

Le Gemma 3 27B de Google est une avancée majeure dans le domaine des modèles d’IA ouverts, offrant des performances de pointe sur du matériel grand public. Cependant, sa version en pleine précision nécessite d’importantes ressources de calcul. Grâce à la quantification — en particulier l’apprentissage conscient de la quantification (QAT) de Google — ce modèle devient accessible sans sacrifices majeurs de performances. Voici comment optimiser Gemma 3 27B pour plus d’efficacité.
Comprendre Gemma 3 27B
Gemma 3 27B est un modèle de langage de pointe qui combine une architecture avancée avec des données d’entraînement étendues pour offrir des capacités de modélisation linguistique de haute qualité. Sa conception lui permet de gérer diverses tâches — de la compréhension du langage naturel à la génération de texte — avec une grande compétence. Cependant, exécuter le modèle en pleine précision peut être intensif en calcul. Voici quelques points clés sur Gemma 3 27B :
- Architecture et échelle : Le modèle comprend 27 milliards de paramètres, le plaçant à l’avant-garde de la recherche moderne en IA.
- Exigences en ressources : L’exécution du modèle en pleine précision nécessite une mémoire et une puissance de traitement importantes, ce qui rend son déploiement difficile sur du matériel grand public.
- Cas d’usage : Malgré les besoins matériels, Gemma 3 27B est bien adapté à diverses applications, notamment les agents conversationnels, la génération de contenu et l’analyse de données en temps réel.
Pourquoi quantifier Gemma 3 27B ? Comprendre les avantages
La quantification réduit la précision des nombres utilisés pour représenter les paramètres du modèle. Au lieu d’utiliser 16 bits par nombre (BFloat16), la quantification permet d’utiliser moins de bits, comme 8 (int8) ou même 4 (int4), réduisant ainsi considérablement les besoins en mémoire.
Les avantages de la quantification de Gemma 3 27B incluent :
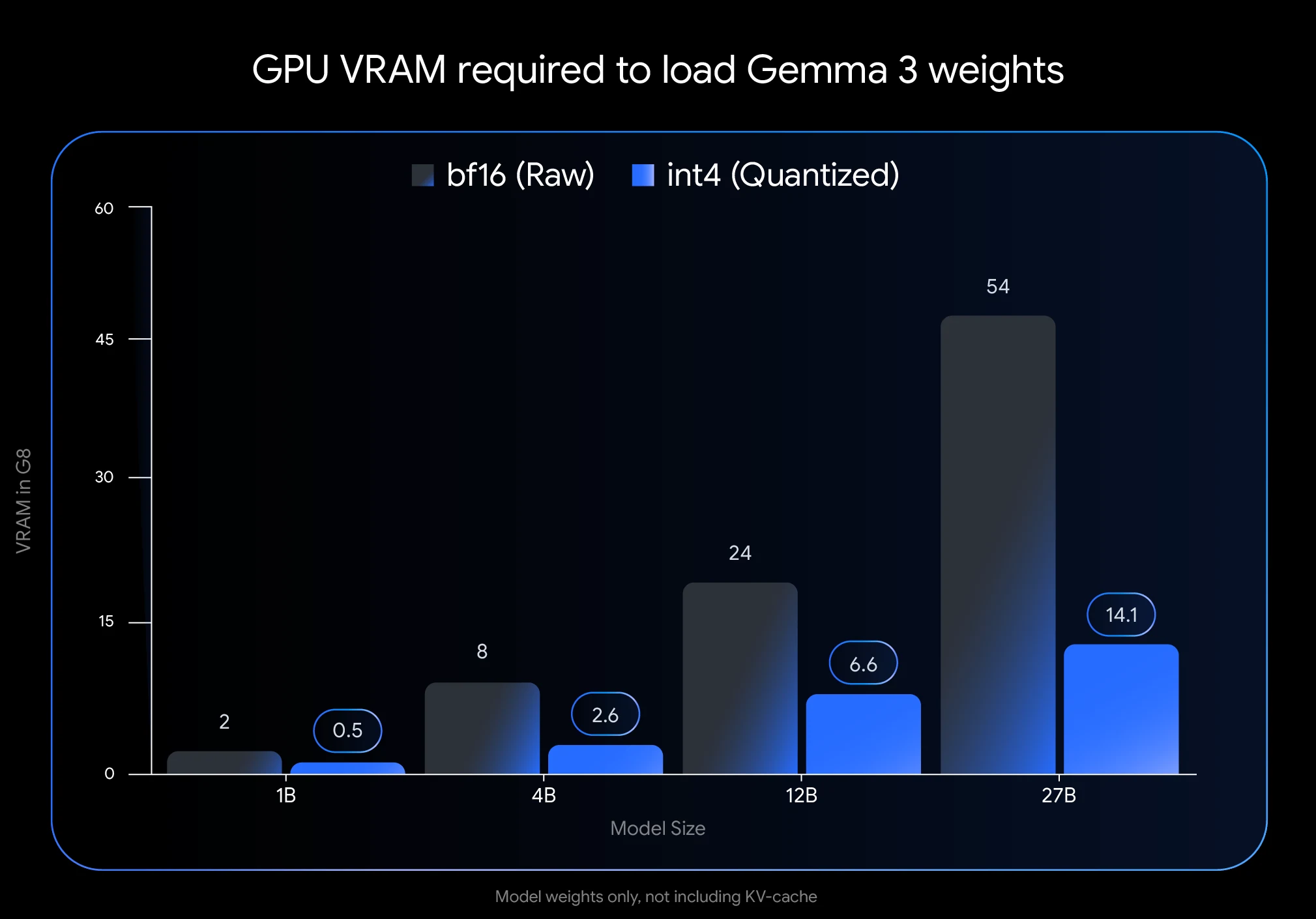
- Économies massives de VRAM : La quantification de Gemma 3 27B en int4 réduit son empreinte mémoire de 54 Go (BF16) à seulement 14,1 Go, soit une réduction de 74 %. Cela permet de l’exécuter sur des GPU grand public comme le NVIDIA RTX 3090 avec 24 Go de VRAM.
- Compatibilité matérielle élargie : Grâce à la quantification, vous pouvez exécuter Gemma 3 27B sur des GPU de bureau plutôt que d’avoir besoin de matériel de centre de données coûteux, démocratisant l’accès à une IA de pointe.
- Efficacité des coûts : L’utilisation de matériel grand public réduit considérablement le coût de déploiement et d’expérimentation avec les modèles Gemma 3.
- Performances maintenues : Grâce à l’approche d’apprentissage conscient de la quantification (QAT) de Google, les modèles quantifiés conservent une qualité impressionnante malgré la précision réduite. Le QAT intègre la quantification pendant le processus d’entraînement, réduisant les chutes de perplexité de 54 % par rapport à la quantification standard post-entraînement.
L’approche QAT de Google applique environ 5 000 pas d’entraînement en utilisant les probabilités du checkpoint non quantifié comme cibles, ce qui donne des modèles robustes aux effets de la quantification.
source : https://developers.googleblog.com/
Configuration matérielle et logicielle : se préparer à exécuter
Pour exécuter efficacement Gemma 3 27B quantifié, vous aurez besoin de ce qui suit :
Configuration matérielle :
- GPU : un GPU grand public avec au moins 16 Go de VRAM, comme le NVIDIA RTX 3090 (24 Go) pour un fonctionnement confortable
- RAM : 32 Go de mémoire système minimum
- Stockage : stockage SSD pour un chargement plus rapide du modèle
Configuration logicielle :
- Pilotes CUDA et toolkit récents
- Environnement Python avec les bibliothèques nécessaires (Transformers, PyTorch, etc.)
- Bibliothèques spécifiques à la quantification selon votre approche
Outils logiciels pour le déploiement :
Google s’est associé à plusieurs outils populaires pour faciliter le déploiement des modèles Gemma 3 quantifiés :
- Ollama : prend en charge nativement les modèles QAT Gemma 3 avec des commandes simples
- LM Studio : fournit une interface conviviale pour exécuter ces modèles
- MLX : optimisé pour une inférence efficace sur Apple Silicon
- Gemma.cpp : implémentation C++ dédiée pour l’inférence CPU
- llama.cpp : prend en charge les modèles QAT au format GGUF pour une intégration facile
Lors de la configuration de votre environnement, gardez deux points clés à l’esprit :
- Les chiffres de VRAM mentionnés (14,1 Go pour Gemma 3 27B quantifié en int4) ne représentent que l’espace nécessaire pour les poids du modèle. Vous aurez besoin de VRAM supplémentaire pour le cache KV, qui stocke les informations sur les conversations en cours.
- Différents formats de quantification offrent différents compromis entre efficacité mémoire et performances. Le format Q4_0 est largement pris en charge par des outils comme Ollama, llama.cpp et MLX.
Choisissez Novita AI pour exécuter Gemma 3 27B
Lors du choix du bon fournisseur cloud pour exécuter efficacement votre modèle quantifié, Novita AI se distingue comme un choix idéal. Novita AI propose des services GPU cloud robustes, utilisant des GPU de pointe comme le NVIDIA A100 et le RTX 3090, parfaits pour exécuter des modèles à grande échelle comme Gemma 3 27B. Novita AI simplifie le processus de déploiement avec plusieurs avantages clés :
- Environnements pré-optimisés : Novita AI fournit des environnements prêts à l’emploi, spécifiquement configurés pour exécuter efficacement des modèles quantifiés.
- Allocation flexible des ressources : Adaptez les ressources à la hausse ou à la baisse selon vos besoins, sans vous soucier des limitations matérielles.
- Intégration API simple : Accédez à vos modèles déployés via des API REST simples qui s’intègrent facilement à vos applications.
- Gestion des coûts : Ne payez que pour les ressources que vous utilisez, rendant l’IA haute performance accessible sans investissements initiaux massifs.
En utilisant Novita AI, vous évitez des coûts matériels initiaux substantiels, garantissant que votre modèle Gemma 3 fonctionne de manière optimale. Connectez-vous dès maintenant à Novita AI et libérez tout le potentiel de Gemma !

Essayez les GPU haute performance de Novita AI
Pour des tutoriels détaillés, veuillez consulter : Guide pas à pas : Exécuter Gemma 7B sur les instances GPU Novita AI
Conclusions
La quantification ouvre la voie à un déploiement plus efficace et plus rentable des grands modèles de langage. Comme démontré avec Gemma 3 27B, la réduction de la précision du modèle peut entraîner des améliorations significatives de la vitesse d’inférence, de l’efficacité mémoire et des performances globales du système, tout en maintenant la robustesse du modèle.
En comprenant l’architecture et les défis de déploiement de Gemma 3 27B, en configurant un environnement approprié et en utilisant des plateformes comme Novita AI, vous pouvez tirer le meilleur parti de ces outils d’IA avancés sans avoir besoin d’un supercalculateur. Nous espérons que ce guide vous a fourni les informations et les étapes concrètes nécessaires pour débuter votre parcours de quantification avec Gemma 3 27B.
Foire aux questions
Qu’est-ce que Gemma 3 27B et pourquoi devrais-je me soucier de la quantification ?
Gemma 3 27B est le dernier grand modèle de langage de Google qui nécessite normalement du matériel haut de gamme comme les GPU NVIDIA H100. La quantification réduit ses besoins en mémoire, permettant de l’exécuter sur des GPU grand public tout en maintenant les performances.
Qu’est-ce que l’apprentissage conscient de la quantification (QAT) ?
Le QAT est une technique qui intègre la quantification pendant le processus d’entraînement, plutôt que de l’appliquer seulement après. Cela aide les modèles à devenir plus robustes aux effets de la quantification, réduisant la dégradation des performances. Google a appliqué le QAT sur environ 5 000 pas d’entraînement pour les modèles Gemma 3.
Puis-je exécuter Gemma 3 27B sur mon ordinateur personnel ?
Oui, grâce à la quantification ! La version quantifiée en int4 peut être exécutée sur des GPU grand public comme le NVIDIA RTX 3090 avec 24 Go de VRAM, la rendant accessible aux passionnés et développeurs disposant d’un matériel de jeu/station de travail décent.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Lectures recommandées
Comment accéder à Gemma 3 27B localement, via API, sur GPU cloud
Configuration matérielle requise pour exécuter Gemma 3 : guide complet
Guide pas à pas : Exécuter Gemma 7B sur les instances GPU Novita AI



