

Google 的 Gemma 3 27B 是开放 AI 模型的一项突破,在消费级硬件上提供了最先进的性能。然而,其全精度版本需要大量的计算资源。通过量化——尤其是 Google 的量化感知训练(QAT)——该模型无需大幅牺牲性能即可变得可用。以下是如何优化 Gemma 3 27B 以实现高效运行。
了解 Gemma 3 27B
Gemma 3 27B 是一种最先进的语言模型,结合了先进的架构与广泛的训练数据,以提供高质量的语言建模能力。其设计使其能够处理各种任务——从自然语言理解到文本生成——具有出色的熟练度。然而,以全精度运行该模型可能计算量很大。以下是关于 Gemma 3 27B 的几个关键点:
- 架构与规模: 该模型包含 270 亿个参数,使其处于现代 AI 研究的最前沿。
- 资源需求: 以全精度运行该模型需要大量的内存和处理能力,使其难以在消费级硬件上部署。
- 用例: 尽管硬件要求很高,Gemma 3 27B 非常适合各种应用,包括对话代理、内容生成和实时数据分析。
为什么要量化 Gemma 3 27B?了解其优势
量化减少了用于表示模型参数的数字的精度。不再使用每个数字 16 位(BFloat16),量化允许我们使用更少的位数,例如 8 位(int8)甚至 4 位(int4),从而显著降低内存需求。
量化 Gemma 3 27B 的优势包括:
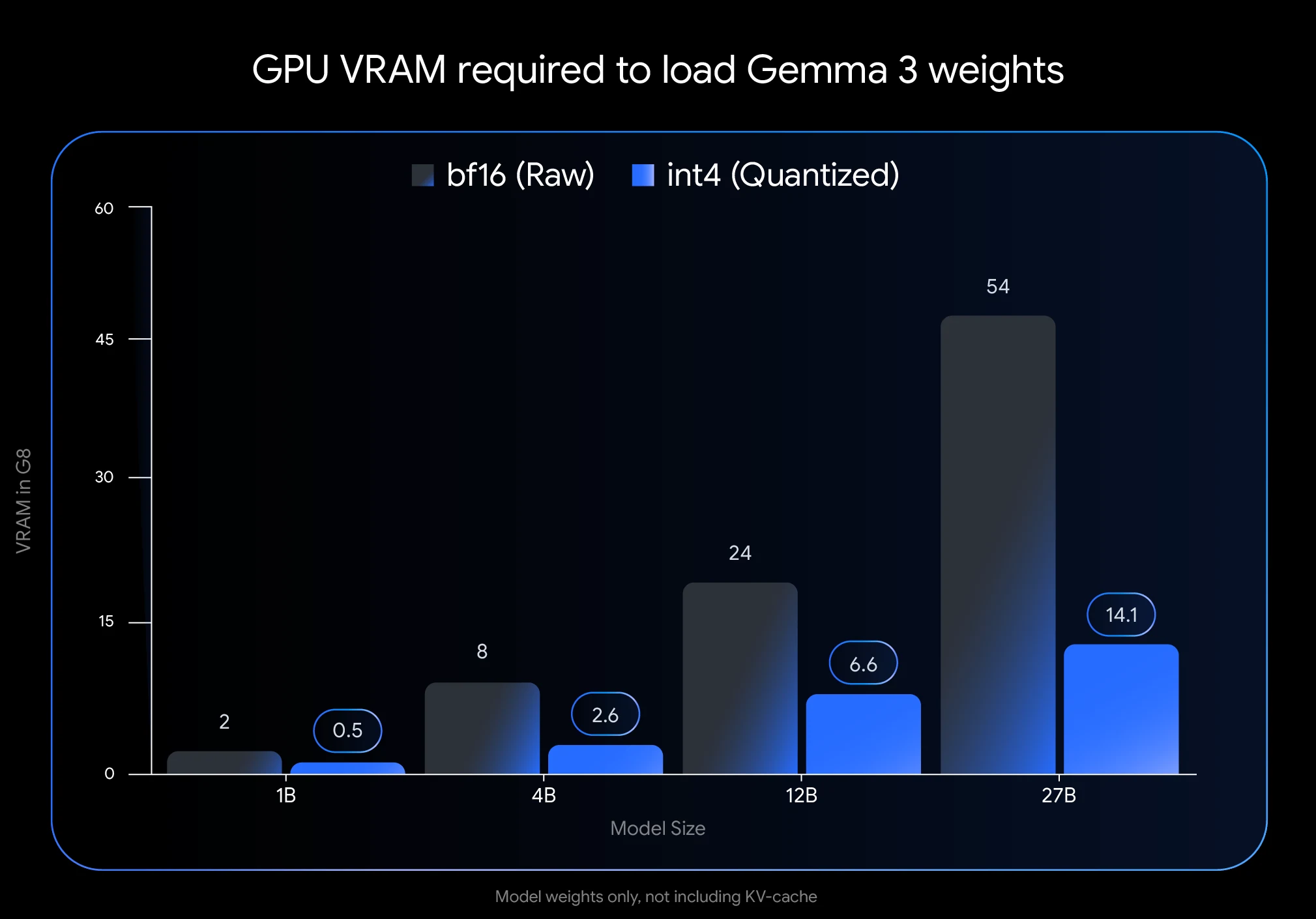
- 巨大的 VRAM 节省: 将 Gemma 3 27B 量化到 int4 可将其内存占用从 54GB(BF16)减少到仅 14.1GB,减少了 74%。这使得它可以在消费级 GPU(如具有 24GB VRAM 的 NVIDIA RTX 3090)上运行。
- 更广泛的硬件兼容性: 通过量化,你可以在桌面 GPU 上运行 Gemma 3 27B,而无需昂贵的数据中心硬件,从而普及对最先进 AI 的访问。
- 成本效益: 使用消费级硬件可显著降低部署和试验 Gemma 3 模型的成本。
- 保持性能: 得益于 Google 的量化感知训练(QAT)方法,量化后的模型尽管精度降低,但仍保持令人印象深刻的性能。QAT 在训练过程中融入量化,与标准的训练后量化相比,将困惑度下降降低了 54%。
Google 的 QAT 方法使用非量化检查点的概率作为目标,应用大约 5,000 个训练步骤,从而得到对量化影响具有鲁棒性的模型。
来源:https://developers.googleblog.com/
硬件与软件设置:准备运行
要有效运行量化后的 Gemma 3 27B,你需要以下配置:
硬件要求:
- GPU:至少 16GB VRAM 的消费级 GPU,例如 NVIDIA RTX 3090(24GB),以获得舒适的操作体验
- RAM:至少 32GB 系统内存
- 存储:SSD 存储,以便更快加载模型
软件要求:
- 最新的 CUDA 驱动和工具包
- Python 环境以及必要的库(Transformers、PyTorch 等)
- 根据你的方法,可能需要量化相关的库
部署的软件工具:
Google 与多种流行工具合作,使得部署量化后的 Gemma 3 模型变得简单:
- Ollama:原生支持 Gemma 3 QAT 模型,命令简单
- LM Studio:提供用户友好的界面来运行这些模型
- MLX:针对 Apple Silicon 上的高效推理进行了优化
- Gemma.cpp:用于 CPU 推理的专用 C++ 实现
- llama.cpp:支持 GGUF 格式的 QAT 模型,便于集成
在设置环境时,请注意两个关键考虑因素:
- 提到的 VRAM 数字(int4 量化后的 Gemma 3 27B 为 14.1GB)仅代表模型权重所需的空间。你还需要额外的 VRAM 用于 KV 缓存,它存储有关正在进行对话的信息。
- 不同的量化格式在内存效率和性能之间提供不同的权衡。Q4_0 格式在 Ollama、llama.cpp 和 MLX 等工具中得到广泛支持。
选择 Novita AI 来运行 Gemma 3 27B
在选择合适的云提供商来高效运行量化模型时,Novita AI 是一个理想的选择。Novita AI 提供强大的云 GPU 服务,利用诸如 NVIDIA A100 和 RTX 3090 等尖端 GPU,非常适合运行像 Gemma 3 27B 这样的大规模模型。Novita AI 通过以下几个关键优势简化了部署流程:
- 预优化环境:Novita AI 提供即用型环境,专门配置用于高效运行量化模型。
- 灵活的资源分配:根据你的需求向上或向下扩展资源,无需担心硬件限制。
- 简单的 API 集成:通过简单的 REST API 访问部署的模型,轻松集成到你的应用中。
- 成本管理:只为使用的资源付费,使高性能 AI 无需大量前期投资即可使用。
通过利用 Novita AI,你可以避免巨额的初期硬件成本,确保你的 Gemma 3 模型以最佳性能平稳运行。立即登录 Novita AI,解锁 Gemma 的全部潜力!

有关详细教程,请参考:分步指南:在 Novita AI GPU 实例上运行 Gemma 7B
结论
量化正在为大型语言模型的更高效、更具成本效益的部署铺平道路。正如 Gemma 3 27B 所展示的,降低模型的精度可以带来推理速度、内存效率和整体系统性能的显著提升,同时保持模型的稳健性。
通过了解 Gemma 3 27B 的架构和部署挑战,设置合适的环境,并利用像 Novita AI 这样的平台,你可以在不需要超级计算机的情况下充分利用这些先进的 AI 工具。我们希望本指南为你提供了开始 Gemma 3 27B 量化之旅所需的见解和可操作的步骤。
常见问题
什么是 Gemma 3 27B,为什么我要关心量化?
Gemma 3 27B 是 Google 最新的大型语言模型,通常需要高端硬件(如 NVIDIA H100 GPU)才能运行。量化降低了其内存需求,使其能够在消费级 GPU 上运行,同时保持性能。
什么是量化感知训练(QAT)?
QAT 是一种在训练过程中融入量化(而不仅仅是在之后应用)的技术。这有助于模型对量化影响更具鲁棒性,从而减少性能下降。Google 对 Gemma 3 模型应用了大约 5,000 个训练步骤的 QAT。
我可以在个人电脑上运行 Gemma 3 27B 吗?
可以,通过量化!int4 量化版本可以在消费级 GPU(如具有 24GB VRAM 的 NVIDIA RTX 3090)上运行,使其可供拥有相当不错的游戏/工作站硬件的爱好者和开发者使用。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的简便方式,同时也提供经济实惠且可靠的 GPU 云,用于构建和扩展。
推荐阅读



