

Das Gemma 3 27B von Google ist ein Durchbruch im Bereich offener KI-Modelle und liefert auf Consumer-Hardware Spitzenleistungen. Die Vollpräzisionsversion erfordert jedoch erhebliche Rechenressourcen. Durch Quantisierung – insbesondere Googles quantisierungsbewusstes Training (QAT) – wird dieses Modell zugänglich, ohne große Leistungseinbußen hinnehmen zu müssen. Hier erfahren Sie, wie Sie Gemma 3 27B für Effizienz optimieren.
Gemma 3 27B verstehen
Gemma 3 27B ist ein hochmodernes Sprachmodell, das fortschrittliche Architektur mit umfangreichen Trainingsdaten kombiniert, um hochwertige Sprachmodellierungsfähigkeiten zu bieten. Sein Design ermöglicht es, eine Vielzahl von Aufgaben – vom Verständnis natürlicher Sprache bis zur Textgenerierung – mit beeindruckender Leistungsfähigkeit zu bewältigen. Der Betrieb des Modells in voller Präzision kann jedoch rechenintensiv sein. Hier sind einige wichtige Punkte zu Gemma 3 27B:
- Architektur und Umfang: Das Modell besteht aus 27 Milliarden Parametern und steht damit an der Spitze der modernen KI-Forschung.
- Ressourcenanforderungen: Der Betrieb des Modells in voller Präzision erfordert erhebliche Speicher- und Rechenleistung, was den Einsatz auf Consumer-Hardware erschwert.
- Anwendungsfälle: Trotz der Hardwareanforderungen eignet sich Gemma 3 27B für verschiedene Anwendungen, darunter Dialogsysteme, Inhaltsgenerierung und Echtzeit-Datenanalyse.
Warum Gemma 3 27B quantisieren? Die Vorteile verstehen
Die Quantisierung reduziert die Genauigkeit der Zahlen, die zur Darstellung der Parameter des Modells verwendet werden. Anstatt 16 Bits pro Zahl (BFloat16) zu verwenden, erlaubt uns die Quantisierung, weniger Bits zu nutzen, z. B. 8 (int8) oder sogar 4 (int4), wodurch der Speicherbedarf drastisch reduziert wird.
Zu den Vorteilen der Quantisierung von Gemma 3 27B gehören:
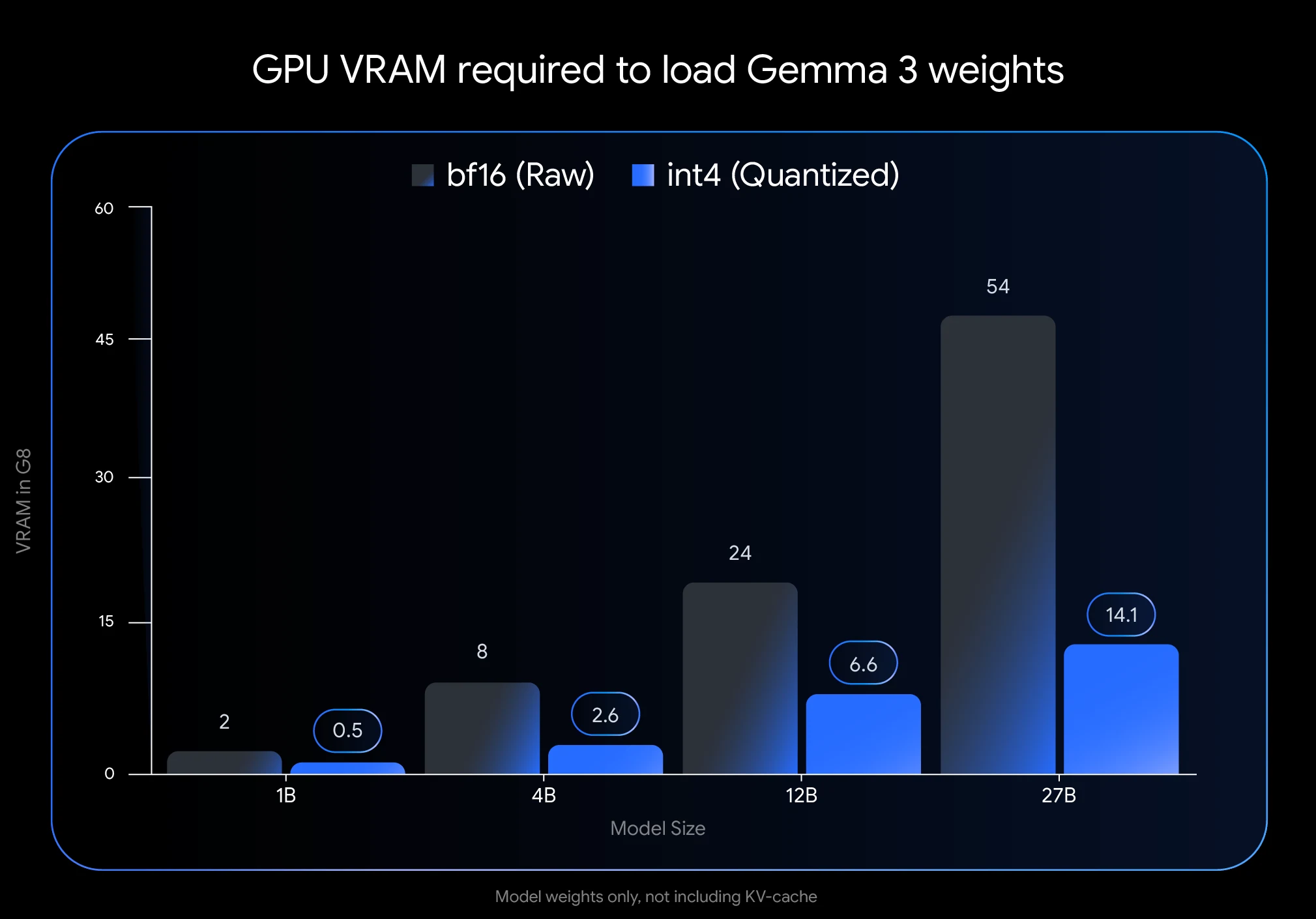
- Massive VRAM-Einsparungen: Die Quantisierung von Gemma 3 27B auf int4 reduziert den Speicherbedarf von 54 GB (BF16) auf nur 14,1 GB – eine Reduktion um 74 %. Dadurch wird der Betrieb auf Consumer-GPUs wie der NVIDIA RTX 3090 mit 24 GB VRAM möglich.
- Breitere Hardware-Kompatibilität: Durch die Quantisierung können Sie Gemma 3 27B auf Desktop-GPUs ausführen, anstatt teure Rechenzentrumshardware zu benötigen, und so den Zugang zu hochmoderner KI demokratisieren.
- Kosteneffizienz: Die Verwendung von Consumer-Hardware senkt die Kosten für die Bereitstellung und das Experimentieren mit Gemma 3 Modellen erheblich.
- Beibehaltung der Leistung: Dank Googles quantisierungsbewusstem Training (QAT) behalten die quantisierten Modelle trotz reduzierter Genauigkeit eine beeindruckende Qualität. QAT integriert die Quantisierung während des Trainingsprozesses und reduziert den Perplexitätsabfall im Vergleich zur standardmäßigen Nachbearbeitungsquantisierung um 54 %.
Googles QAT-Ansatz wendet etwa 5.000 Trainingsschritte an, wobei Wahrscheinlichkeiten des nicht quantisierten Checkpoints als Ziele verwendet werden. Das Ergebnis sind Modelle, die robust gegenüber Quantisierungseffekten sind.
Quelle: https://developers.googleblog.com/
Hardware- & Software-Setup: Bereit zum Ausführen
Um quantisiertes Gemma 3 27B effektiv auszuführen, benötigen Sie Folgendes:
Hardware-Anforderungen:
- GPU: Eine Consumer-GPU mit mindestens 16 GB VRAM, z. B. NVIDIA RTX 3090 (24 GB) für komfortablen Betrieb
- RAM: Mindestens 32 GB Systemspeicher
- Speicher: SSD-Speicher für schnellere Modellladung
Software-Anforderungen:
- Aktuelle CUDA-Treiber und Toolkit
- Python-Umgebung mit erforderlichen Bibliotheken (Transformers, PyTorch usw.)
- Quantisierungsspezifische Bibliotheken je nach gewähltem Ansatz
Software-Tools für die Bereitstellung:
Google hat Partnerschaften mit mehreren beliebten Tools geschlossen, um die Bereitstellung quantisierter Gemma 3 Modelle zu vereinfachen:
- Ollama: Unterstützt Gemma 3 QAT-Modelle nativ mit einfachen Befehlen
- LM Studio: Bietet eine benutzerfreundliche Oberfläche zum Ausführen dieser Modelle
- MLX: Optimiert für effiziente Inferenz auf Apple Silicon
- Gemma.cpp: Dedizierte C+±Implementierung für CPU-Inferenz
- llama.cpp: Unterstützt GGUF-formattierte QAT-Modelle zur einfachen Integration
Beachten Sie bei der Einrichtung Ihrer Umgebung zwei wichtige Aspekte:
- Die genannten VRAM-Werte (14,1 GB für int4-quantisiertes Gemma 3 27B) beziehen sich nur auf den Speicherbedarf für die Modellgewichte. Sie benötigen zusätzlichen VRAM für den KV-Cache, der Informationen über laufende Gespräche speichert.
- Verschiedene Quantisierungsformate bieten unterschiedliche Abwägungen zwischen Speichereffizienz und Leistung. Das Format Q4_0 wird von Tools wie Ollama, llama.cpp und MLX weitgehend unterstützt.
Wählen Sie Novita AI zum Ausführen von Gemma 3 27B
Bei der Auswahl des richtigen Cloud-Anbieters für den effizienten Betrieb Ihres quantisierten Modells zeichnet sich Novita AI als ideale Wahl aus. Novita AI bietet robuste Cloud-GPU-Dienste mit hochmodernen GPUs wie der NVIDIA A100 und RTX 3090, die sich perfekt für den Betrieb großer Modelle wie Gemma 3 27B eignen. Novita AI vereinfacht den Bereitstellungsprozess mit mehreren entscheidenden Vorteilen:
- Voroptimierte Umgebungen: Novita AI bietet gebrauchsfertige Umgebungen, die speziell für den effizienten Betrieb quantisierter Modelle konfiguriert sind.
- Flexible Ressourcenzuweisung: Skalieren Sie Ressourcen je nach Bedarf nach oben oder unten, ohne sich um Hardwareeinschränkungen sorgen zu müssen.
- Einfache API-Integration: Greifen Sie über unkomplizierte REST-APIs auf Ihre bereitgestellten Modelle zu, die sich leicht in Ihre Anwendungen integrieren lassen.
- Kostenmanagement: Bezahlen Sie nur für die Ressourcen, die Sie nutzen, sodass leistungsstarke KI ohne große Vorabinvestitionen zugänglich wird.
Durch die Nutzung von Novita AI vermeiden Sie erhebliche anfängliche Hardwarekosten und stellen sicher, dass Ihr Gemma 3 Modell reibungslos mit Spitzenleistung arbeitet. Melden Sie sich jetzt bei Novita AI an und schöpfen Sie das volle Potenzial von Gemma aus!

[Hochleistungs-GPUs von Novita AI ausprobieren](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks)
Ausführliche Anleitungen finden Sie unter: Schritt-für-Schritt-Anleitung: Gemma 7B auf Novita AI GPU-Instanzen ausführen
Fazit
Die Quantisierung ebnet den Weg für eine effizientere und kostengünstigere Bereitstellung großer Sprachmodelle. Wie am Beispiel von Gemma 3 27B gezeigt, kann die Reduzierung der Modellgenauigkeit zu erheblichen Verbesserungen bei Inferenzgeschwindigkeit, Speichereffizienz und Gesamtsystemleistung führen – während gleichzeitig die Robustheit des Modells erhalten bleibt.
Indem Sie die Architektur und die Bereitstellungsherausforderungen von Gemma 3 27B verstehen, eine geeignete Umgebung einrichten und Plattformen wie Novita AI nutzen, können Sie das Beste aus diesen fortschrittlichen KI-Tools herausholen, ohne einen Supercomputer zu benötigen. Wir hoffen, dass dieser Leitfaden Ihnen die Erkenntnisse und umsetzbaren Schritte bietet, die Sie für den Einstieg in die Quantisierung mit Gemma 3 27B benötigen.
Häufig gestellte Fragen
Was ist Gemma 3 27B und warum sollte mich Quantisierung interessieren?
Gemma 3 27B ist das neueste große Sprachmodell von Google, das normalerweise High-End-Hardware wie NVIDIA H100 GPUs erfordert. Die Quantisierung reduziert den Speicherbedarf, sodass es auf Consumer-GPUs ausgeführt werden kann, während die Leistung erhalten bleibt.
Was ist quantisierungsbewusstes Training (QAT)?
QAT ist eine Technik, die die Quantisierung während des Trainingsprozesses integriert, anstatt sie erst nachträglich anzuwenden. Dies hilft Modellen, robuster gegenüber Quantisierungseffekten zu werden und Leistungseinbußen zu reduzieren. Google hat QAT in etwa 5.000 Trainingsschritten für die Gemma 3 Modelle angewendet.
Kann ich Gemma 3 27B auf meinem persönlichen Computer ausführen?
Ja, mit Quantisierung! Die int4-quantisierte Version kann auf Consumer-GPUs wie der NVIDIA RTX 3090 mit 24 GB VRAM ausgeführt werden, was sie für Enthusiasten und Entwickler mit anständiger Gaming-/Workstation-Hardware zugänglich macht.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks) ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle mit unserer einfachen API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Empfohlene Lektüre
So greifen Sie lokal, über API und auf der Cloud-GPU auf Gemma 3 27B zu
[Hardware-Anforderungen für die Ausführung von Gemma 3: Eine vollständige Anleitung](http://Hardware Requirements for Running Gemma 3: A Complete Guide)
[Schritt-für-Schritt-Anleitung: Gemma 7B auf Novita AI GPU-Instanzen ausführen](http://Step-by-Step Guide: Running Gemma 7B on Novita AI GPU Instances)



