

Google の Gemma 3 27B は、オープン AI モデルの画期的な進歩であり、コンシューマー向けハードウェアで最先端のパフォーマンスを実現します。しかし、フルプレシジョンバージョンは多大な計算リソースを必要とします。量子化(特に Google の量子化対応トレーニング QAT)により、パフォーマンスを大幅に犠牲にすることなく、このモデルにアクセスできるようになります。ここでは、Gemma 3 27B を効率的に最適化する方法を紹介します。
Gemma 3 27B を理解する
Gemma 3 27B は、高度なアーキテクチャと広範なトレーニングデータを組み合わせ、高品質な言語モデリング機能を提供する最先端の言語モデルです。その設計により、自然言語理解からテキスト生成まで、さまざまなタスクを優れた熟練度で処理できます。ただし、フルプレシジョンでモデルを実行するには、計算負荷が高くなる可能性があります。以下に、Gemma 3 27B に関するいくつかの重要なポイントを示します。
- アーキテクチャと規模: このモデルは 270 億のパラメータで構成され、現代の AI 研究の最前線に位置しています。
- リソース要件: フルプレシジョンでモデルを実行するには、大量のメモリと処理能力が必要であり、コンシューマーグレードのハードウェアにデプロイするのは困難です。
- ユースケース: ハードウェア要件はあるものの、Gemma 3 27B は、会話型エージェント、コンテンツ生成、リアルタイムデータ分析など、さまざまなアプリケーションに適しています。
Gemma 3 27B を量子化する理由:そのメリットを理解する
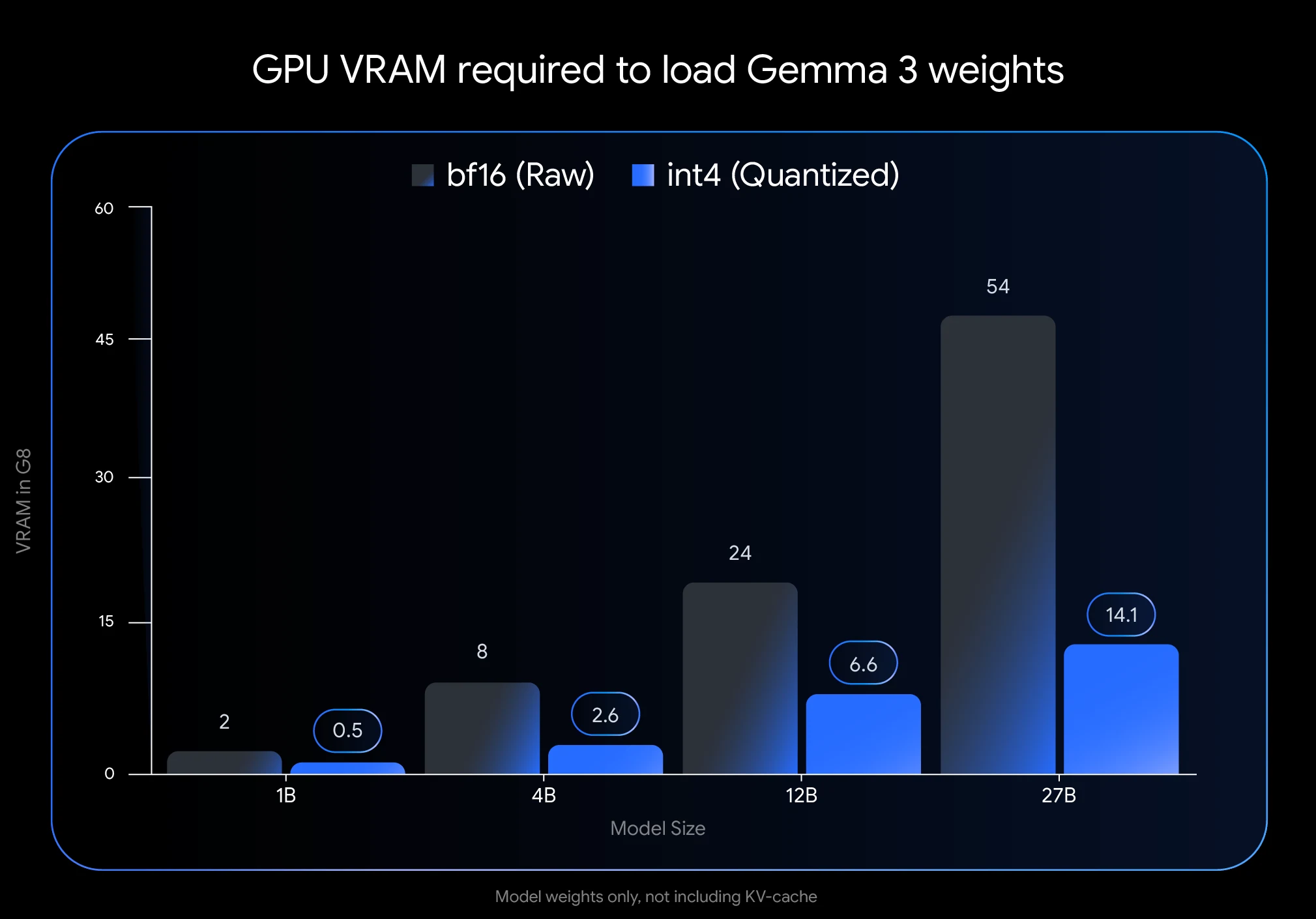
量子化は、モデルのパラメータを表す数値の精度を下げます。数値あたり 16 ビット(BFloat16)を使用する代わりに、量子化により 8(int8)や 4(int4)などのより少ないビットを使用できるため、メモリ要件が劇的に削減されます。
Gemma 3 27B を量子化するメリットは次のとおりです。
- 大幅な VRAM 節約: Gemma 3 27B を int4 に量子化すると、メモリフットプリントが 54GB(BF16)からわずか 14.1GB に削減され、74% 削減されます。これにより、24GB VRAM の NVIDIA RTX 3090 などのコンシューマーグレード GPU で実行できるようになります。
- より広範なハードウェア互換性: 量子化により、高価なデータセンターハードウェアを必要とせずに、デスクトップ GPU で Gemma 3 27B を実行できるため、最先端の AI へのアクセスが民主化されます。
- コスト効率: コンシューマーハードウェアを使用すると、Gemma 3 モデルのデプロイと実験のコストが大幅に削減されます。
- パフォーマンスの維持: Google の量子化対応トレーニング(QAT)アプローチのおかげで、量子化されたモデルは精度が低下しても、印象的な品質を維持します。QAT はトレーニングプロセス中に量子化を組み込むため、標準的なトレーニング後の量子化と比較して、パープレキシティの低下を 54% 削減します。
Google の QAT アプローチでは、非量子化チェックポイントの確率をターゲットとして約 5,000 のトレーニングステップを適用し、量子化の影響に対してロバストなモデルを生成します。
出典:https://developers.googleblog.com/
ハードウェアとソフトウェアのセットアップ:実行準備
量子化された Gemma 3 27B を効果的に実行するには、以下が必要です。
ハードウェア要件:
- GPU:快適に動作させるために、少なくとも 16GB VRAM を搭載したコンシューマーグレードの GPU(例:NVIDIA RTX 3090(24GB))
- RAM:最低 32GB のシステムメモリ
- ストレージ:モデルのロードを高速化するための SSD ストレージ
ソフトウェア要件:
- 最新の CUDA ドライバーとツールキット
- 必要なライブラリ(Transformers、PyTorch など)を備えた Python 環境
- アプローチに応じた量子化固有のライブラリ
デプロイのためのソフトウェアツール:
Google はいくつかの人気ツールと提携しており、量子化された Gemma 3 モデルのデプロイを簡単に行えます。
- Ollama:シンプルなコマンドで Gemma 3 QAT モデルをネイティブサポート
- LM Studio:これらのモデルを実行するためのユーザーフレンドリーなインターフェースを提供
- MLX:Apple Silicon での効率的な推論に最適化
- Gemma.cpp:CPU 推論専用の C++ 実装
- llama.cpp:簡単な統合のために GGUF 形式の QAT モデルをサポート
環境をセットアップする際は、次の 2 つの重要な考慮事項に注意してください。
- 前述の VRAM 数値(int4 量子化 Gemma 3 27B で 14.1GB)は、モデルの重みに必要なスペースのみを表しています。KV キャッシュ(進行中の会話に関する情報を保存)には追加の VRAM が必要です。
- 量子化フォーマットが異なると、メモリ効率とパフォーマンスのトレードオフが異なります。Q4_0 フォーマットは、Ollama、llama.cpp、MLX などのツールで広くサポートされています。
Gemma 3 27B の実行には Novita AI を選ぶ
量子化されたモデルを効率的に実行するための適切なクラウドプロバイダーを選択する場合、Novita AI は理想的な選択肢として際立っています。Novita AI は、NVIDIA A100 や RTX 3090 などの最先端 GPU を活用した堅牢なクラウド GPU サービスを提供しており、Gemma 3 27B のような大規模モデルの実行に最適です。Novita AI は、以下の主要な利点によりデプロイプロセスを簡素化します。
- 事前最適化された環境: Novita AI は、量子化モデルを効率的に実行するために特別に設定された、すぐに使える環境を提供します。
- 柔軟なリソース割り当て: ハードウェアの制限を気にせず、ニーズに応じてリソースを拡大または縮小できます。
- シンプルな API 統合: アプリケーションに簡単に統合できるシンプルな REST API を通じて、デプロイされたモデルにアクセスできます。
- コスト管理: 使用したリソースに対してのみ支払うため、多額の先行投資なしでハイパフォーマンス AI を利用できます。
Novita AI を活用することで、多額のハードウェア初期費用を回避し、Gemma 3 モデルをピークパフォーマンスでスムーズに運用できます。今すぐ Novita AI にログインして、Gemma の可能性を最大限に引き出しましょう!

[Novita AI のハイパフォーマンス GPU を試す](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks)
詳細なチュートリアルについては、次の手順ガイドを参照してください:Novita AI GPU インスタンスで Gemma 7B を実行する手順ガイド
結論
量子化は、大規模言語モデルのより効率的でコスト効果の高いデプロイへの道を開いています。Gemma 3 27B で示されたように、モデルの精度を下げることで、モデルのロバスト性を維持しながら、推論速度、メモリ効率、およびシステム全体のパフォーマンスを大幅に向上させることができます。
Gemma 3 27B のアーキテクチャとデプロイの課題を理解し、適切な環境をセットアップし、Novita AI などのプラットフォームを活用することで、スーパーコンピューターを必要とせずにこれらの高度な AI ツールを最大限に活用できます。このガイドが、Gemma 3 27B による量子化の旅を始めるための洞察と実用的な手順を提供できたことを願っています。
よくある質問
Gemma 3 27B とは何ですか?量子化について知る必要がある理由は?
Gemma 3 27B は Google の最新の大規模言語モデルで、通常は NVIDIA H100 GPU などの高性能ハードウェアが必要です。量子化によりメモリ要件が削減され、パフォーマンスを維持しながらコンシューマーグレードの GPU で実行できるようになります。
量子化対応トレーニング(QAT)とは何ですか?
QAT は、量子化を後から適用するのではなく、トレーニングプロセスに組み込む手法です。これにより、モデルが量子化の影響に対してよりロバストになり、パフォーマンスの低下を抑えることができます。Google は Gemma 3 モデルに対して約 5,000 のトレーニングステップで QAT を適用しました。
Gemma 3 27B を自分のパソコンで実行できますか?
はい、量子化を使用すれば可能です!int4 量子化バージョンは、24GB VRAM の NVIDIA RTX 3090 などのコンシューマー GPU で実行できるため、適切なゲーミング/ワークステーションハードウェアを持つ愛好家や開発者がアクセスできます。
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks) は、シンプルな API を使用して AI モデルを簡単にデプロイできる方法を開発者に提供するとともに、ビルドとスケーリングのための手頃で信頼性の高い GPU クラウドを提供する AI クラウドプラットフォームです。
おすすめの読み物
Gemma 3 27B にローカル、API、クラウド GPU でアクセスする方法
[Gemma 3 を実行するためのハードウェア要件:完全ガイド](http://Hardware Requirements for Running Gemma 3: A Complete Guide)
[ステップバイステップガイド:Novita AI GPU インスタンスで Gemma 7B を実行する](http://Step-by-Step Guide: Running Gemma 7B on Novita AI GPU Instances)



