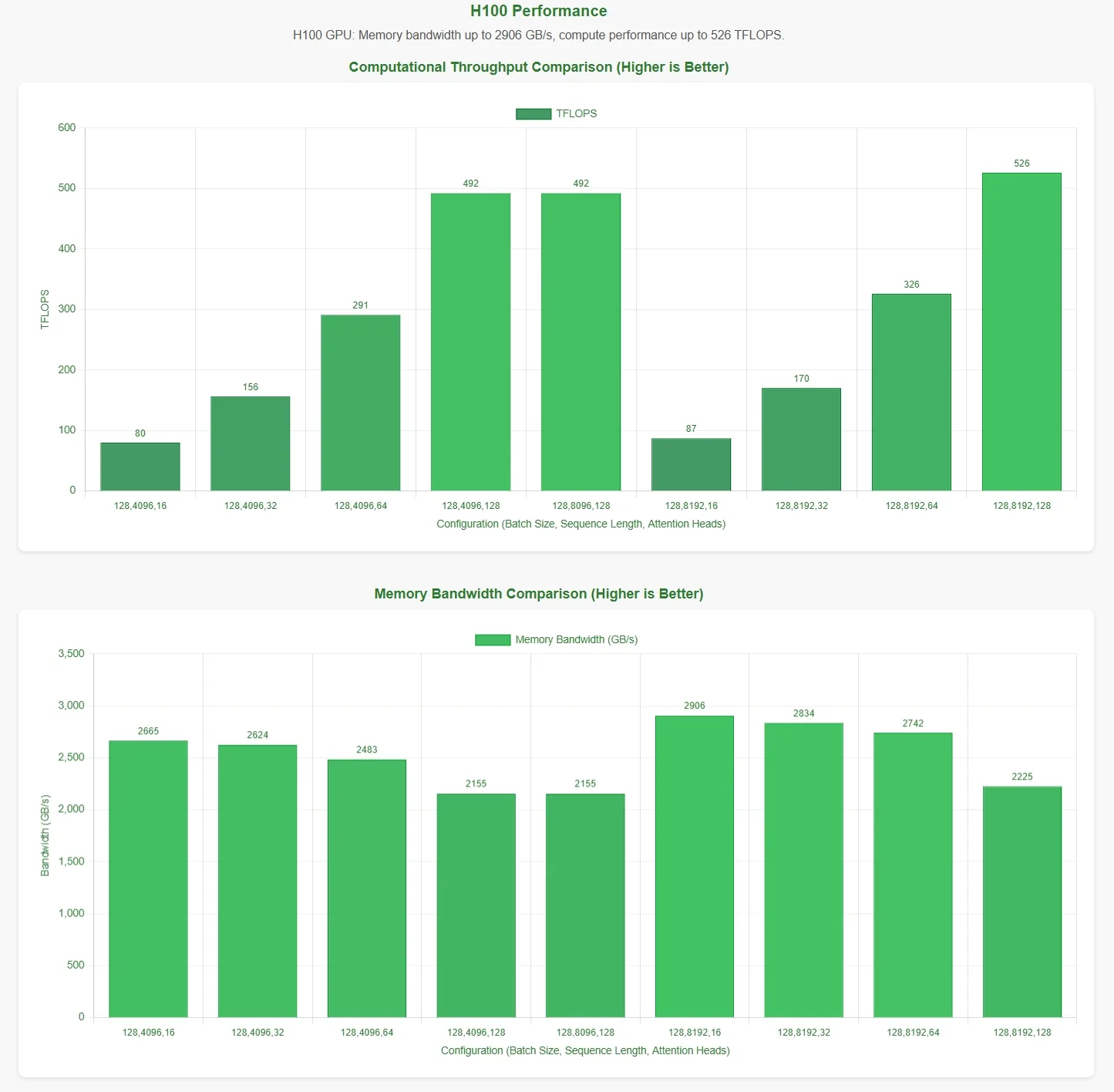
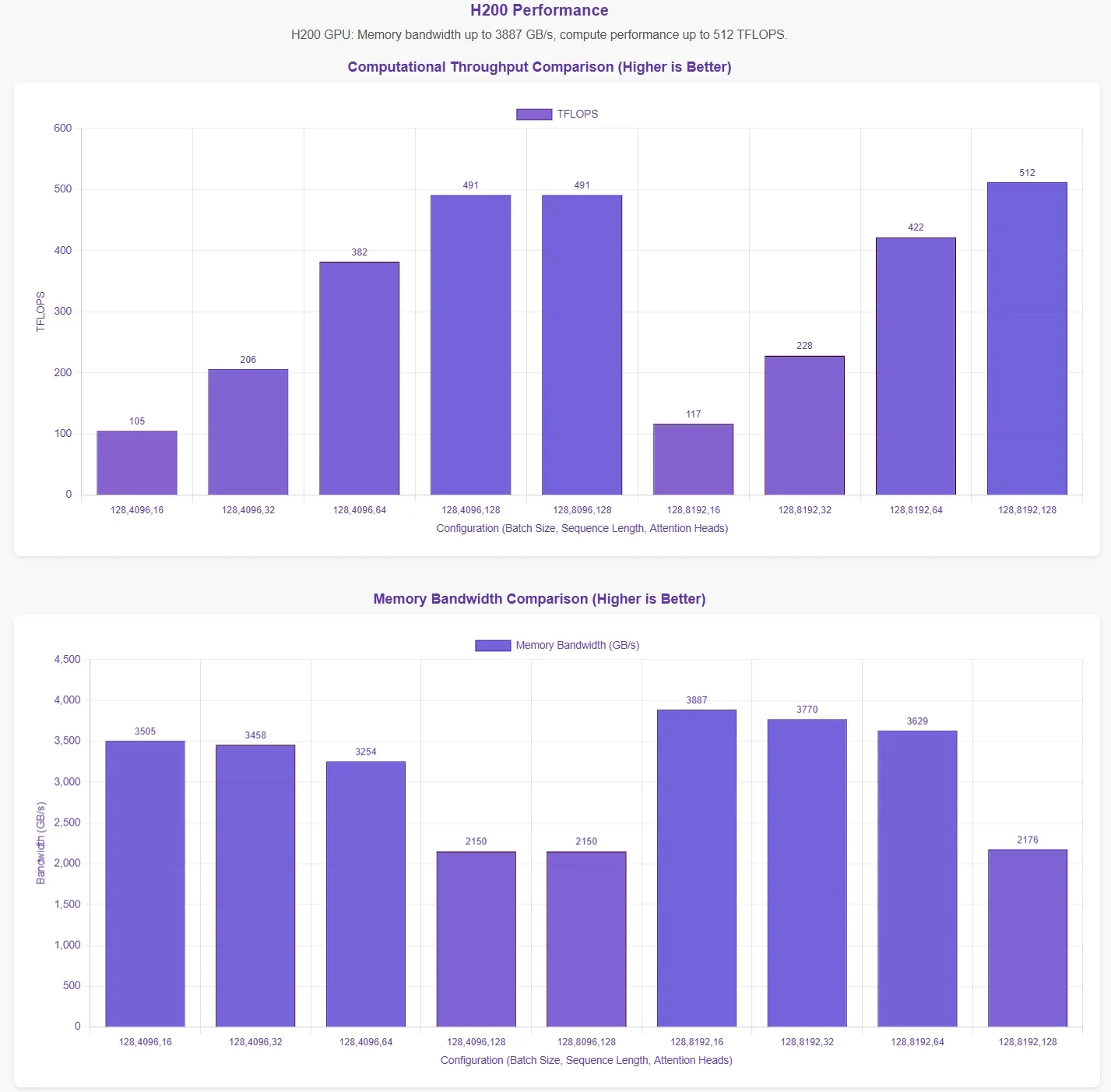
DeepSeek заявил, что FlashMLA достигает предела пропускной способности памяти 3000 ГБ/с и вычислительного предела 580 TFLOPS на GPU H800 SXM5. Чтобы проверить эти утверждения, Novita AI провела всестороннюю оценку, протестировав FlashMLA при различных конфигурациях параметров.
Для более наглядного представления результатов на горизонтальной оси графиков производительности указаны следующие конфигурации параметров:
- Размер батча
- Длина последовательности
- Количество головок внимания
Примечание
Эти результаты получены с помощью официальных тестовых скриптов. Без знания оптимальных конфигураций параметров данные могут не полностью отражать теоретические максимумы.
Какое влияние окажет FlashMLA?
Релиз FlashMLA не только привлёк внимание разработчиков, но и получил положительный отклик от ведущих фреймворков инференса — vLLM и SGLang.
- Интеграция с vLLM:
Команда vLLM объявила о планах в ближайшее время интегрировать FlashMLA. Технически FlashMLA построен на PagedAttention, что делает его высокосовместимым с технологическим стеком vLLM. После интеграции ожидается, что FlashMLA дополнительно повысит производительность инференса vLLM. - Принятие в SGLang:
SGLang продолжит использовать уже интегрированный FlashInferMLA, который, по оценкам, обеспечивает производительность, сопоставимую с FlashMLA.
Novita AI — это облачная AI-платформа, которая предоставляет разработчикам простой способ развёртывания AI-моделей через наш простой API, а также предлагает доступное и надёжное облако GPU для масштабирования.
Получите $20 кредитов и попробуйте DeepSeek прямо сейчас!



