

O DeepSeek iniciou oficialmente sua iniciativa de lançamento de código aberto de cinco dias, com o primeiro projeto em destaque sendo o FlashMLA. O FlashMLA é um kernel de decodificação MLA otimizado e de alta eficiência, projetado especificamente para GPUs NVIDIA Hopper (por exemplo, H800 SXM5). Seu objetivo principal é acelerar os cálculos para modelos de grande escala, especialmente melhorando o desempenho em GPUs de ponta da NVIDIA.

Como fornecedora líder de infraestrutura de IA, a Novita AI foi uma das primeiras a avaliar o desempenho do FlashMLA em GPUs Hopper convencionais (H100, H200).
O que é MLA?
Antes de mergulharmos nos resultados da avaliação, vamos entender alguns conceitos de base relevantes.
-
GPU Hopper: a arquitetura de GPU de alto desempenho de próxima geração da NVIDIA, projetada para IA e computação de alto desempenho (HPC). Construída com processos tecnológicos avançados e uma arquitetura inovadora, as GPUs Hopper oferecem desempenho excepcional e eficiência energética para tarefas computacionais complexas. As GPUs Hopper convencionais incluem H100 e H200.
-
Kernel de Decodificação: um módulo de hardware ou software projetado especificamente para acelerar tarefas de decodificação. Na inferência de IA, os kernels de decodificação aumentam significativamente a velocidade e a eficiência da inferência do modelo, especialmente ao processar dados sequenciais.
-
Pares Chave-Valor (KV)
- Chave:
- Representa uma versão comprimida dos dados de entrada, usada para calcular os pesos de atenção (quanto foco colocar em diferentes partes da entrada).
- Exemplo: na geração de texto, as chaves ajudam o modelo a identificar quais palavras em uma frase são mais relevantes para a palavra atual sendo gerada.
- Valor:
- Contém as informações reais associadas a cada token de entrada, ponderadas pelos escores de atenção.
- Exemplo: os valores armazenam o significado semântico das palavras, que são combinados com base nos pesos de atenção para produzir a saída.
- Chave:
-
MLA (Multi-head Latent Attention): um novo mecanismo de atenção que requer cache KV (chave-valor) mais leve, tornando-o mais escalável para processamento de sequências longas. O MLA supera os mecanismos tradicionais de Atenção Multi-Cabeça (MHA) tanto em escalabilidade quanto em desempenho.
MHA VS MQA VS GQA VS MLA
| Módulo | Lógica Técnica | Velocidade de Inferência | Desempenho do Modelo |
|---|---|---|---|
| MHA | Múltiplas cabeças geram chaves e valores independentemente, sem compartilhamento (cálculo de dimensão completa). | ⭐️ | ⭐️⭐️⭐️ |
| MQA | Todas as cabeças de consulta compartilham um único par chave-valor (grupo KV único). | ⭐️⭐️⭐️ | ⭐️ |
| GQA | Cabeças de consulta compartilham pares chave-valor em grupos (múltiplos grupos KV). | ⭐️⭐️ | ⭐️⭐️ |
| MLA | Pares chave-valor são comprimidos em vetores latentes de baixa dimensão e decodificados com RoPE desacoplado para reter informações posicionais. | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA: uma “versão simplificada” do MHA, focando na eficiência ao custo de perda de informação.
- MLA: uma “versão comprimida atualizada” que equilibra eficiência de memória e retenção de informações, superando até mesmo o MHA.
- Inovação Arquitetural: o MLA não é uma mera otimização, mas uma reinterpretação dos mecanismos de atenção, utilizando variáveis latentes para reconstruí-los matematicamente. Ele alcança o melhor dos dois mundos: eficiência e capacidade.
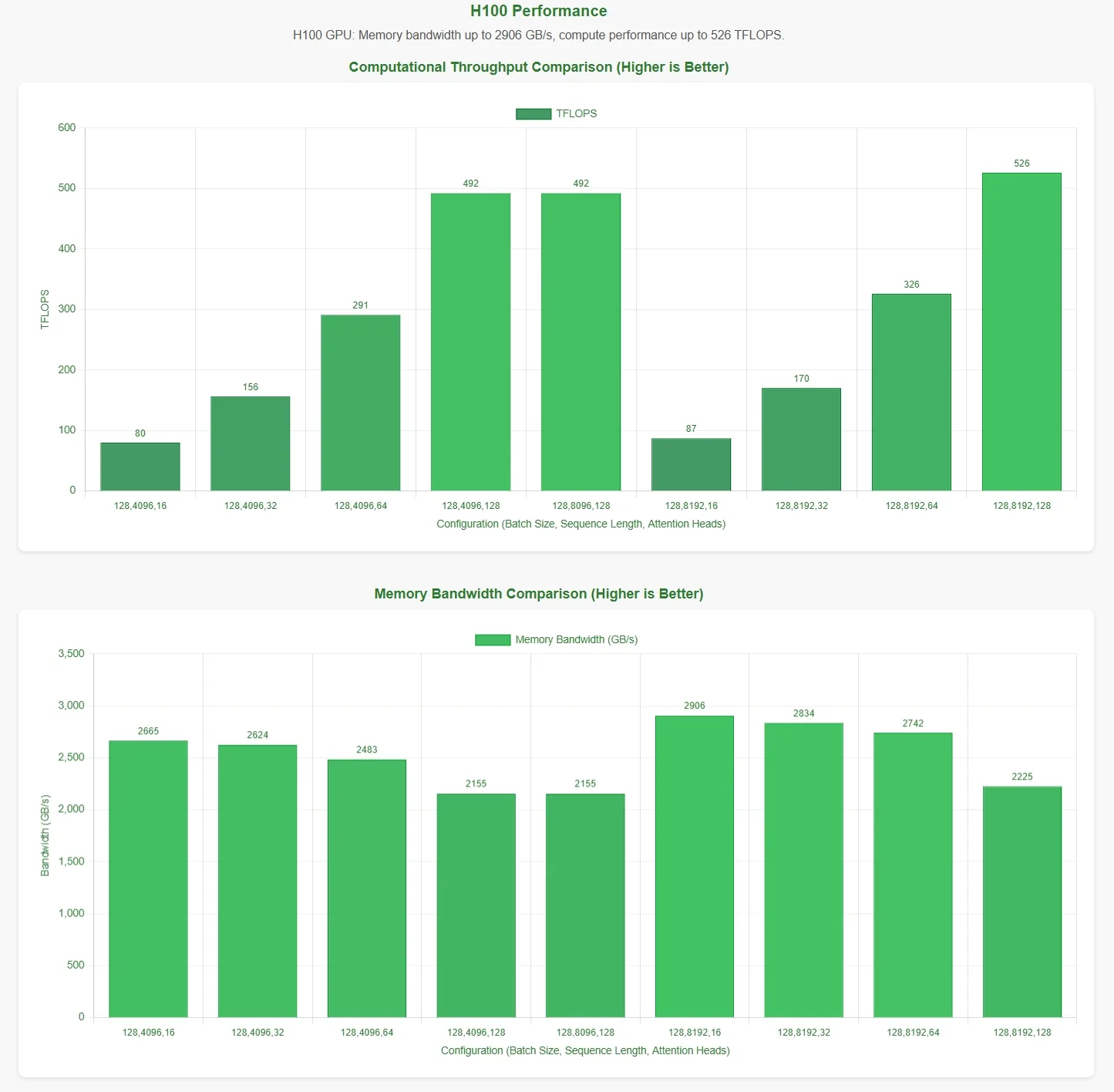
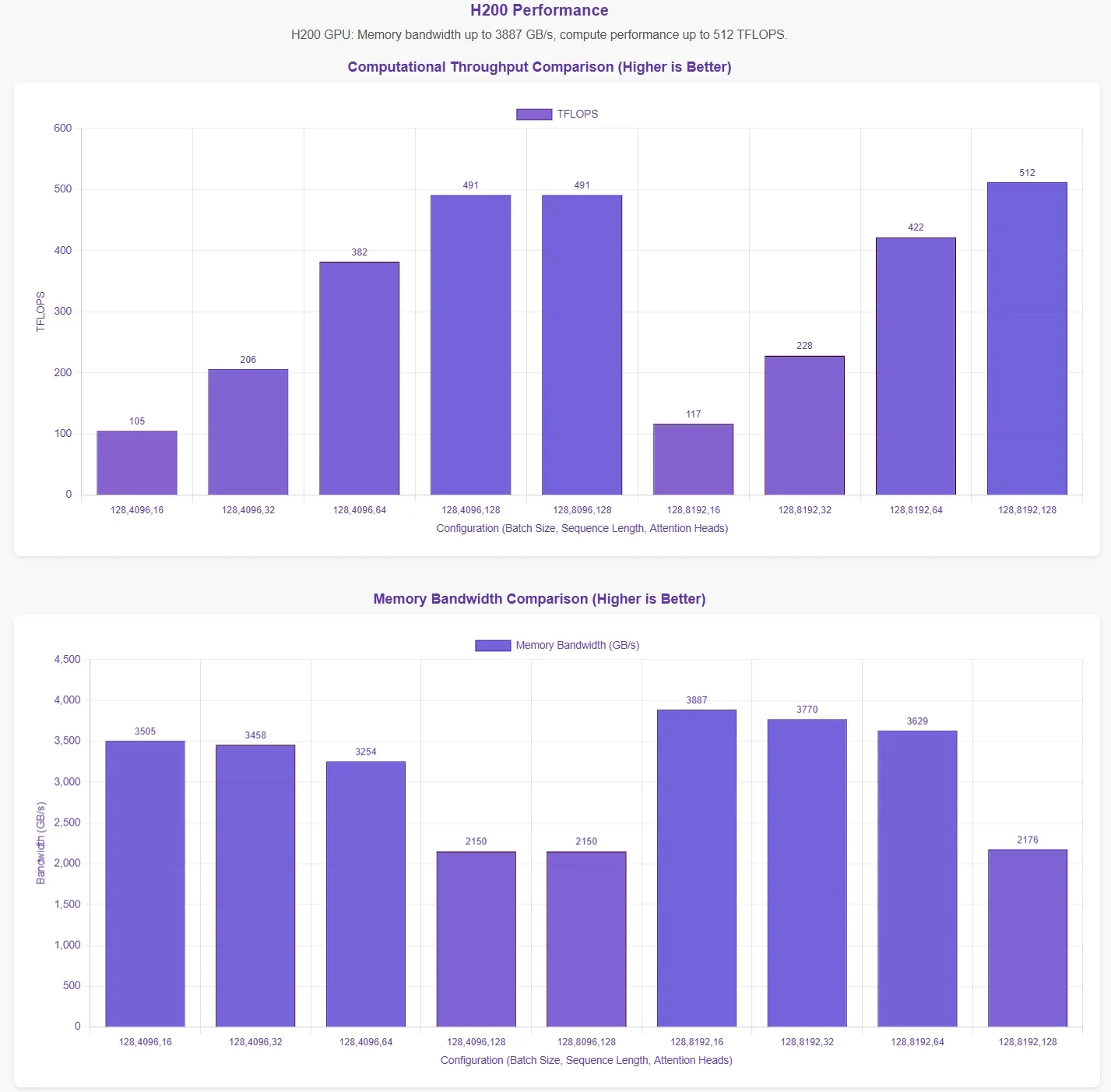
Avaliação de Desempenho do FlashMLA pela Novita AI
O DeepSeek anunciou que o FlashMLA atinge um limite de largura de banda de memória de 3000 GB/s e um limite computacional de 580 TFLOPS na GPU H800 SXM5. Para validar essas afirmações, a Novita AI realizou uma avaliação abrangente, testando o FlashMLA sob várias configurações de parâmetros.
Para apresentar os resultados de forma mais intuitiva, o eixo horizontal nos gráficos de desempenho representa as seguintes configurações de parâmetros:
- Tamanho do Lote
- Comprimento da Sequência
- Número de Cabeças de Atenção
Nota
Esses resultados são baseados nos scripts de teste oficiais. Sem o conhecimento das configurações ideais de parâmetros, os dados podem não refletir totalmente os máximos teóricos.
Qual Impacto o FlashMLA Terá?
O lançamento do FlashMLA não apenas capturou o interesse dos desenvolvedores, mas também gerou respostas positivas de frameworks de inferência convencionais, vLLM e SGLang.
- Integração com vLLM:
A equipe do vLLM anunciou planos para integrar o FlashMLA em breve. Tecnicamente, o FlashMLA é construído sobre o PagedAttention, tornando-o altamente compatível com a pilha de tecnologia do vLLM. Uma vez integrado, espera-se que o FlashMLA melhore ainda mais o desempenho de inferência do vLLM. - Adoção pelo SGLang:
O SGLang continuará utilizando o já integrado FlashInferMLA, que foi avaliado como tendo desempenho comparável ao FlashMLA.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem de GPU acessível e confiável para construção e escalonamento.
Obtenha $20 em créditos e experimente o DeepSeek agora!



