

DeepSeekは、5日間にわたるオープンソース公開イニシアチブを正式に開始し、最初のプロジェクトとして FlashMLA を公開しました。FlashMLAは、NVIDIA Hopper GPU(例:H800 SXM5)向けに特別に設計された、最適化された高効率なMLAデコーディングカーネルです。その主な目的は、大規模モデルの計算を高速化し、特にNVIDIAのハイエンドGPUでのパフォーマンスを向上させることです。

AIインフラストラクチャの主要プロバイダーとして、Novita AIは最初にメインストリームのHopper GPU(H100、H200)でFlashMLAのパフォーマンスを評価しました。
MLAとは?
評価結果に入る前に、関連する背景概念を簡単に理解しておきましょう。
-
Hopper GPU:NVIDIAの次世代高性能GPUアーキテクチャで、AIおよびハイパフォーマンスコンピューティング(HPC)向けに設計されています。高度なプロセス技術と革新的なアーキテクチャにより、Hopper GPUは複雑な計算タスクにおいて卓越したパフォーマンスとエネルギー効率を実現します。主流のHopper GPUにはH100とH200があります。
-
デコーディングカーネル:デコーディングタスクを加速するために特別に設計されたハードウェアまたはソフトウェアモジュール。AI推論において、デコーディングカーネルは、特にシーケンシャルデータを処理する際に、モデル推論の速度と効率を大幅に向上させます。
-
キー・バリュー(KV)ペア
- キー:
- 入力データの圧縮表現を表し、注意重み(入力のさまざまな部分にどれだけ焦点を当てるか)を計算するために使用されます。
- 例:テキスト生成では、キーはモデルが現在生成中の単語に対して、文中で最も関連性の高い単語を識別するのに役立ちます。
- バリュー:
- 各入力トークンに関連付けられた実際の情報を含み、注意スコアによって重み付けされます。
- 例:バリューは単語の意味内容を格納し、注意重みに基づいて結合されて出力を生成します。
- キー:
-
MLA(マルチヘッド潜在注意):より軽量なKV(キー・バリュー)キャッシュを必要とする新しい注意機構で、長いシーケンス処理に対してよりスケーラブルです。MLAは、従来のマルチヘッド注意(MHA)機構よりもスケーラビリティとパフォーマンスの両方で優れています。
MHA 対 MQA 対 GQA 対 MLA
| **モジュール ** | ** 技術的ロジック ** | ** 推論速度 ** | ** モデル性能** |
|---|---|---|---|
| MHA | 複数のヘッドが独立してキーとバリューを生成し、共有はありません(全次元の計算)。 | ⭐️ | ⭐️⭐️⭐️ |
| MQA | すべてのクエリヘッドが単一のキー・バリューペアを共有します(単一のKVグループ)。 | ⭐️⭐️⭐️ | ⭐️ |
| GQA | クエリヘッドがグループでキー・バリューペアを共有します(複数のKVグループ)。 | ⭐️⭐️ | ⭐️⭐️ |
| MLA | キー・バリューペアを低次元の潜在ベクトルに圧縮し、分離されたRoPEでデコードして位置情報を保持します。 | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA:MHAの「簡易版」、情報損失を犠牲にして効率を重視。
- MLA:メモリ効率と情報保持のバランスをとる「アップグレードされた圧縮版」、MHAをも上回る。
- アーキテクチャの革新:MLAは単なる最適化ではなく、注意機構の再考であり、潜在変数を使用して数学的に再構築します。効率性と能力の両方の長所を実現します。
Novita AIによるFlashMLAのパフォーマンス評価
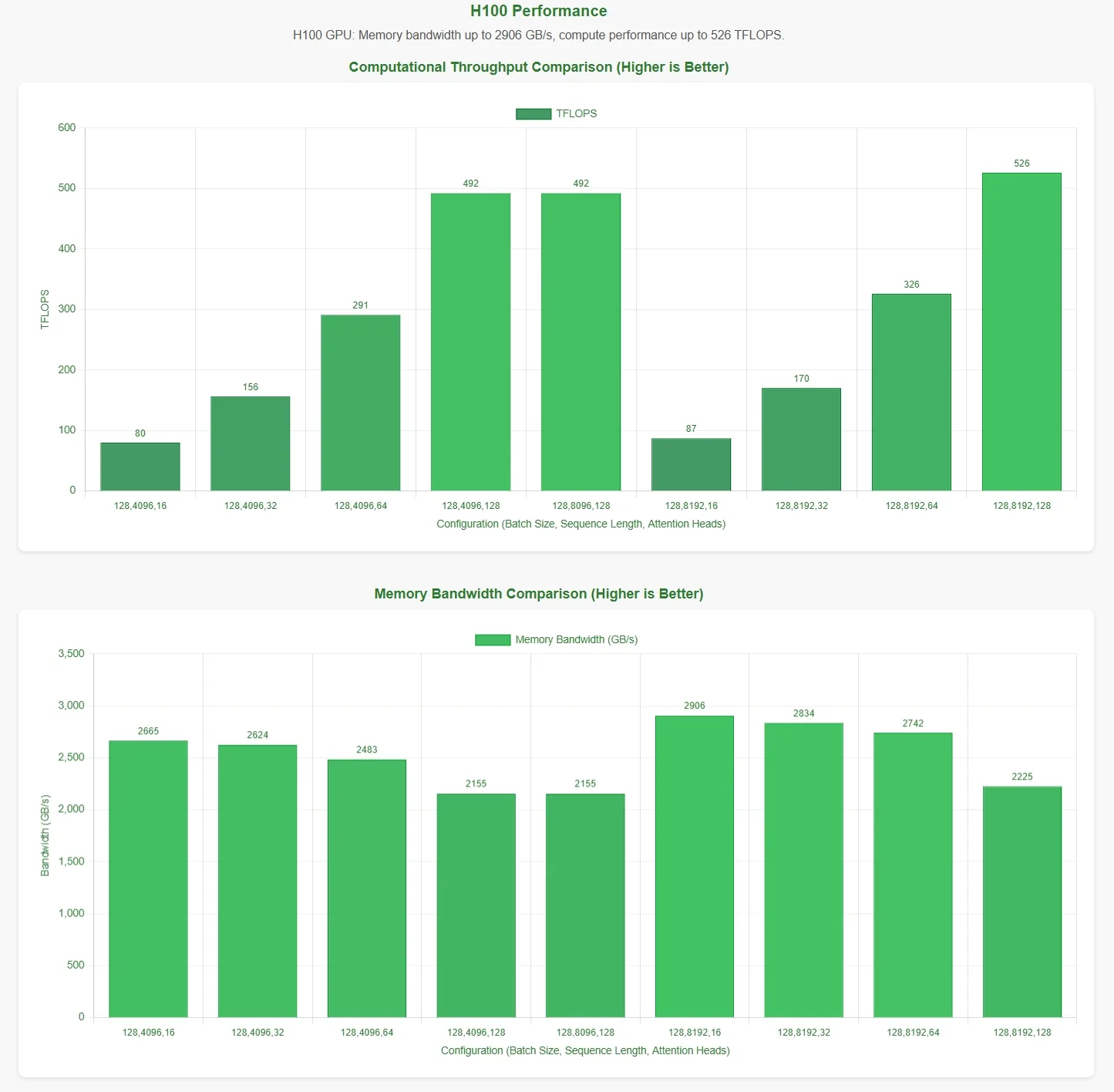
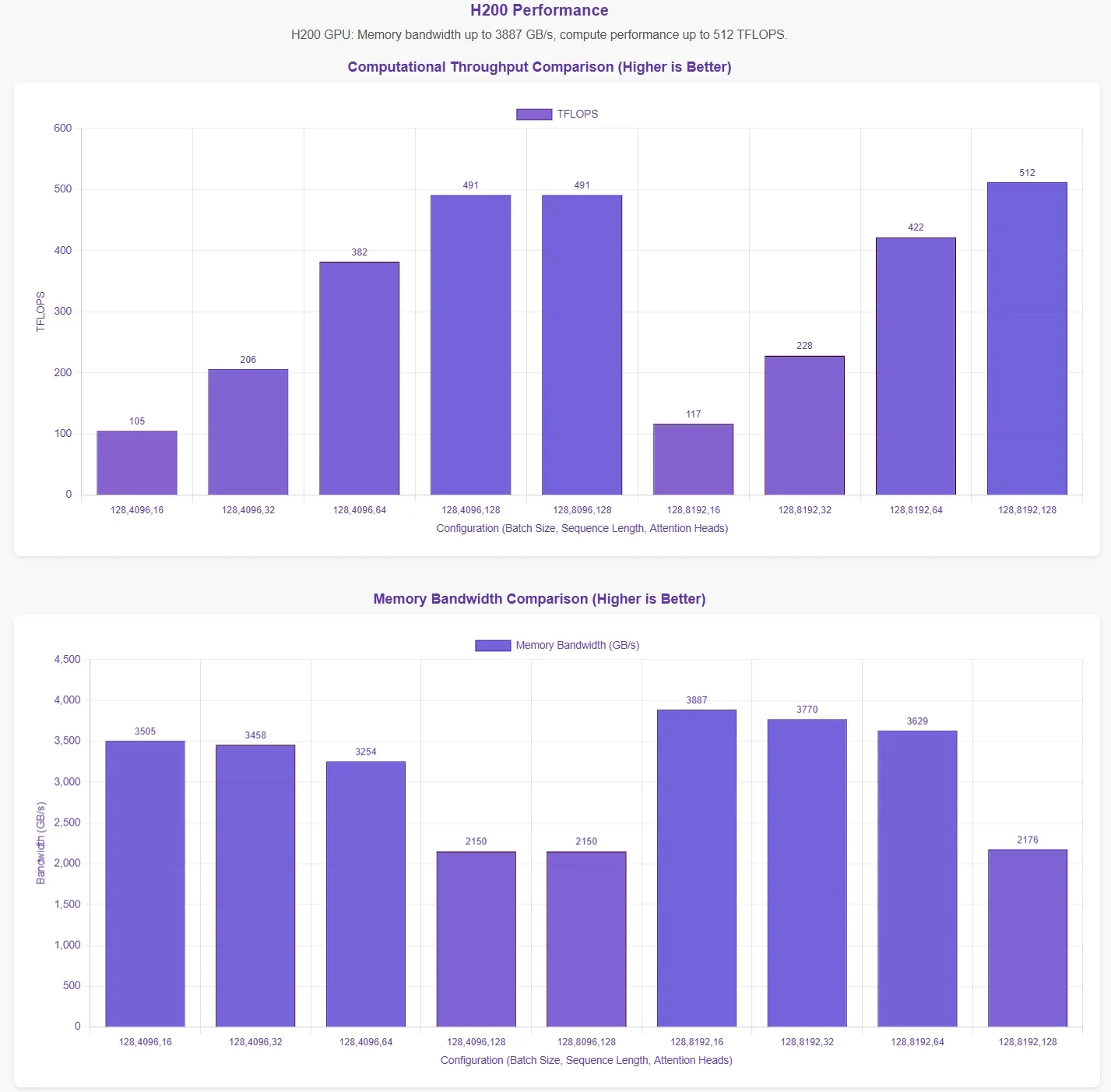
DeepSeekは、FlashMLAがH800 SXM5 GPU上で メモリ帯域幅の限界3000 GB/s と ** 計算限界580 TFLOPS** を達成すると発表しました。これらの主張を検証するために、Novita AI は ** 包括的な評価を実施** し、さまざまなパラメータ構成でFlashMLAをテストしました。
結果をより直感的に提示するために、パフォーマンスチャートの横軸は以下のパラメータ構成を表しています。
- バッチサイズ
- シーケンス長
- 注意ヘッド数
注記
これらの結果は公式テストスクリプトに基づいています。最適なパラメータ構成が不明なため、データが理論上の最大値を完全に反映していない可能性があります。
FlashMLAはどのような影響をもたらすか?
FlashMLAのリリースは開発者の関心を集めただけでなく、メインストリームの推論フレームワークである vLLM と SGLang からも肯定的な反応を得ています。
- vLLM統合:
vLLMチームは、近いうちにFlashMLAを統合する計画を発表しました。技術的には、FlashMLAは PagedAttention に基づいて構築されており、vLLMの技術スタックとの互換性が非常に高いです。統合されれば、FlashMLAはvLLMの推論パフォーマンスをさらに向上させることが期待されます。 - SGLang採用:
SGLangは、すでに統合されている FlashInferMLA を引き続き利用します。このFlashInferMLAは、FlashMLAと同等のパフォーマンスを提供することが評価されています。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできると同時に、手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。
今すぐ$20クレジットを入手してDeepSeekをお試しください!



