

يمثل نموذج Gemma 3 27B من Google طفرة في نماذج الذكاء الاصطناعي مفتوحة المصدر، حيث يقدم أداءً متطورًا على الأجهزة الاستهلاكية. ومع ذلك، فإن نسخته كاملة الدقة تتطلب موارد حاسوبية كبيرة. من خلال التحويل الكمي — وخاصة التدريب الواعي بالتحويل الكمي (QAT) من Google — يصبح هذا النموذج متاحًا دون تضحيات كبيرة في الأداء. إليك كيفية تحسين Gemma 3 27B لتحقيق الكفاءة.
فهم Gemma 3 27B
Gemma 3 27B هو نموذج لغوي متطور يجمع بين بنية متقدمة وبيانات تدريب واسعة لتقديم قدرات نمذجة لغوية عالية الجودة. يتيح له تصميمه التعامل مع مجموعة متنوعة من المهام — من فهم اللغة الطبيعية إلى توليد النصوص — بمهارة مذهلة. ومع ذلك، فإن تشغيل النموذج بدقة كاملة قد يكون مكلفًا حسابيًا. إليك بعض النقاط الرئيسية حول Gemma 3 27B:
- البنية والحجم: يتكون النموذج من 27 مليار معلمة، مما يضعه في طليعة أبحاث الذكاء الاصطناعي الحديثة.
- متطلبات الموارد: يتطلب تشغيل النموذج بدقة كاملة ذاكرة وقدرة معالجة كبيرة، مما يجعل نشره على أجهزة المستهلكين أمرًا صعبًا.
- حالات الاستخدام: على الرغم من متطلبات الأجهزة، فإن Gemma 3 27B مناسب تمامًا لمجموعة متنوعة من التطبيقات بما في ذلك وكلاء المحادثة، وتوليد المحتوى، وتحليل البيانات في الوقت الفعلي.
لماذا تحويل Gemma 3 27B إلى صيغة كمية؟ فهم الفوائد
يقلل التحويل الكمي من دقة الأرقام المستخدمة لتمثيل معلمات النموذج. بدلاً من استخدام 16 بت لكل رقم (BFloat16)، يسمح لنا التحويل الكمي باستخدام عدد أقل من البتات، مثل 8 (int8) أو حتى 4 (int4)، مما يقلل بشكل كبير من متطلبات الذاكرة.
تشمل فوائد تحويل Gemma 3 27B إلى صيغة كمية ما يلي:
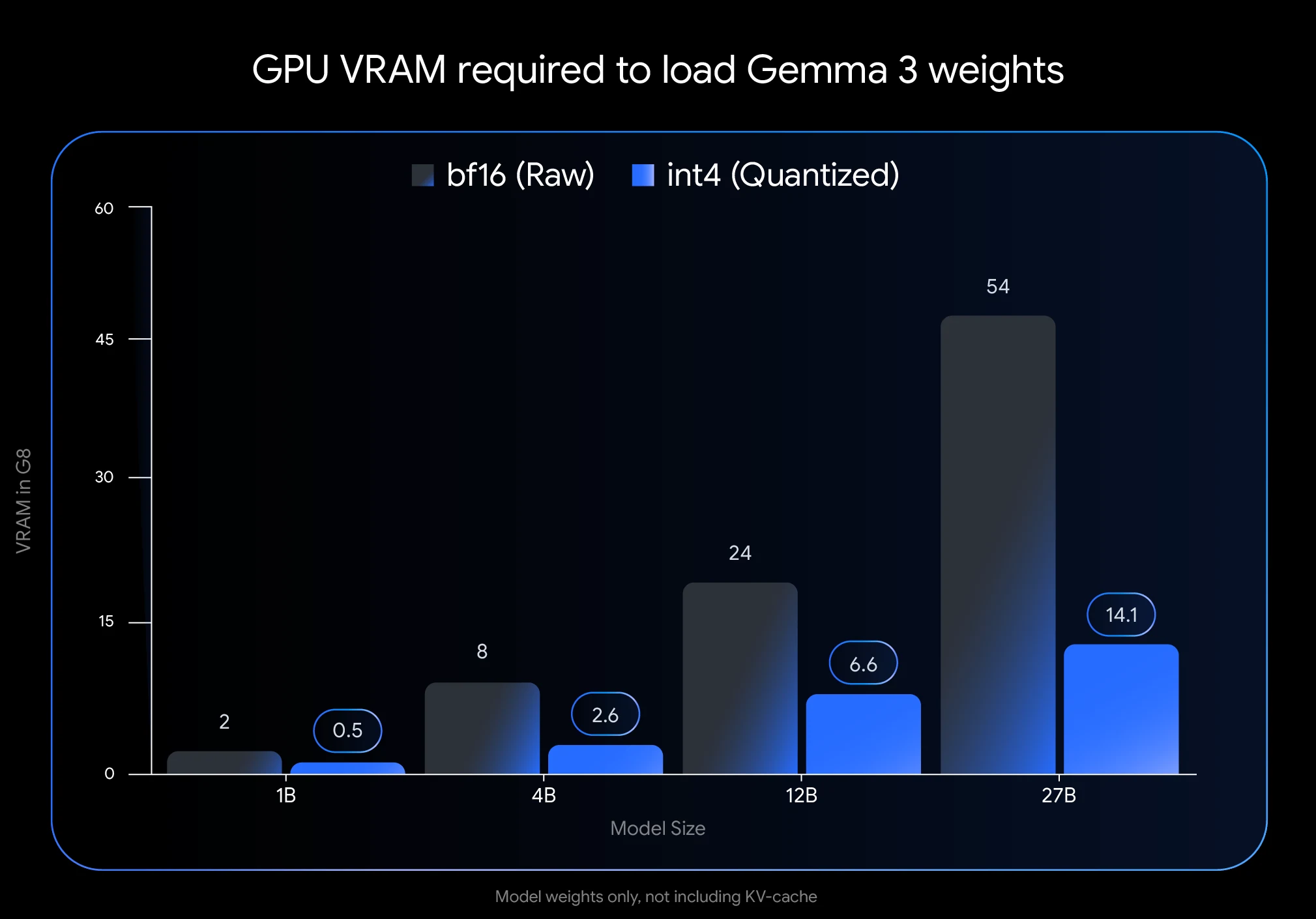
- توفير هائل في VRAM: يؤدي تحويل Gemma 3 27B إلى int4 إلى تقليل بصمة الذاكرة من 54 جيجابايت (BF16) إلى 14.1 جيجابايت فقط، أي بنسبة 74%. هذا يجعل من الممكن تشغيله على وحدات معالجة رسومية استهلاكية مثل NVIDIA RTX 3090 بسعة 24 جيجابايت VRAM.
- توافق أوسع مع الأجهزة: بفضل التحويل الكمي، يمكنك تشغيل Gemma 3 27B على وحدات معالجة رسومية مكتبية بدلاً من الحاجة إلى أجهزة مراكز بيانات باهظة الثمن، مما يضفي طابعًا ديمقراطيًا على الوصول إلى الذكاء الاصطناعي المتطور.
- كفاءة التكلفة: يؤدي استخدام الأجهزة الاستهلاكية إلى تقليل تكلفة نشر وتجربة نماذج Gemma 3 بشكل كبير.
- الحفاظ على الأداء: بفضل نهج التدريب الواعي بالتحويل الكمي (QAT) من Google، تحافظ النماذج المحولة كميًا على جودة مذهلة على الرغم من الدقة المنخفضة. يدمج QAT عملية التحويل الكمي أثناء عملية التدريب، مما يقلل من انخفاض الارتباك بنسبة 54% مقارنة بالتحويل الكمي القياسي بعد التدريب.
يطبق نهج Google لـ QAT حوالي 5000 خطوة تدريب باستخدام الاحتمالات من نقطة التفتيش غير المحولة كميًا كأهداف، مما ينتج نماذج مقاومة لتأثيرات التحويل الكمي.
المصدر: https://developers.googleblog.com/
إعداد الأجهزة والبرامج: الاستعداد للتشغيل
لتشغيل Gemma 3 27B المحول كميًا بشكل فعال، ستحتاج إلى ما يلي:
متطلبات الأجهزة:
- GPU: وحدة معالجة رسومية استهلاكية بسعة ذاكرة VRAM لا تقل عن 16 جيجابايت، مثل NVIDIA RTX 3090 (24 جيجابايت) للتشغيل المريح.
- RAM: ذاكرة نظام بحد أدنى 32 جيجابايت.
- التخزين: تخزين SSD لتحميل النموذج بشكل أسرع.
متطلبات البرامج:
- برامج تشغيل CUDA ومجموعة أدوات حديثة.
- بيئة Python مع المكتبات اللازمة (مثل Transformers و PyTorch).
- مكتبات خاصة بالتحويل الكمي حسب النهج المتبع.
أدوات برمجية للنشر:
تعاونت Google مع العديد من الأدوات الشائعة لتسهيل نشر نماذج Gemma 3 المحولة كميًا:
- Ollama: يدعم نماذج Gemma 3 QAT بشكل أصلي بأوامر بسيطة.
- LM Studio: يوفر واجهة سهلة الاستخدام لتشغيل هذه النماذج.
- MLX: محسّن للاستدلال الفعال على أجهزة Apple Silicon.
- Gemma.cpp: تطبيق مخصص بلغة C++ للاستدلال على وحدة المعالجة المركزية.
- llama.cpp: يدعم نماذج QAT بتنسيق GGUF للتكامل السهل.
عند إعداد بيئتك، ضع في اعتبارك اعتبارين رئيسيين:
- أرقام VRAM المذكورة (14.1 جيجابايت لـ Gemma 3 27B المحول كميًا إلى int4) تمثل فقط المساحة اللازمة لأوزان النموذج. ستحتاج إلى مساحة VRAM إضافية لذاكرة التخزين المؤقت KV، التي تخزن معلومات المحادثات الجارية.
- تقدم تنسيقات التحويل الكمي المختلفة مقايضات مختلفة بين كفاءة الذاكرة والأداء. يُعد تنسيق Q4_0 مدعومًا على نطاق واسع عبر أدوات مثل Ollama و llama.cpp و MLX.
اختر Novita AI لتشغيل Gemma 3 27B
عند اختيار مزود الخدمة السحابية المناسب لتشغيل نموذجك المحول كميًا بكفاءة، تبرز Novita AI كخيار مثالي. تقدم Novita AI خدمات GPU سحابية قوية، باستخدام وحدات معالجة رسومية متطورة مثل NVIDIA A100 و RTX 3090، وهي مثالية لتشغيل النماذج واسعة النطاق مثل Gemma 3 27B. تبسط Novita AI عملية النشر بعدة مزايا رئيسية:
- بيئات محسّنة مسبقًا: توفر Novita AI بيئات جاهزة للاستخدام ومهيأة خصيصًا لتشغيل النماذج المحولة كميًا بكفاءة.
- تخصيص مرن للموارد: يمكنك زيادة أو تقليل الموارد وفقًا لاحتياجاتك دون القلق بشأن قيود الأجهزة.
- دمج API بسيط: الوصول إلى نماذجك المنشورة عبر واجهات REST API مباشرة تتكامل بسهولة مع تطبيقاتك.
- إدارة التكاليف: ادفع فقط مقابل الموارد التي تستخدمها، مما يجعل الذكاء الاصطناعي عالي الأداء في متناول اليد دون استثمارات أولية ضخمة.
من خلال الاستفادة من Novita AI، يمكنك تجنب التكاليف الكبيرة للأجهزة الأولية، وضمان تشغيل نموذج Gemma 3 الخاص بك بأداء مثالي. سجل الدخول إلى Novita AI الآن وأطلق العنان للإمكانات الكاملة لـ Gemma!

[جرّب وحدات GPU عالية الأداء من Novita AI](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks)
للحصول على دروس تعليمية مفصلة، يرجى الرجوع إلى: دليل خطوة بخطوة: تشغيل Gemma 7B على مثيلات GPU من Novita AI
الاستنتاجات
يمهد التحويل الكمي الطريق لنشر أكثر كفاءة وفعالية من حيث التكلفة لنماذج اللغة الكبيرة. كما هو موضح مع Gemma 3 27B، يمكن أن يؤدي تقليل دقة النموذج إلى تحسينات كبيرة في سرعة الاستدلال، وكفاءة الذاكرة، والأداء العام للنظام — مع الحفاظ على قوة النموذج.
من خلال فهم بنية وتحديات نشر Gemma 3 27B، وإعداد بيئة مناسبة، واستخدام منصات مثل Novita AI، يمكنك تحقيق أقصى استفادة من هذه الأدوات الذكية المتقدمة دون الحاجة إلى حاسوب فائق. نأمل أن يكون هذا الدليل قد قدم لك الرؤى والخطوات العملية اللازمة لبدء رحلتك مع التحويل الكمي لـ Gemma 3 27B.
الأسئلة المتكررة
ما هو Gemma 3 27B ولماذا يجب أن أهتم بالتحويل الكمي؟
Gemma 3 27B هو أحدث نموذج لغوي كبير من Google يتطلب عادةً أجهزة عالية المستوى مثل NVIDIA H100 GPU. يقلل التحويل الكمي من متطلبات الذاكرة، مما يسمح بتشغيله على وحدات معالجة رسومية استهلاكية مع الحفاظ على الأداء.
ما هو التدريب الواعي بالتحويل الكمي (QAT)؟
QAT هو أسلوب يدمج التحويل الكمي أثناء عملية التدريب، بدلاً من تطبيقه فقط بعد ذلك. يساعد ذلك النماذج على أن تصبح أكثر مقاومة لتأثيرات التحويل الكمي، مما يقلل من تدهور الأداء. طبقت Google QAT على حوالي 5000 خطوة تدريب لنماذج Gemma 3.
هل يمكنني تشغيل Gemma 3 27B على جهاز الكمبيوتر الشخصي الخاص بي؟
نعم، مع التحويل الكمي! يمكن تشغيل النسخة المحولة كميًا إلى int4 على وحدات معالجة رسومية استهلاكية مثل NVIDIA RTX 3090 بسعة 24 جيجابايت VRAM، مما يجعلها في متناول المتحمسين والمطورين الذين لديهم أجهزة ألعاب/محطات عمل لائقة.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks) عبارة عن منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط، مع توفير GPU سحابي ميسور التكلفة وموثوق للبناء والتوسع.
قراءات موصى بها
كيفية الوصول إلى Gemma 3 27B محليًا، عبر API، على GPU سحابي
[متطلبات الأجهزة لتشغيل Gemma 3: دليل كامل](http://Hardware Requirements for Running Gemma 3: A Complete Guide)
[دليل خطوة بخطوة: تشغيل Gemma 7B على مثيلات GPU من Novita AI](http://Step-by-Step Guide: Running Gemma 7B on Novita AI GPU Instances)



