

Gemma 3 27B от Google — это прорыв в области открытых моделей ИИ, обеспечивающий передовую производительность на потребительском оборудовании. Однако её версия с полной точностью требует значительных вычислительных ресурсов. Благодаря квантизации — особенно обучению с учётом квантизации (Quantization-Aware Training, QAT) от Google — эта модель становится доступной без существенных потерь в производительности. Вот как оптимизировать Gemma 3 27B для эффективной работы.
Понимание Gemma 3 27B
Gemma 3 27B — это современная языковая модель, которая сочетает передовую архитектуру с обширными обучающими данными, обеспечивая высокое качество языкового моделирования. Её конструкция позволяет справляться с разнообразными задачами — от понимания естественного языка до генерации текста — с впечатляющей эффективностью. Однако запуск модели с полной точностью может быть вычислительно затратным. Вот несколько ключевых моментов о Gemma 3 27B:
- Архитектура и масштаб: Модель состоит из 27 миллиардов параметров, что ставит её на передовые позиции в современных исследованиях ИИ.
- Требования к ресурсам: Запуск модели с полной точностью требует значительного объёма памяти и вычислительной мощности, что затрудняет её развёртывание на оборудовании потребительского уровня.
- Варианты использования: Несмотря на высокие требования к оборудованию, Gemma 3 27B отлично подходит для различных приложений, включая диалоговые агенты, генерацию контента и анализ данных в реальном времени.
Зачем квантизировать Gemma 3 27B? Понимание преимуществ
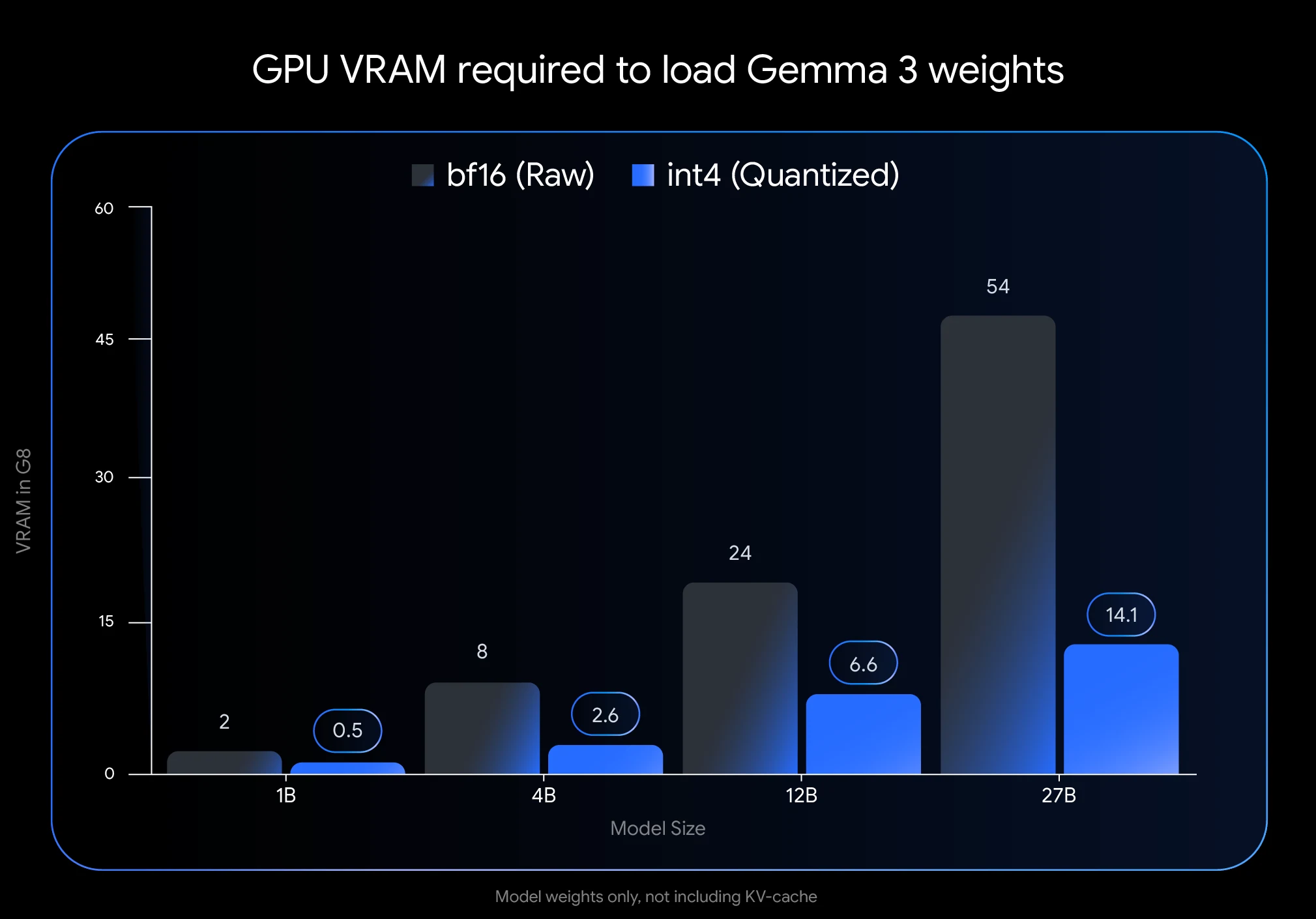
Квантизация снижает точность чисел, используемых для представления параметров модели. Вместо 16 бит на число (BFloat16) квантизация позволяет использовать меньше битов, например 8 (int8) или даже 4 (int4), что значительно уменьшает требования к памяти.
Преимущества квантизации Gemma 3 27B включают:
- Значительная экономия видеопамяти (VRAM): Квантизация Gemma 3 27B до int4 сокращает объём занимаемой памяти с 54 ГБ (BF16) до всего 14,1 ГБ — снижение на 74%. Это позволяет запускать модель на потребительских GPU, таких как NVIDIA RTX 3090 с 24 ГБ VRAM.
- Более широкая совместимость с оборудованием: Благодаря квантизации вы можете запускать Gemma 3 27B на настольных GPU вместо дорогостоящего дата-центрового оборудования, демократизируя доступ к передовым ИИ.
- Экономическая эффективность: Использование потребительского оборудования значительно снижает затраты на развёртывание и эксперименты с моделями Gemma 3.
- Сохранение производительности: Благодаря подходу Google к обучению с учётом квантизации (QAT) квантизированные модели сохраняют впечатляющее качество, несмотря на сниженную точность. QAT включает квантизацию в процесс обучения, уменьшая падение перплексии на 54% по сравнению со стандартной пост-тренировочной квантизацией.
Подход Google к QAT применяет примерно 5000 шагов обучения, используя вероятности из неквантизированной контрольной точки в качестве целей, что приводит к созданию моделей, устойчивых к эффектам квантизации.
источник: https://developers.googleblog.com/
Настройка оборудования и программного обеспечения: подготовка к запуску
Для эффективного запуска квантизированной Gemma 3 27B вам понадобится следующее:
Требования к оборудованию:
- GPU: Потребительский GPU с не менее 16 ГБ VRAM, например NVIDIA RTX 3090 (24 ГБ) для комфортной работы
- ОЗУ: Минимум 32 ГБ системной памяти
- Накопитель: SSD для более быстрой загрузки модели
Требования к программному обеспечению:
- Актуальные драйверы CUDA и toolkit
- Среда Python с необходимыми библиотеками (Transformers, PyTorch и т.д.)
- Специализированные библиотеки для квантизации в зависимости от выбранного подхода
Программные инструменты для развёртывания:
Google сотрудничает с несколькими популярными инструментами, чтобы упростить развёртывание квантизированных моделей Gemma 3:
- Ollama: Поддерживает модели Gemma 3 QAT нативно с помощью простых команд
- LM Studio: Предоставляет удобный интерфейс для запуска этих моделей
- MLX: Оптимизирован для эффективного вывода на Apple Silicon
- Gemma.cpp: Специализированная реализация на C++ для вывода на CPU
- llama.cpp: Поддерживает модели QAT в формате GGUF для лёгкой интеграции
При настройке среды учитывайте два ключевых момента:
- Указанные значения VRAM (14,1 ГБ для int4-квантизированной Gemma 3 27B) отражают только пространство, необходимое для весов модели. Вам потребуется дополнительная VRAM для KV-кэша, который хранит информацию о текущих диалогах.
- Разные форматы квантизации предлагают различные компромиссы между эффективностью использования памяти и производительностью. Формат Q4_0 широко поддерживается такими инструментами, как Ollama, llama.cpp и MLX.
Выберите Novita AI для запуска Gemma 3 27B
При выборе подходящего облачного провайдера для эффективного запуска квантизированной модели Novita AI выделяется как идеальный вариант. Novita AI предлагает надёжные облачные GPU-сервисы, используя передовые GPU, такие как NVIDIA A100 и RTX 3090, которые прекрасно подходят для запуска крупномасштабных моделей, таких как Gemma 3 27B. Novita AI упрощает процесс развёртывания благодаря нескольким ключевым преимуществам:
- Предварительно оптимизированные среды: Novita AI предоставляет готовые к использованию среды, специально настроенные для эффективного запуска квантизированных моделей.
- Гибкое выделение ресурсов: Масштабируйте ресурсы вверх или вниз в соответствии с вашими потребностями, не беспокоясь об ограничениях оборудования.
- Простая интеграция через API: Доступ к развёрнутым моделям через простые REST API, которые легко интегрируются с вашими приложениями.
- Управление затратами: Платите только за используемые ресурсы, что делает высокопроизводительный ИИ доступным без крупных первоначальных вложений.
Используя Novita AI, вы можете избежать значительных первоначальных затрат на оборудование и обеспечить бесперебойную работу вашей модели Gemma 3 на пиковой производительности. Войдите в Novita AI прямо сейчас и раскройте полный потенциал Gemma!

Попробуйте высокопроизводительные GPU от Novita AI
Подробные руководства смотрите в: Пошаговое руководство: Запуск Gemma 7B на GPU-инстансах Novita AI
Выводы
Квантизация прокладывает путь к более эффективному и экономичному развёртыванию больших языковых моделей. Как показано на примере Gemma 3 27B, снижение точности модели может привести к значительному улучшению скорости вывода, эффективности использования памяти и общей производительности системы — при этом сохраняя надёжность модели.
Понимая архитектуру и проблемы развёртывания Gemma 3 27B, настраивая правильную среду и используя такие платформы, как Novita AI, вы сможете максимально эффективно использовать эти передовые инструменты ИИ, не нуждаясь в суперкомпьютере. Надеемся, что это руководство предоставило вам полезные сведения и практические шаги для начала вашего пути квантизации с Gemma 3 27B.
Часто задаваемые вопросы
Что такое Gemma 3 27B и почему меня должна волновать квантизация?
Gemma 3 27B — это последняя большая языковая модель от Google, которая обычно требует высокопроизводительного оборудования, такого как NVIDIA H100. Квантизация снижает требования к памяти, позволяя запускать модель на потребительских GPU с сохранением производительности.
Что такое обучение с учётом квантизации (Quantization-Aware Training, QAT)?
QAT — это техника, которая включает квантизацию в процесс обучения, а не просто применяет её после. Это помогает моделям стать более устойчивыми к эффектам квантизации, уменьшая снижение производительности. Google применил QAT на примерно 5000 шагах обучения для моделей Gemma 3.
Могу ли я запустить Gemma 3 27B на своём персональном компьютере?
Да, с квантизацией! Версия в формате int4 может работать на потребительских GPU, таких как NVIDIA RTX 3090 с 24 ГБ VRAM, что делает её доступной для энтузиастов и разработчиков, имеющих достойное игровое/рабочее оборудование.
Novita AI — это облачная платформа ИИ, которая предоставляет разработчикам простой способ развёртывания моделей ИИ через наш простой API, а также доступные и надёжные облачные GPU для создания и масштабирования.
Рекомендуемое чтение
Как получить доступ к Gemma 3 27B локально, через API, на облачном GPU
Требования к оборудованию для запуска Gemma 3: полное руководство
Пошаговое руководство: Запуск Gemma 7B на GPU-инстансах Novita AI



