

DeepSeek ha lanzado oficialmente su iniciativa de lanzamiento de código abierto de cinco días. El primer proyecto destacado es FlashMLA. FlashMLA es un kernel de decodificación MLA optimizado y de alta eficiencia, diseñado específicamente para las GPU NVIDIA Hopper (p. ej., H800 SXM5). Su objetivo principal es acelerar los cálculos de modelos a gran escala, mejorando especialmente el rendimiento en las GPU de gama alta de NVIDIA.

Como proveedor líder de infraestructuras de IA, Novita AI fue uno de los primeros en evaluar el rendimiento de FlashMLA en las GPU Hopper más populares (H100, H200).
¿Qué es MLA?
Antes de entrar en los resultados de la evaluación, dediquemos un momento a entender algunos conceptos relevantes.
-
GPU Hopper: arquitectura de GPU de alto rendimiento de próxima generación de NVIDIA, diseñada para IA y computación de alto rendimiento (HPC). Construida con procesos tecnológicos avanzados y una arquitectura innovadora, las GPU Hopper ofrecen un rendimiento excepcional y eficiencia energética para tareas computacionales complejas. Las GPU Hopper más comunes incluyen la H100 y la H200.
-
Kernel de decodificación: módulo de hardware o software diseñado específicamente para acelerar tareas de decodificación. En la inferencia de IA, los kernels de decodificación mejoran significativamente la velocidad y eficiencia de la inferencia del modelo, especialmente cuando se procesan datos secuenciales.
-
Pares clave-valor (KV):
- Clave:
- Representa una versión comprimida de los datos de entrada, utilizada para calcular los pesos de atención (cuánto enfoque poner en diferentes partes de la entrada).
- Ejemplo: en la generación de texto, las claves ayudan al modelo a identificar qué palabras de una oración son más relevantes para la palabra que se está generando en ese momento.
- Valor:
- Contiene la información real asociada a cada token de entrada, ponderada por las puntuaciones de atención.
- Ejemplo: los valores almacenan el significado semántico de las palabras, los cuales se combinan según los pesos de atención para producir la salida.
- Clave:
-
MLA (Multi-head Latent Attention): un novedoso mecanismo de atención que requiere un almacenamiento en caché KV (clave-valor) más ligero, lo que lo hace más escalable para el procesamiento de secuencias largas. MLA supera a los mecanismos tradicionales de atención de múltiples cabezales (MHA) tanto en escalabilidad como en rendimiento.
MHA vs MQA vs GQA vs MLA
| Módulo | Lógica técnica | Velocidad de inferencia | Rendimiento del modelo |
|---|---|---|---|
| MHA | Múltiples cabezales generan independientemente claves y valores sin compartir (cómputo de dimensiones completas). | ⭐️ | ⭐️⭐️⭐️ |
| MQA | Todos los cabezales de consulta comparten un único par clave-valor (un solo grupo KV). | ⭐️⭐️⭐️ | ⭐️ |
| GQA | Los cabezales de consulta comparten pares clave-valor en grupos (múltiples grupos KV). | ⭐️⭐️ | ⭐️⭐️ |
| MLA | Los pares clave-valor se comprimen en vectores latentes de baja dimensión y se decodifican con RoPE desacoplado para retener la información posicional. | ⭐️⭐️⭐️⭐️ | ⭐️⭐️⭐️⭐️ |
- MQA/GQA: una “versión simplificada” de MHA, centrada en la eficiencia a costa de pérdida de información.
- MLA: una “versión comprimida mejorada” que equilibra la eficiencia de memoria y la retención de información, incluso superando a MHA.
- Innovación arquitectónica: MLA no es una mera optimización, sino una reinvención de los mecanismos de atención, aprovechando variables latentes para reconstruirlos matemáticamente. Logra lo mejor de ambos mundos: eficiencia y capacidad.
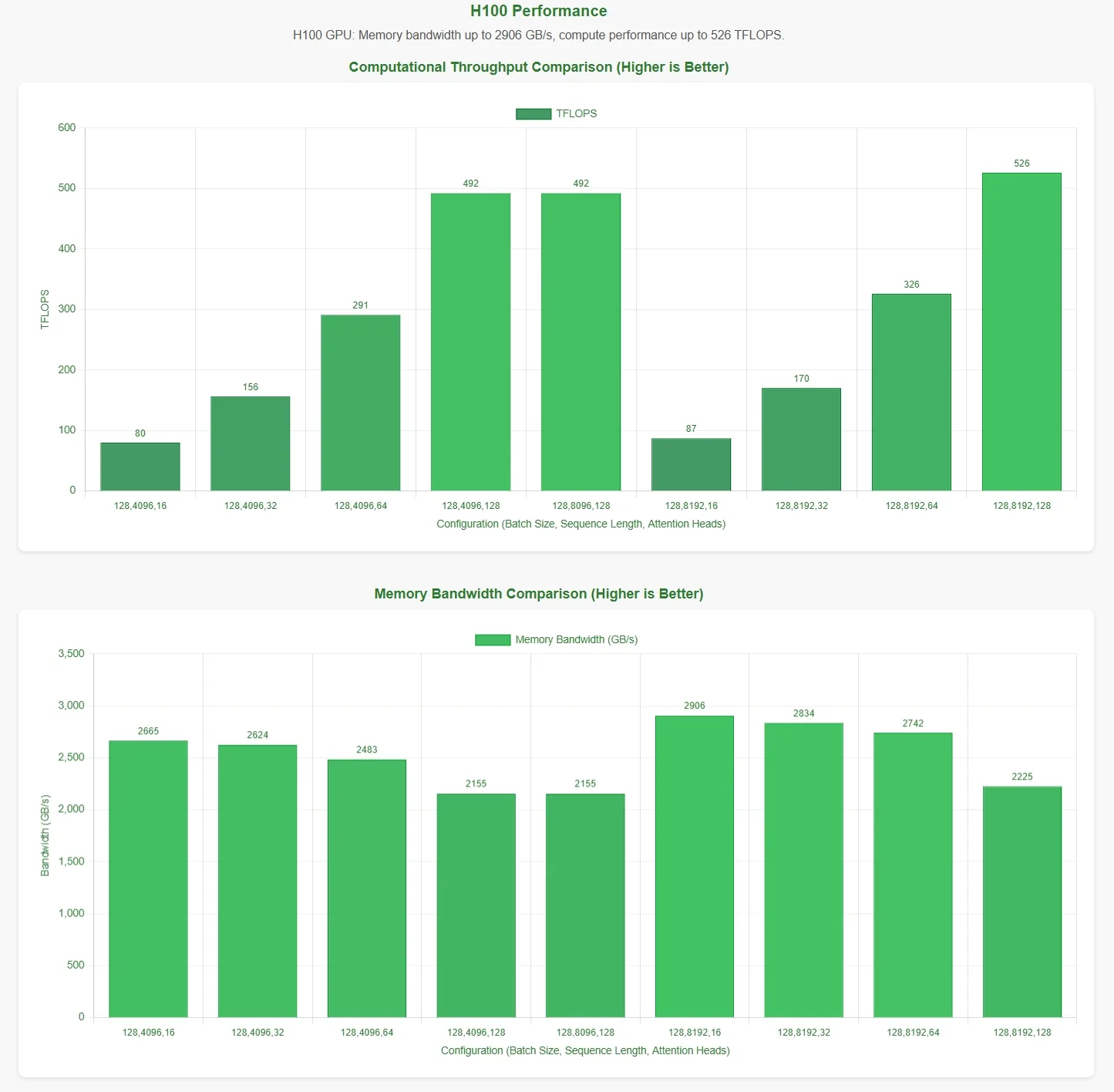
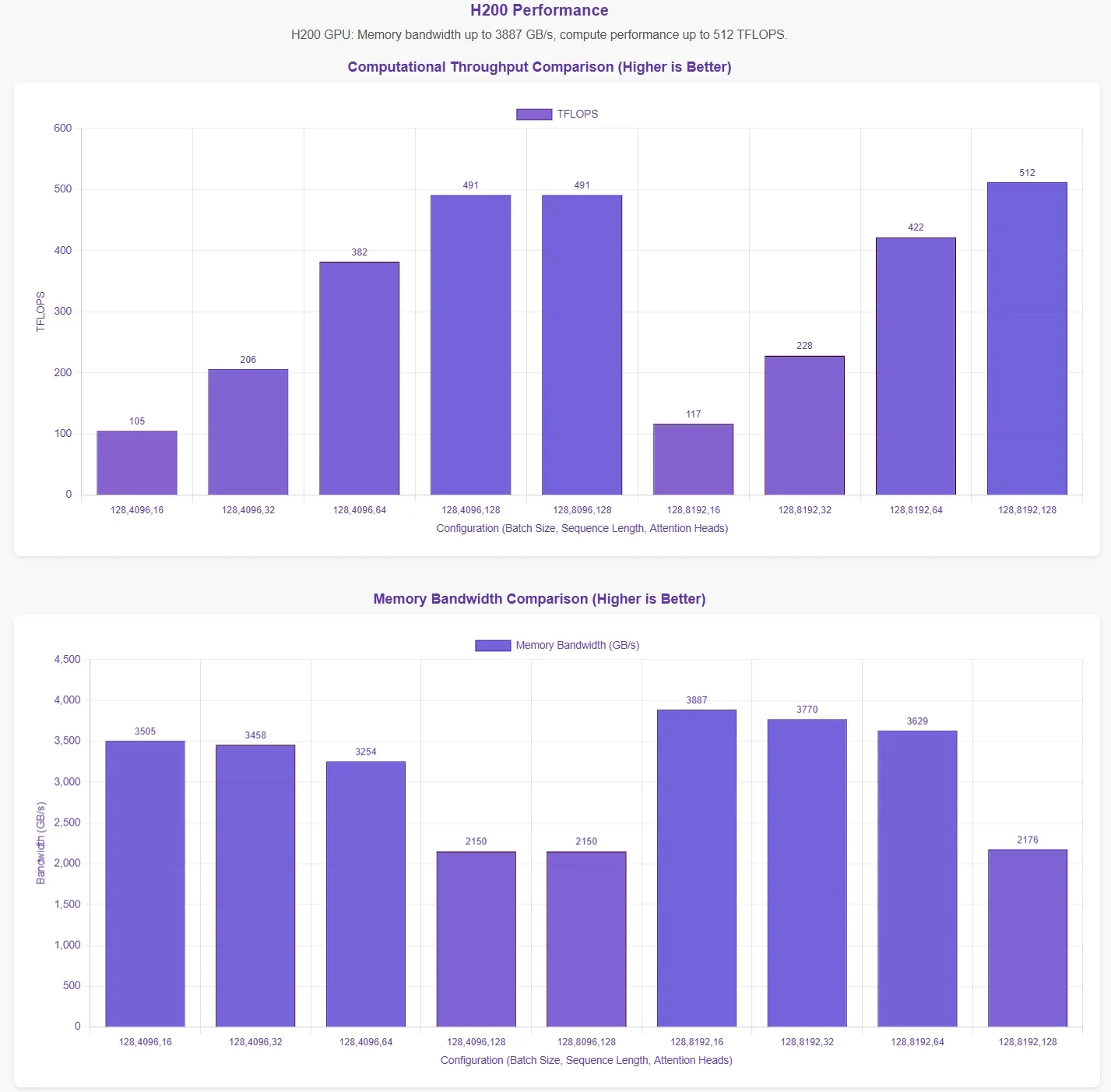
Evaluación del rendimiento de FlashMLA por Novita AI
DeepSeek ha anunciado que FlashMLA alcanza un límite de ancho de banda de memoria de 3000 GB/s y un límite de cómputo de 580 TFLOPS en la GPU H800 SXM5. Para validar estas afirmaciones, Novita AI realizó una evaluación exhaustiva, probando FlashMLA bajo varias configuraciones de parámetros.
Para presentar los resultados de forma más intuitiva, el eje horizontal en los gráficos de rendimiento representa las siguientes configuraciones de parámetros:
- Tamaño de lote
- Longitud de secuencia
- Número de cabezales de atención
Nota
Estos resultados se basan en los scripts de prueba oficiales. Sin conocer las configuraciones óptimas de parámetros, los datos pueden no reflejar completamente los máximos teóricos.
¿Qué impacto tendrá FlashMLA?
El lanzamiento de FlashMLA no solo ha captado el interés de los desarrolladores, sino que también ha recibido respuestas positivas de los frameworks de inferencia más populares, vLLM y SGLang.
- Integración con vLLM:
El equipo de vLLM ha anunciado planes para integrar FlashMLA próximamente. Técnicamente, FlashMLA está construido sobre PagedAttention, lo que lo hace altamente compatible con el stack tecnológico de vLLM. Una vez integrado, se espera que FlashMLA mejore aún más el rendimiento de inferencia de vLLM. - Adopción por SGLang:
SGLang continuará utilizando FlashInferMLA, que ya está integrado y ha sido evaluado para ofrecer un rendimiento comparable al de FlashMLA.
Novita AI es una plataforma cloud de IA que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona una nube de GPU asequible y fiable para construir y escalar.
¡Obtén $20 en créditos y prueba DeepSeek ahora!



