

أطلقت DeepSeek رسمياً مبادرتها المفتوحة المصدر التي تستمر خمسة أيام، وكان أول مشروع يتم تسليط الضوء عليه هو FlashMLA. FlashMLA هي نواة فك ترميز محسّنة وعالية الكفاءة من نوع MLA مصممة خصيصاً لوحدات معالجة NVIDIA Hopper (مثل H800 SXM5). هدفها الأساسي هو تسريع العمليات الحسابية للنماذج واسعة النطاق، وخاصة تحسين الأداء على وحدات معالجة NVIDIA المتطورة.

باعتبارها مزوداً رائداً للبنية التحتية للذكاء الاصطناعي، كانت Novita AI من بين الأوائل الذين قاموا بتقييم أداء FlashMLA عبر وحدات Hopper الرئيسية (H100, H200).
ما هو MLA؟
قبل الغوص في نتائج التقييم، دعنا نتوقف قليلاً لفهم بعض المفاهيم الأساسية ذات الصلة.
-
وحدة معالجة Hopper: بنية الجيل التالي من وحدات المعالجة عالية الأداء من NVIDIA، المصممة للذكاء الاصطناعي والحوسبة عالية الأداء (HPC). تم بناؤها بتقنيات تصنيع متقدمة وهندسة مبتكرة، وتقدم وحدات Hopper أداءً استثنائياً وكفاءة في استهلاك الطاقة للمهام الحسابية المعقدة. تشمل وحدات Hopper الرئيسية H100 و H200.
-
نواة فك الترميز (Decoding Kernel): وحدة عتادية أو برمجية مصممة خصيصاً لتسريع مهام فك الترميز. في استدلال الذكاء الاصطناعي، تعمل نوى فك الترميز على تعزيز سرعة وكفاءة استدلال النموذج، خاصة عند معالجة البيانات التسلسلية.
-
أزواج المفتاح-القيمة (Key-Value Pairs)
- المفتاح (Key):
- يمثل نسخة مضغوطة من بيانات الإدخال، يُستخدم لحساب أوزان الانتباه (مقدار التركيز على أجزاء مختلفة من الإدخال).
- مثال: في توليد النص، تساعد المفاتيح النموذج في تحديد الكلمات الأكثر صلة بالكلمة التي يتم توليدها حالياً.
- القيمة (Value):
- تحتوي على المعلومات الفعلية المرتبطة بكل رمز إدخال، مرجحة بدرجات الانتباه.
- مثال: تخزن القيم المعنى الدلالي للكلمات، والتي يتم دمجها بناءً على أوزان الانتباه لإنتاج المخرجات.
- المفتاح (Key):
-
MLA (Multi-head Latent Attention): آلية انتباه جديدة تتطلب تخزيناً مؤقتاً أخف للمفاتيح والقيم (KV caching)، مما يجعلها أكثر قابلية للتوسع لمعالجة التسلسلات الطويلة. يتفوق MLA على آليات الانتباه متعدد الرؤوس التقليدية (MHA) من حيث قابلية التوسع والأداء.
MHA مقابل MQA مقابل GQA مقابل MLA
| الوحدة | المنطق التقني | سرعة الاستدلال | أداء النموذج |
|---|---|---|---|
| MHA | رؤوس متعددة تولد المفاتيح والقيم بشكل مستقل دون مشاركة (حساب كامل الأبعاد). | ⭐️ | ⭐️⭐️⭐️ |
| MQA | جميع رؤوس الاستعلام تشارك زوجاً واحداً من المفتاح والقيمة (مجموعة KV واحدة). | ⭐️⭐️⭐️ | ⭐️ |
| GQA | رؤوس الاستعلام تشارك أزواج المفتاح والقيمة في مجموعات (مجموعات KV متعددة). | ⭐️⭐️ | ⭐️⭐️ |
| MLA | يتم ضغط أزواج المفتاح والقيمة إلى متجهات كامنة منخفضة الأبعاد وفك ترميزها باستخدام RoPE المنفصل للاحتفاظ بالمعلومات الموضعية. | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA: “إصدار مبسط” من MHA، يركز على الكفاءة على حساب فقدان المعلومات.
- MLA: “إصدار مضغوط مُحسَّن” يوازن بين كفاءة الذاكرة والاحتفاظ بالمعلومات، بل ويتفوق على MHA.
- الابتكار المعماري: MLA ليس مجرد تحسين، بل إعادة تصور لآليات الانتباه، باستخدام المتغيرات الكامنة لإعادة بنائها رياضياً. يحقق أفضل ما في العالمين: الكفاءة والقدرة.
تقييم أداء FlashMLA بواسطة Novita AI
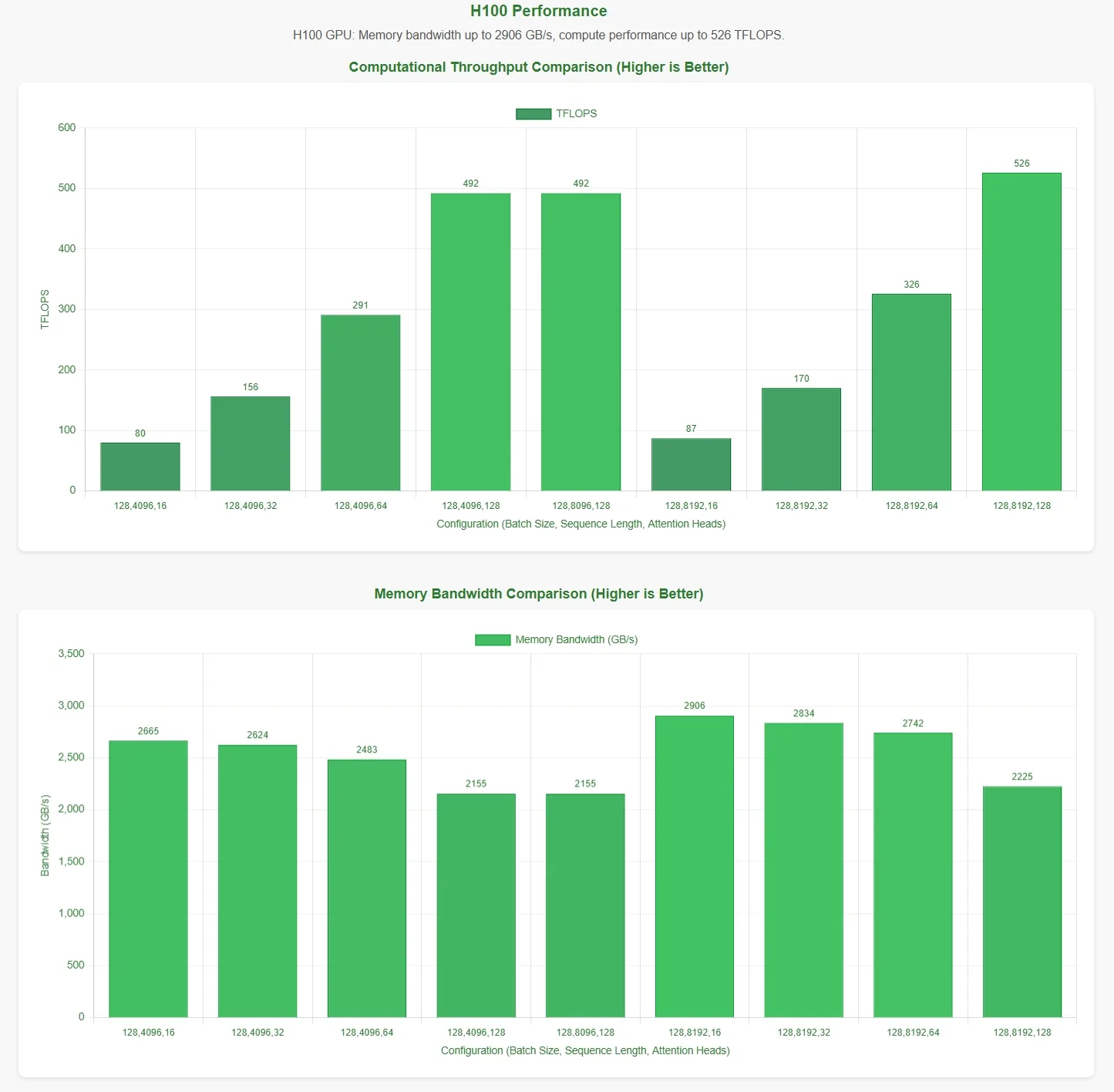
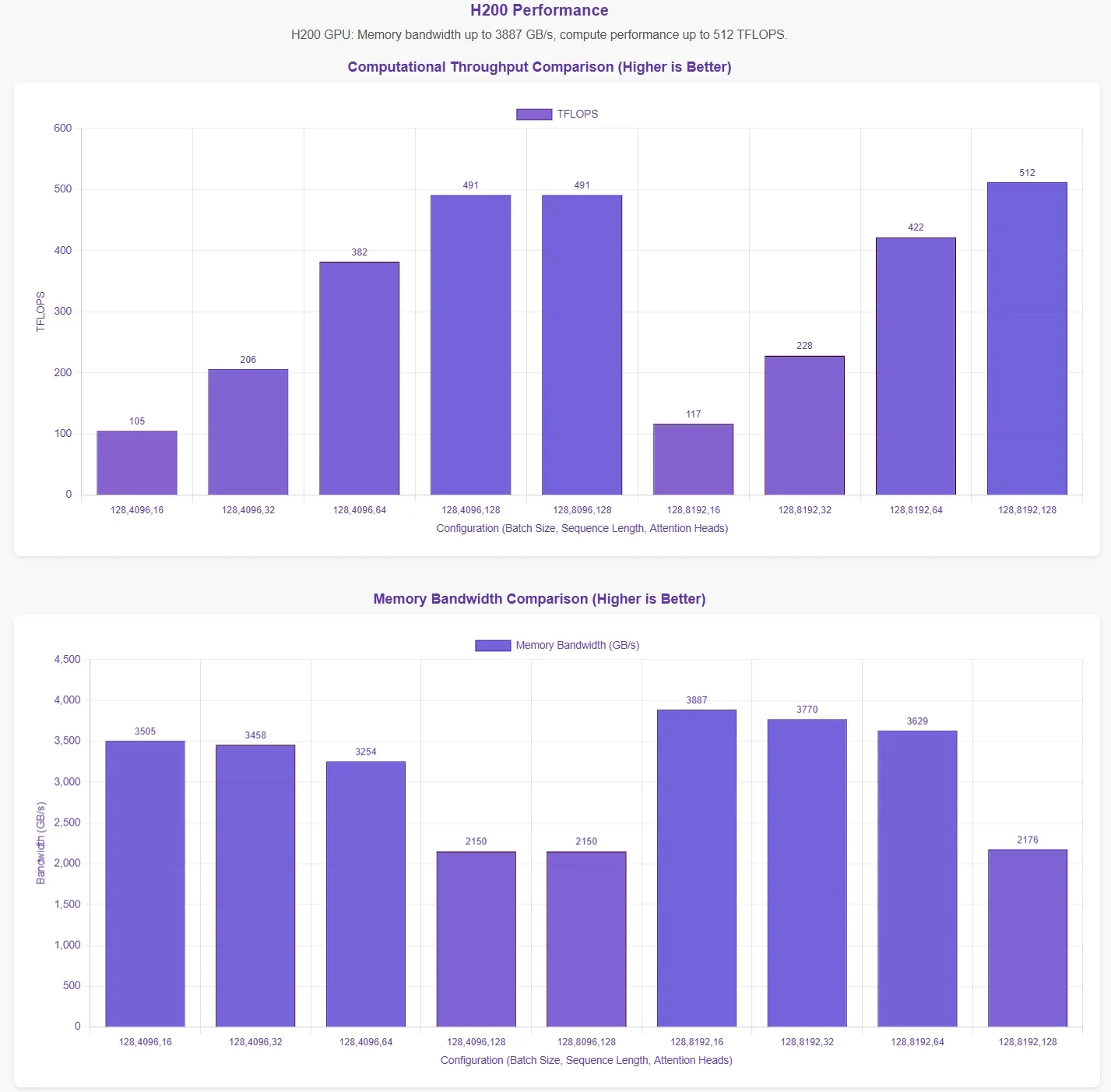
أعلنت DeepSeek أن FlashMLA يحقق حداً أقصى لعرض النطاق الترددي للذاكرة يبلغ 3000 جيجابايت/ثانية وحداً أقصى للحوسبة يبلغ 580 تيرافلوب على وحدة معالجة H800 SXM5. وللتحقق من هذه الادعاءات، أجرت Novita AI تقييماً شاملاً، واختبرت FlashMLA تحت تكوينات معلمات مختلفة.
لعرض النتائج بشكل أكثر بديهية، يمثل المحور الأفقي في الرسوم البيانية للأداء تكوينات المعلمات التالية:
- حجم الدفعة (Batch Size)
- طول التسلسل (Sequence Length)
- عدد رؤوس الانتباه (Number of Attention Heads)
ملاحظة
تستند هذه النتائج إلى نصوص الاختبار الرسمية. بدون معرفة تكوينات المعلمات المثلى، قد لا تعكس البيانات الحدود القصوى النظرية بشكل كامل.
ما هو تأثير FlashMLA؟
لم يقتصر إصدار FlashMLA على جذب اهتمام المطورين فحسب، بل حصل أيضاً على ردود فعل إيجابية من أطر الاستدلال الرئيسية، vLLM و SGLang.
- دمج vLLM:
أعلن فريق vLLM عن خطط لدمج FlashMLA قريباً. من الناحية التقنية، تم بناء FlashMLA على PagedAttention، مما يجعله متوافقاً بشكل كبير مع كومة تقنيات vLLM. بمجرد دمجه، من المتوقع أن يعزز FlashMLA أداء استدلال vLLM بشكل أكبر. - اعتماد SGLang:
ستواصل SGLang استخدام FlashInferMLA المدمج بالفعل، والذي تم تقييمه لتقديم أداء مماثل لـ FlashMLA.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
احصل على 20 دولاراً كرصيد وجرب DeepSeek الآن!



