

DeepSeek가 공식적으로 5일간의 오픈소스 릴리스 이니셔티브를 시작했으며, 첫 번째로 소개된 프로젝트는 FlashMLA 입니다. FlashMLA는 NVIDIA Hopper GPU(예: H800 SXM5)를 위해 특별히 설계된 최적화된 고효율 MLA 디코딩 커널입니다. 주요 목표는 대규모 모델의 계산을 가속화하며, 특히 NVIDIA의 고급 GPU에서 성능을 향상시키는 것입니다.

AI 인프라의 선두 제공업체로서 Novita AI는 FlashMLA의 성능을 주류 Hopper GPU(H100, H200)에서 최초로 평가했습니다.
MLA란 무엇인가요?
평가 결과를 살펴보기 전에 관련 배경 개념을 잠시 이해해 보겠습니다.
-
Hopper GPU: NVIDIA의 차세대 고성능 GPU 아키텍처로, AI 및 고성능 컴퓨팅(HPC)을 위해 설계되었습니다. 첨단 공정 기술과 혁신적인 아키텍처를 기반으로 구축된 Hopper GPU는 복잡한 계산 작업에서 탁월한 성능과 에너지 효율성을 제공합니다. 주류 Hopper GPU에는 H100과 H200이 포함됩니다.
-
디코딩 커널: 디코딩 작업을 가속화하기 위해 특별히 설계된 하드웨어 또는 소프트웨어 모듈입니다. AI 추론에서 디코딩 커널은 특히 순차 데이터 처리 시 모델 추론의 속도와 효율성을 크게 향상시킵니다.
-
Key-Value(KV) 페어
- Key:
- 입력 데이터의 압축된 버전을 나타내며, 어텐션 가중치(입력의 여러 부분에 얼마나 집중할지 계산)를 계산하는 데 사용됩니다.
- 예: 텍스트 생성에서 키는 모델이 문장에서 현재 생성 중인 단어와 가장 관련 있는 단어를 식별하는 데 도움을 줍니다.
- Value:
- 각 입력 토큰과 관련된 실제 정보를 포함하며, 어텐션 점수에 따라 가중치가 부여됩니다.
- 예: 값은 단어의 의미적 의미를 저장하며, 어텐션 가중치에 따라 결합되어 출력을 생성합니다.
- Key:
-
MLA(Multi-head Latent Attention): 더 가벼운 KV(키-값) 캐싱이 필요한 새로운 어텐션 메커니즘으로, 긴 시퀀스 처리에 더 확장 가능합니다. MLA는 확장성과 성능 모두에서 전통적인 MHA(Multi-Head Attention) 메커니즘보다 뛰어납니다.
MHA vs MQA vs GQA vs MLA
| **모듈 ** | ** 기술적 로직 ** | ** 추론 속도 ** | ** 모델 성능** |
|---|---|---|---|
| MHA | 여러 헤드가 독립적으로 키와 값을 생성하며 공유하지 않음(전체 차원 계산). | ⭐️ | ⭐️⭐️⭐️ |
| MQA | 모든 쿼리 헤드가 단일 키-값 쌍을 공유(단일 KV 그룹). | ⭐️⭐️⭐️ | ⭐️ |
| GQA | 쿼리 헤드가 그룹 단위로 키-값 쌍을 공유(여러 KV 그룹). | ⭐️⭐️ | ⭐️⭐️ |
| MLA | 키-값 쌍을 저차원 잠재 벡터로 압축하고, 분리된 RoPE를 사용하여 디코딩하여 위치 정보를 유지. | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA: MHA의 "단순화된 버전"으로, 정보 손실을 감수하면서 효율성에 중점을 둠.
- MLA: 메모리 효율성과 정보 보존의 균형을 맞추는 "업그레이드된 압축 버전"으로, MHA를 능가하기도 함.
- 아키텍처 혁신: MLA는 단순한 최적화가 아니라 잠재 변수를 활용하여 수학적으로 어텐션 메커니즘을 재구성한 것입니다. 효율성과 성능이라는 두 마리 토끼를 모두 잡습니다.
Novita AI의 FlashMLA 성능 평가
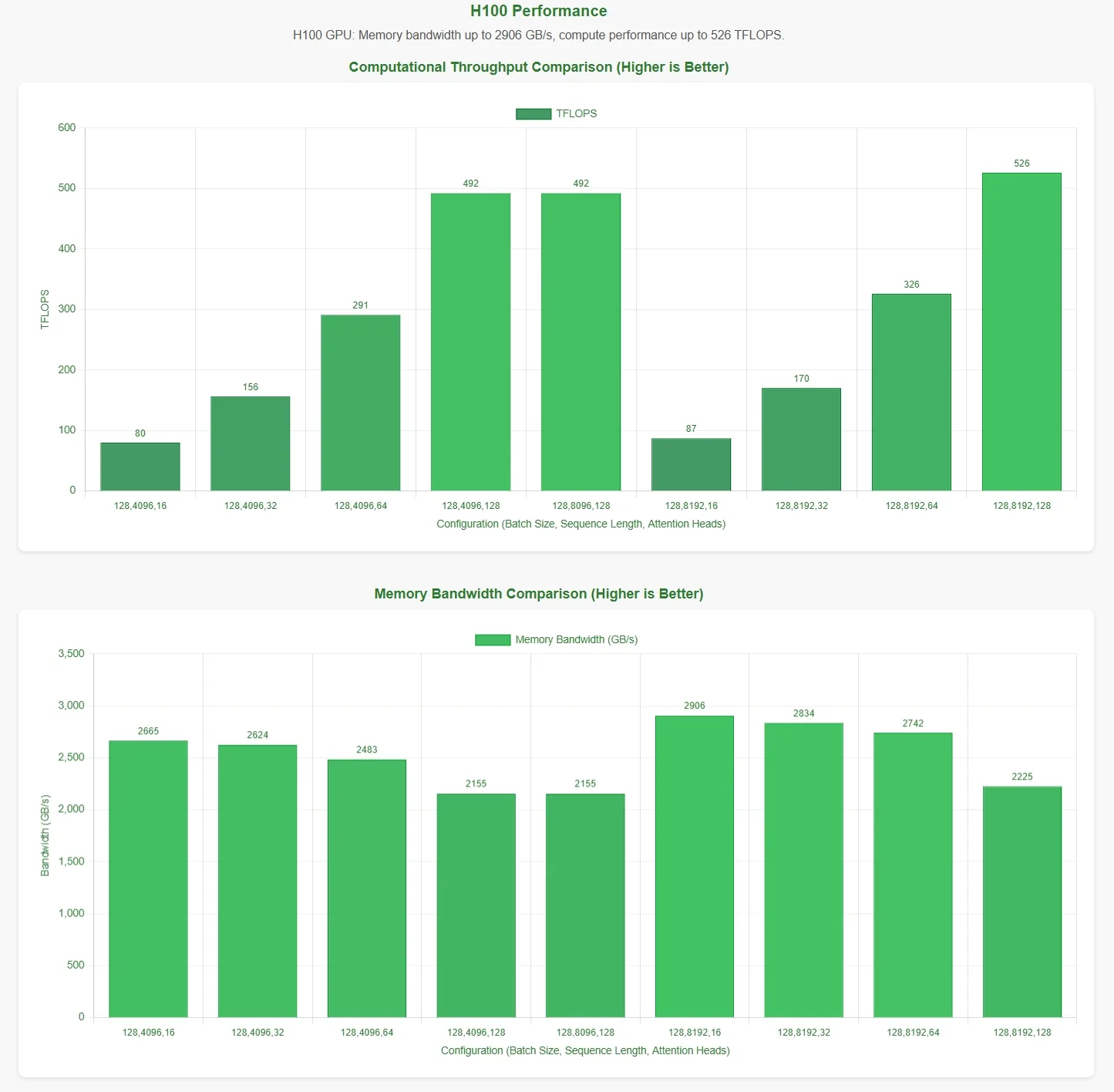
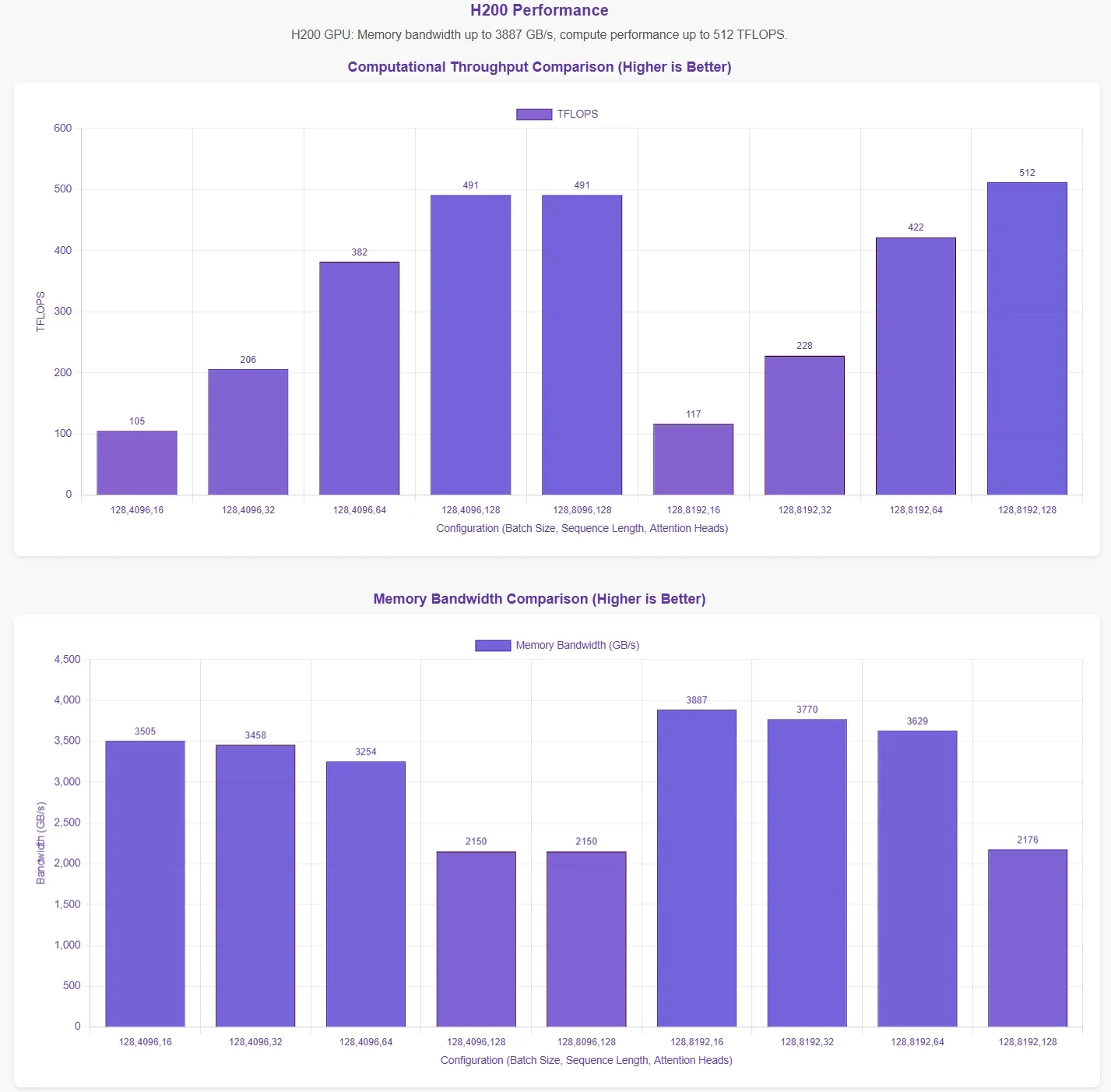
DeepSeek는 FlashMLA가 H800 SXM5 GPU에서 메모리 대역폭 한계 3000 GB/s 및 ** 컴퓨트 한계 580 TFLOPS**를 달성한다고 발표했습니다. 이러한 주장을 검증하기 위해 Novita AI 는 다양한 매개변수 구성에서 FlashMLA를 테스트하는 포괄적인 평가 를 수행했습니다.
결과를 더 직관적으로 표시하기 위해 성능 차트의 가로축은 다음 매개변수 구성을 나타냅니다.
- 배치 크기
- 시퀀스 길이
- 어텐션 헤드 수
참고
이 결과는 공식 테스트 스크립트를 기반으로 합니다. 최적의 매개변수 구성에 대한 정보 없이 데이터는 이론적 최대치를 완전히 반영하지 못할 수 있습니다.
FlashMLA의 영향은 무엇일까요?
FlashMLA의 출시는 개발자들의 관심을 끌었을 뿐만 아니라 주류 추론 프레임워크인 vLLM 과 SGLang 의 긍정적인 반응을 얻었습니다.
- vLLM 통합: vLLM 팀은 FlashMLA를 곧 통합할 계획이라고 발표했습니다. 기술적으로 FlashMLA는 PagedAttention 을 기반으로 구축되어 vLLM의 기술 스택과 높은 호환성을 제공합니다. 통합되면 FlashMLA는 vLLM의 추론 성능을 더욱 향상시킬 것으로 예상됩니다.
- SGLang 도입: SGLang은 이미 통합된 FlashInferMLA 를 계속 사용할 예정이며, 이는 FlashMLA와 비슷한 성능을 제공하는 것으로 평가되었습니다.
Novita AI는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 지원하는 AI 클라우드 플랫폼으로, 확장 및 구축을 위한 저렴하고 안정적인 GPU 클라우드도 제공합니다.
지금 $20 크레딧을 받고 DeepSeek를 사용해 보세요!



