

DeepSeek a officiellement lancé son initiative de publication open source sur cinq jours, le premier projet présenté étant FlashMLA. FlashMLA est un noyau de décodage MLA optimisé et à haute efficacité, spécialement conçu pour les GPU NVIDIA Hopper (par exemple, H800 SXM5). Son objectif principal est d’accélérer les calculs pour les modèles à grande échelle, en améliorant particulièrement les performances sur les GPU haut de gamme de NVIDIA.

En tant que fournisseur leader d’infrastructure IA, Novita AI a été parmi les premiers à évaluer les performances de FlashMLA sur les GPU Hopper grand public (H100, H200).
Qu’est-ce que MLA ?
Avant de plonger dans les résultats de l’évaluation, prenons un moment pour comprendre certains concepts de base pertinents.
-
GPU Hopper : l’architecture GPU haute performance de nouvelle génération de NVIDIA, conçue pour l’IA et le calcul haute performance (HPC). Construits avec des procédés de fabrication avancés et une architecture innovante, les GPU Hopper offrent des performances exceptionnelles et une efficacité énergétique pour les tâches de calcul complexes. Les GPU Hopper grand public incluent le H100 et le H200.
-
Noyau de décodage : un module matériel ou logiciel spécialement conçu pour accélérer les tâches de décodage. Dans l’inférence IA, les noyaux de décodage améliorent considérablement la vitesse et l’efficacité de l’inférence des modèles, en particulier lors du traitement de données séquentielles.
-
Paires clé-valeur (KV)
- Clé :
- Représente une version compressée des données d’entrée, utilisée pour calculer les poids d’attention (le degré d’attention à accorder aux différentes parties de l’entrée).
- Exemple : dans la génération de texte, les clés aident le modèle à identifier quels mots d’une phrase sont les plus pertinents pour le mot en cours de génération.
- Valeur :
- Contient les informations réelles associées à chaque token d’entrée, pondérées par les scores d’attention.
- Exemple : les valeurs stockent le sens sémantique des mots, qui sont combinés en fonction des poids d’attention pour produire la sortie.
- Clé :
-
MLA (Multi-head Latent Attention) : un mécanisme d’attention novateur qui nécessite un cache KV (clé-valeur) plus léger, le rendant plus évolutif pour le traitement de longues séquences. MLA surpasse les mécanismes d’attention multi-têtes (MHA) traditionnels en termes d’évolutivité et de performances.
MHA vs MQA vs GQA vs MLA
| Module | Logique technique | Vitesse d’inférence | Performance du modèle |
|---|---|---|---|
| MHA | Plusieurs têtes génèrent indépendamment des clés et des valeurs sans partage (calcul de pleine dimension). | ⭐️ | ⭐️⭐️⭐️ |
| MQA | Toutes les têtes de requête partagent une seule paire clé-valeur (un seul groupe KV). | ⭐️⭐️⭐️ | ⭐️ |
| GQA | Les têtes de requête partagent des paires clé-valeur par groupes (plusieurs groupes KV). | ⭐️⭐️ | ⭐️⭐️ |
| MLA | Les paires clé-valeur sont compressées en vecteurs latents de faible dimension et décodées avec RoPE découplé pour conserver les informations de position. | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA : une « version simplifiée » de MHA, axée sur l’efficacité au prix d’une perte d’information.
- MLA : une « version compressée améliorée » qui équilibre l’efficacité mémoire et la rétention d’information, surpassant même MHA.
- Innovation architecturale : MLA n’est pas une simple optimisation mais une refonte des mécanismes d’attention, utilisant des variables latentes pour les reconstruire mathématiquement. Elle atteint le meilleur des deux mondes : efficacité et capacité.
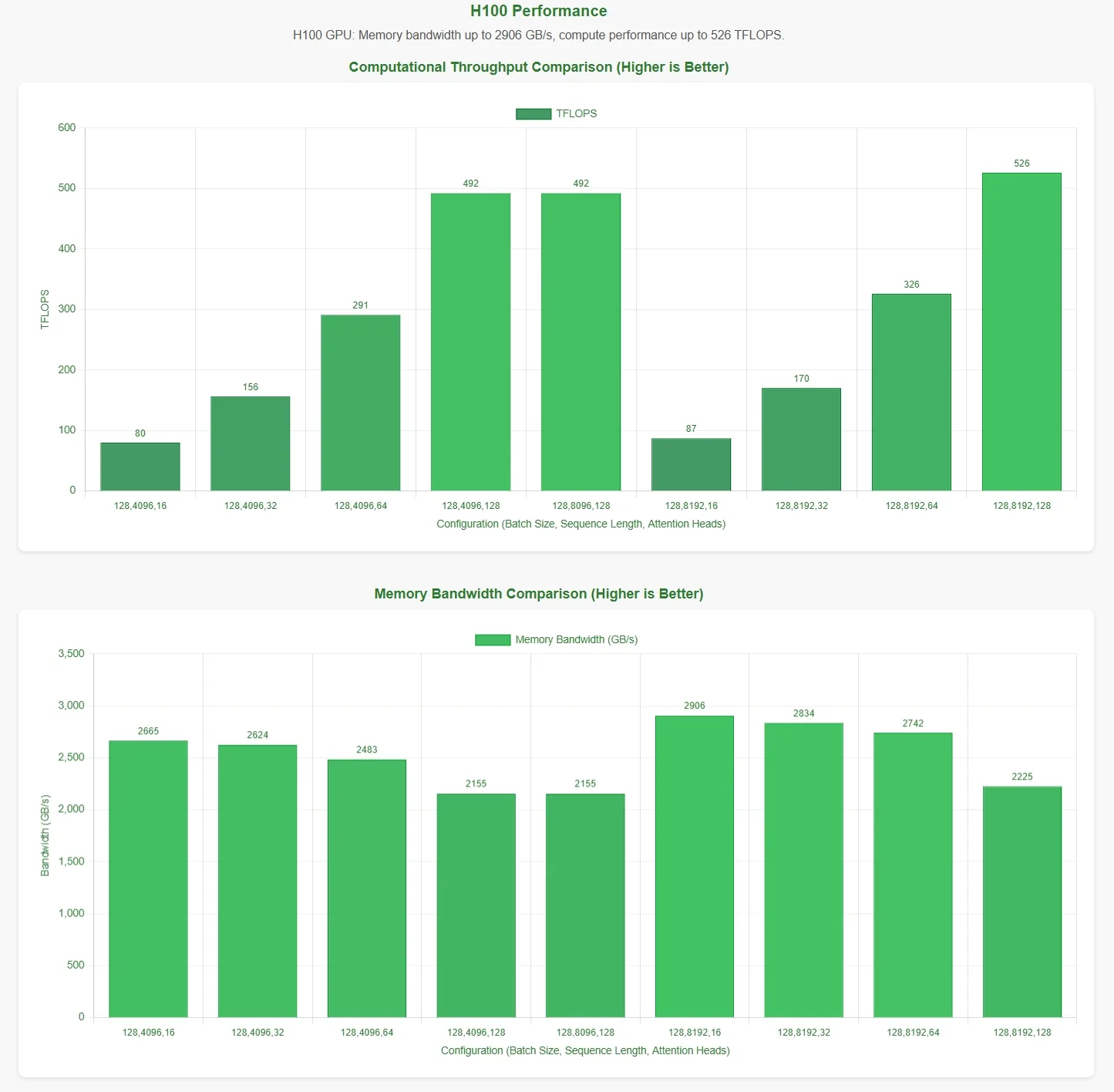
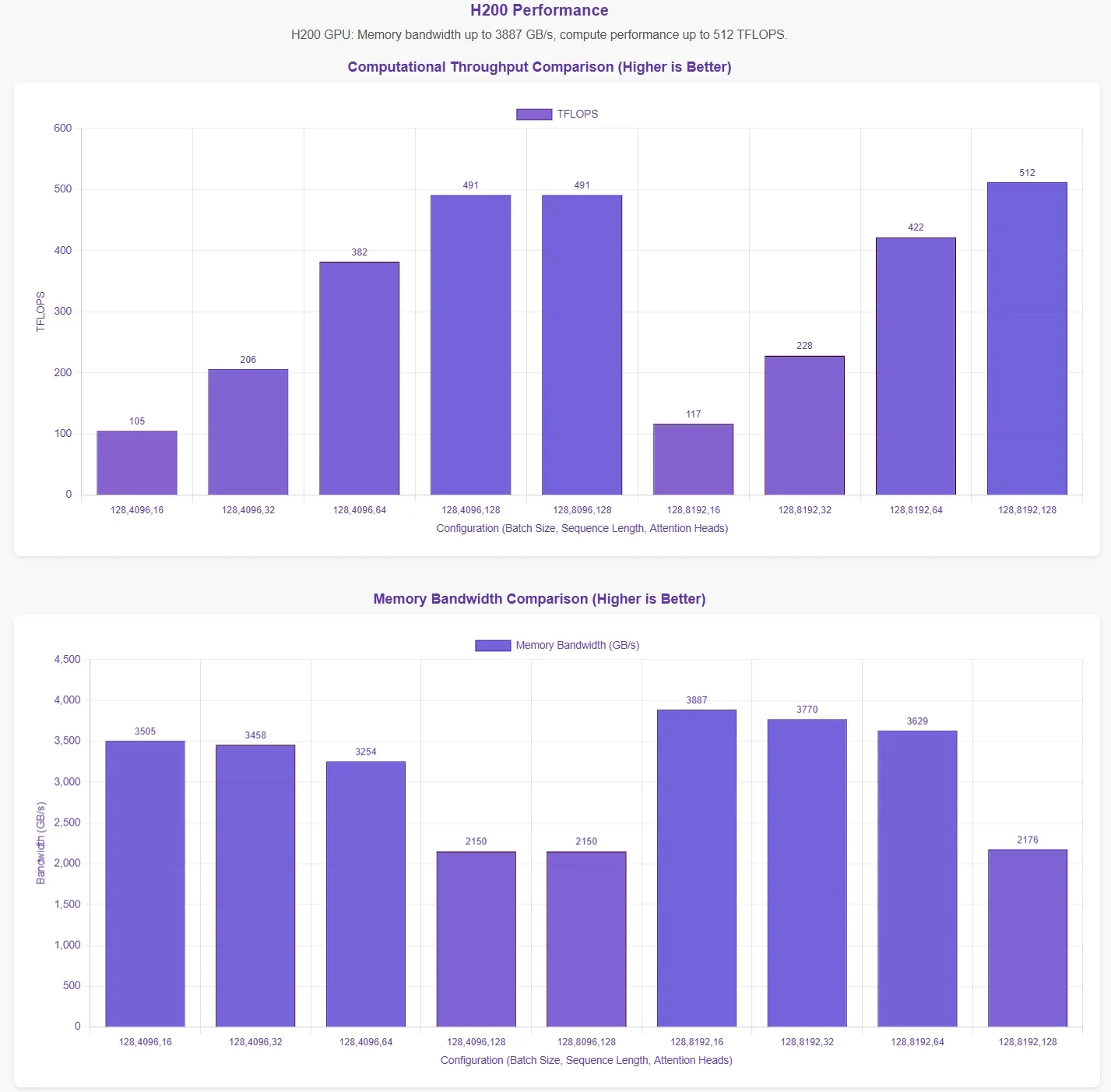
Évaluation des performances de FlashMLA par Novita AI
DeepSeek a annoncé que FlashMLA atteint une limite de bande passante mémoire de 3000 Go/s et une limite de calcul de 580 TFLOPS sur le GPU H800 SXM5. Pour valider ces affirmations, Novita AI a mené une évaluation complète, testant FlashMLA sous diverses configurations de paramètres.
Pour présenter les résultats de manière plus intuitive, l’axe horizontal des graphiques de performance représente les configurations de paramètres suivantes :
- Taille de lot (batch size)
- Longueur de séquence
- Nombre de têtes d’attention
Remarque
Ces résultats sont basés sur les scripts de test officiels. Sans connaissance des configurations de paramètres optimales, les données peuvent ne pas refléter pleinement les maximums théoriques.
Quel impact FlashMLA aura-t-il ?
La sortie de FlashMLA a non seulement suscité l’intérêt des développeurs, mais a également reçu des réponses positives de la part des frameworks d’inférence grand public, vLLM et SGLang.
- Intégration vLLM :
L’équipe vLLM a annoncé son intention d’intégrer bientôt FlashMLA. Techniquement, FlashMLA est construit sur PagedAttention, ce qui le rend hautement compatible avec la pile technologique de vLLM. Une fois intégré, FlashMLA devrait encore améliorer les performances d’inférence de vLLM. - Adoption par SGLang :
SGLang continuera à utiliser le déjà intégré FlashInferMLA, qui a été évalué comme offrant des performances comparables à FlashMLA.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via une API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et le passage à l’échelle.
Obtenez 20 $ de crédits et essayez DeepSeek maintenant !



