

DeepSeek hat offiziell seine fünftägige Open-Source-Release-Initiative gestartet, wobei das erste vorgestellte Projekt FlashMLA ist. FlashMLA ist ein optimierter, hocheffizienter MLA-Decoding-Kernel, der speziell für NVIDIA Hopper GPUs (z.B. H800 SXM5) entwickelt wurde. Sein Hauptziel ist es, Berechnungen für große Modelle zu beschleunigen und insbesondere die Leistung auf NVIDIAs High-End-GPUs zu verbessern.

Als führender Anbieter von KI-Infrastruktur war Novita AI einer der Ersten, der FlashMLAs Leistung auf den gängigen Hopper GPUs (H100, H200) evaluiert hat.
Was ist MLA?
Bevor wir zu den Evaluierungsergebnissen kommen, sollten wir uns kurz die relevanten Hintergrundkonzepte ansehen.
-
Hopper GPU: NVIDIAs nächste Generation hochleistungsfähiger GPU-Architektur, entwickelt für KI und High-Performance Computing (HPC). Gebaut mit fortschrittlichen Fertigungsprozessen und einer innovativen Architektur, liefern Hopper GPUs außergewöhnliche Leistung und Energieeffizienz für komplexe Rechenaufgaben. Die etablierten Hopper GPUs umfassen H100 und H200.
-
Decoding Kernel: Eine Hardware- oder Softwarekomponente, die speziell zur Beschleunigung von Decodierungsaufgaben entwickelt wurde. In der KI-Inferenz steigern Decoding-Kernel die Geschwindigkeit und Effizienz der Modellinferenz erheblich, insbesondere bei der Verarbeitung sequentieller Daten.
-
Key-Value (KV) Paare
- Key:
- Stellt eine komprimierte Version der Eingabedaten dar, die zur Berechnung von Aufmerksamkeitsgewichten verwendet wird (wie stark verschiedene Teile der Eingabe fokussiert werden).
- Beispiel: Bei der Texterzeugung helfen Keys dem Modell zu erkennen, welche Wörter in einem Satz am relevantesten für das aktuell generierte Wort sind.
- Value:
- Enthält die tatsächlichen Informationen, die mit jedem Eingabe-Token verbunden sind, gewichtet durch die Aufmerksamkeitswerte.
- Beispiel: Values speichern die semantische Bedeutung von Wörtern, die basierend auf Aufmerksamkeitsgewichten kombiniert werden, um die Ausgabe zu erzeugen.
- Key:
-
MLA (Multi-head Latent Attention): Ein neuartiger Aufmerksamkeitsmechanismus, der einen leichteren KV (Key-Value) Cache benötigt und dadurch besser für die Verarbeitung langer Sequenzen skalierbar ist. MLA übertrifft traditionelle Multi-Head Attention (MHA) Mechanismen sowohl in Skalierbarkeit als auch Leistung.
MHA vs. MQA vs. GQA vs. MLA
| Modul | Technische Logik | Inferenzgeschwindigkeit | Modellleistung |
|---|---|---|---|
| MHA | Mehrere Köpfe erzeugen unabhängig voneinander Keys und Values, keine gemeinsame Nutzung (volldimensionale Berechnung). | ⭐️ | ⭐️⭐️⭐️ |
| MQA | Alle Query-Köpfe teilen sich ein einziges Key-Value-Paar (eine KV-Gruppe). | ⭐️⭐️⭐️ | ⭐️ |
| GQA | Query-Köpfe teilen sich Key-Value-Paare in Gruppen (mehrere KV-Gruppen). | ⭐️⭐️ | ⭐️⭐️ |
| MLA | Key-Value-Paare werden in niedrigdimensionale latente Vektoren komprimiert und mit entkoppeltem RoPE decodiert, um Positionsinformationen zu erhalten. | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA: Eine „vereinfachte Version“ von MHA, die Effizienz auf Kosten von Informationsverlust priorisiert.
- MLA: Eine „aufgewertete komprimierte Version“, die Speichereffizienz und Informationserhalt ausgleicht und sogar MHA übertrifft.
- Architektonische Innovation: MLA ist keine bloße Optimierung, sondern eine Neugestaltung von Aufmerksamkeitsmechanismen, die latente Variablen nutzt, um sie mathematisch zu rekonstruieren. Es erreicht das Beste aus beiden Welten: Effizienz und Leistungsfähigkeit.
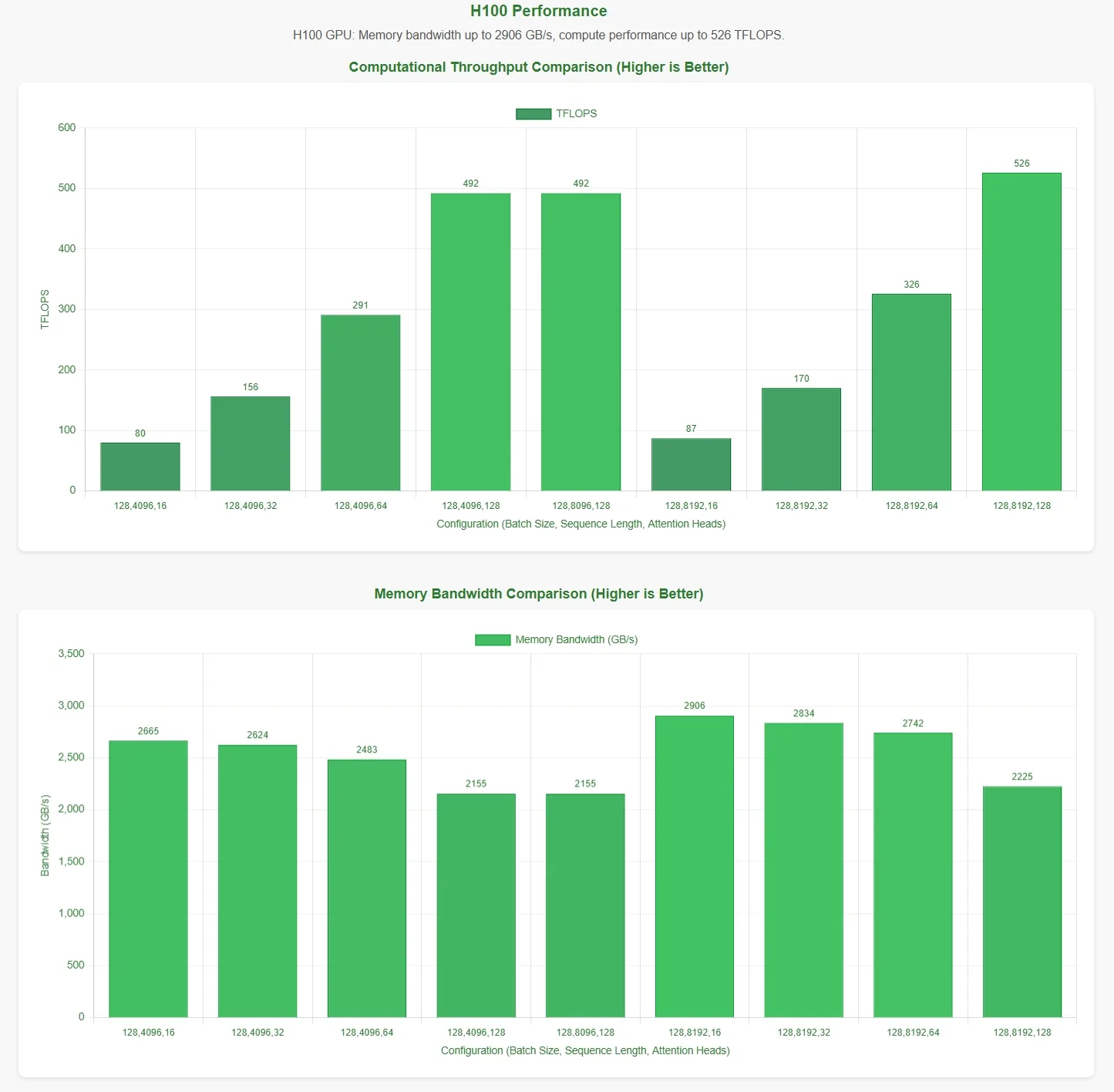
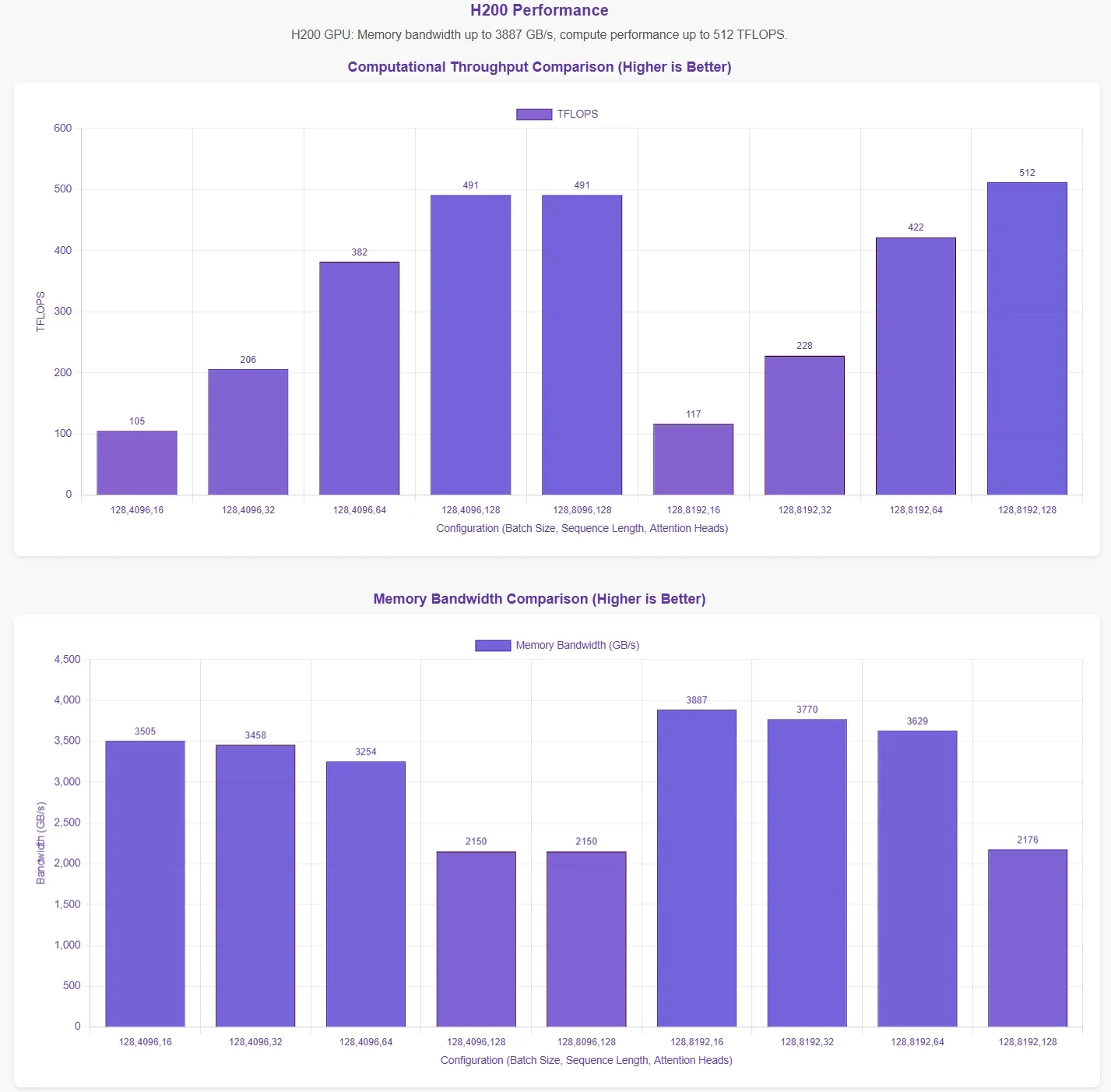
FlashMLA-Leistungsbewertung durch Novita AI
DeepSeek hat angekündigt, dass FlashMLA auf der H800 SXM5 GPU eine Speicherbandbreitengrenze von 3000 GB/s und eine Rechengrenze von 580 TFLOPS erreicht. Um diese Behauptungen zu validieren, führte Novita AI eine umfassende Evaluierung durch und testete FlashMLA unter verschiedenen Parameterkonfigurationen.
Um die Ergebnisse anschaulicher darzustellen, repräsentiert die horizontale Achse in den Leistungsdiagrammen die folgenden Parameterkonfigurationen:
- Batch-Größe
- Sequenzlänge
- Anzahl der Aufmerksamkeitsköpfe
Hinweis
Diese Ergebnisse basieren auf den offiziellen Testskripten. Ohne Kenntnis der optimalen Parameterkonfigurationen können die Daten möglicherweise nicht die theoretischen Maximalwerte widerspiegeln.
Welche Auswirkungen wird FlashMLA haben?
Die Veröffentlichung von FlashMLA hat nicht nur das Interesse von Entwicklern geweckt, sondern auch positive Resonanz von den gängigen Inferenz-Frameworks vLLM und SGLang erhalten.
- Integration in vLLM:
Das vLLM-Team hat angekündigt, FlashMLA bald zu integrieren. Technisch basiert FlashMLA auf PagedAttention, was es sehr kompatibel mit dem Technologie-Stack von vLLM macht. Nach der Integration wird erwartet, dass FlashMLA die Inferenzleistung von vLLM weiter verbessert. - Übernahme durch SGLang:
SGLang wird weiterhin das bereits integrierte FlashInferMLA nutzen, das in Evaluierungen eine mit FlashMLA vergleichbare Leistung gezeigt hat.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.
Jetzt $20 Guthaben sichern und DeepSeek testen!



