

Google의 Gemma 3 27B는 오픈 AI 모델의 획기적인 발전으로, 소비자 하드웨어에서 최첨단 성능을 제공합니다. 그러나 전체 정밀도 버전은 상당한 컴퓨팅 리소스를 요구합니다. 양자화, 특히 Google의 QAT(Quantization-Aware Training)를 통해 이 모델은 큰 성능 저하 없이 접근 가능해집니다. Gemma 3 27B를 효율적으로 최적화하는 방법을 알아보세요.
Gemma 3 27B 이해하기
Gemma 3 27B는 첨단 아키텍처와 광범위한 학습 데이터를 결합하여 고품질 언어 모델링 기능을 제공하는 최첨단 언어 모델입니다. 이 설계 덕분에 자연어 이해부터 텍스트 생성까지 다양한 작업을 뛰어난 수준으로 처리할 수 있습니다. 하지만 전체 정밀도로 모델을 실행하면 계산 집약적일 수 있습니다. Gemma 3 27B에 대한 몇 가지 핵심 사항은 다음과 같습니다.
- 아키텍처 및 규모: 이 모델은 270억 개의 파라미터로 구성되어 최신 AI 연구의 최전선에 있습니다.
- 리소스 요구 사항: 전체 정밀도로 실행하려면 상당한 메모리와 처리 능력이 필요하므로 소비자급 하드웨어에 배포하기 어렵습니다.
- 사용 사례: 하드웨어 요구 사항에도 불구하고 Gemma 3 27B는 대화형 에이전트, 콘텐츠 생성, 실시간 데이터 분석 등 다양한 애플리케이션에 적합합니다.
Gemma 3 27B를 양자화해야 하는 이유: 장점 이해하기
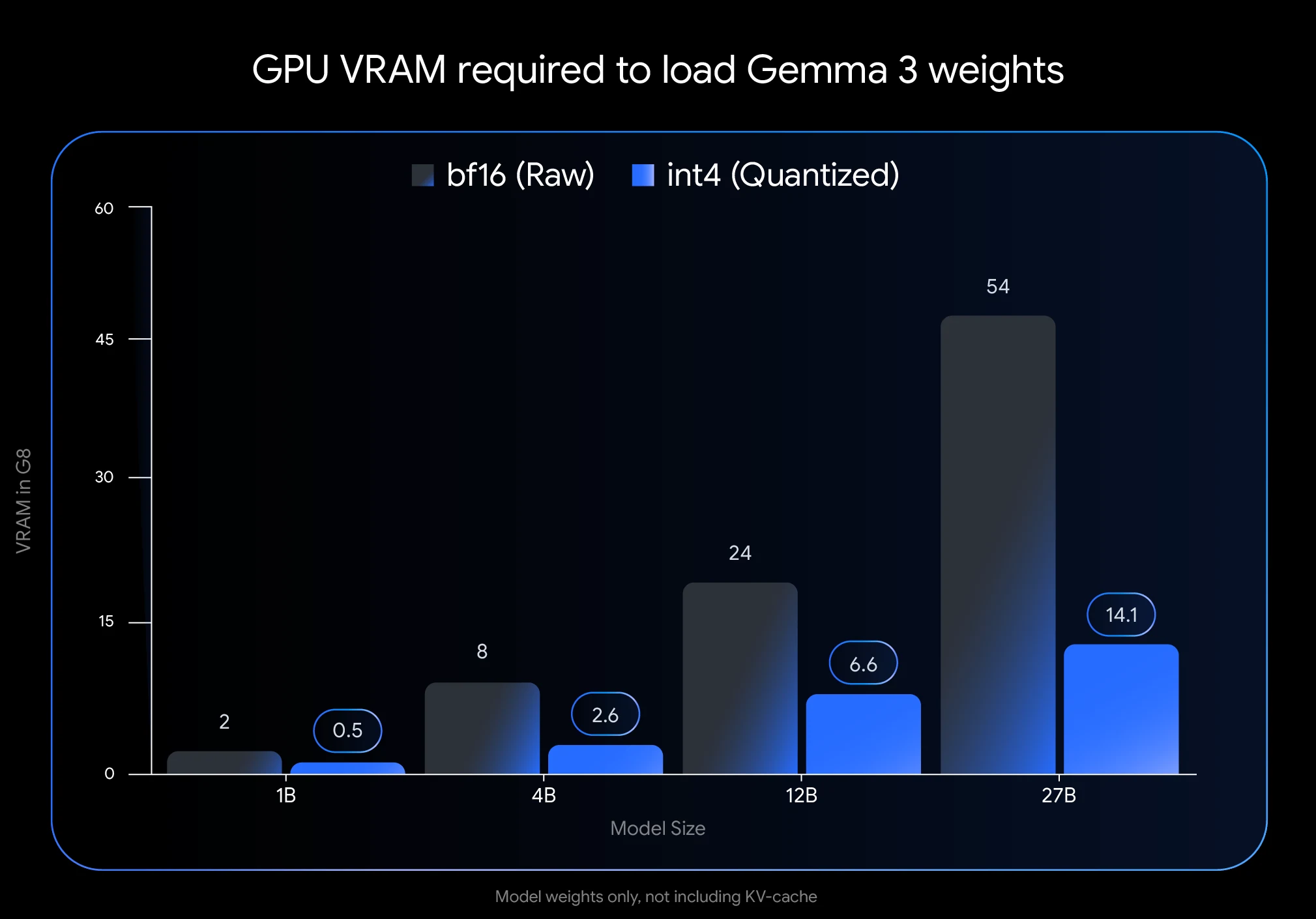
양자화는 모델 파라미터를 표현하는 데 사용되는 숫자의 정밀도를 낮춥니다. 숫자당 16비트(BFloat16)를 사용하는 대신, 양자화를 통해 8비트(int8) 또는 4비트(int4)와 같은 더 적은 비트를 사용할 수 있어 메모리 요구 사항을 획기적으로 줄일 수 있습니다.
Gemma 3 27B를 양자화할 때의 장점은 다음과 같습니다.
- 막대한 VRAM 절약: Gemma 3 27B를 int4로 양자화하면 메모리 사용량이 54GB(BF16)에서 14.1GB로 74% 감소합니다. 이를 통해 NVIDIA RTX 3090(VRAM 24GB)과 같은 소비자급 GPU에서 실행할 수 있습니다.
- 더 넓은 하드웨어 호환성: 양자화를 사용하면 값비싼 데이터센터 하드웨어 대신 데스크톱 GPU에서 Gemma 3 27B를 실행할 수 있어 최첨단 AI에 대한 접근성을 높일 수 있습니다.
- 비용 효율성: 소비자 하드웨어를 사용하면 Gemma 3 모델을 배포하고 실험하는 비용이 크게 절감됩니다.
- 성능 유지: Google의 QAT(Quantization-Aware Training) 접근 방식 덕분에 정밀도가 낮아져도 양자화된 모델은 인상적인 품질을 유지합니다. QAT는 학습 과정에 양자화를 통합하여 기존의 사후 양자화 방식에 비해 혼란도(perplexity) 하락을 54% 줄입니다.
Google의 QAT 접근 방식은 양자화되지 않은 체크포인트의 확률을 타겟으로 약 5,000개의 학습 단계를 적용하여 양자화 효과에 강건한 모델을 생성합니다.
출처: https://developers.googleblog.com/
하드웨어 및 소프트웨어 설정: 실행 준비
양자화된 Gemma 3 27B를 효과적으로 실행하려면 다음이 필요합니다.
하드웨어 요구 사항:
- GPU: 원활한 작동을 위해 최소 16GB VRAM의 소비자급 GPU(NVIDIA RTX 3090 24GB 등)
- RAM: 최소 32GB 시스템 메모리
- 스토리지: 더 빠른 모델 로딩을 위한 SSD 스토리지
소프트웨어 요구 사항:
- 최신 CUDA 드라이버 및 툴킷
- 필수 라이브러리(Transformers, PyTorch 등)가 설치된 Python 환경
- 접근 방식에 따른 양자화 관련 라이브러리
배포를 위한 소프트웨어 도구:
Google은 양자화된 Gemma 3 모델을 간편하게 배포할 수 있도록 여러 인기 도구와 제휴했습니다.
- Ollama: 간단한 명령어로 Gemma 3 QAT 모델을 기본 지원
- LM Studio: 사용자 친화적인 인터페이스를 제공
- MLX: Apple Silicon에서 효율적인 추론에 최적화
- Gemma.cpp: CPU 추론을 위한 전용 C++ 구현
- llama.cpp: 손쉬운 통합을 위한 GGUF 형식의 QAT 모델 지원
환경을 설정할 때 두 가지 주요 사항을 염두에 두세요.
- 언급된 VRAM 수치(int4 양자화 Gemma 3 27B의 14.1GB)는 모델 가중치에 필요한 공간만 나타냅니다. 대화 정보를 저장하는 KV 캐시를 위해 추가 VRAM이 필요합니다.
- 양자화 형식에 따라 메모리 효율성과 성능 간의 트레이드오프가 다릅니다. Q4_0 형식은 Ollama, llama.cpp, MLX 등 여러 도구에서 널리 지원됩니다.
Gemma 3 27B 실행을 위해 Novita AI 선택하기
양자화된 모델을 효율적으로 실행할 클라우드 제공업체를 선택할 때 Novita AI 는 이상적인 선택입니다. Novita AI는 NVIDIA A100 및 RTX 3090 과 같은 최첨단 GPU를 활용하는 강력한 클라우드 GPU 서비스를 제공하며, 이는 Gemma 3 27B와 같은 대규모 모델을 실행하는 데 완벽합니다. Novita AI는 다음과 같은 주요 장점으로 배포 프로세스를 간소화합니다.
- 사전 최적화된 환경: Novita AI는 양자화된 모델을 효율적으로 실행하도록 특별히 구성된 즉시 사용 가능한 환경을 제공합니다.
- 유연한 리소스 할당: 하드웨어 제한에 대한 걱정 없이 필요에 따라 리소스를 확장 또는 축소할 수 있습니다.
- 간편한 API 통합: 애플리케이션에 쉽게 통합할 수 있는 간단한 REST API를 통해 배포된 모델에 액세스할 수 있습니다.
- 비용 관리: 사용한 리소스에 대해서만 비용을 지불하므로 막대한 선투자 없이 고성능 AI에 접근할 수 있습니다.
Novita AI를 활용하면 상당한 초기 하드웨어 비용을 피하고 Gemma 3 모델이 최고 성능으로 원활하게 작동하도록 보장할 수 있습니다. 지금 Novita AI에 로그인하여 Gemma의 잠재력을 최대한 활용하세요!

[Novita AI의 고성능 GPU 사용해보기](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks)
자세한 튜토리얼은 단계별 가이드를 참조하세요: Novita AI GPU 인스턴스에서 Gemma 7B 실행하기
결론
양자화는 대규모 언어 모델을 더 효율적이고 비용 효과적으로 배포할 수 있는 길을 열어가고 있습니다. Gemma 3 27B에서 보여준 것처럼 모델 정밀도를 낮추면 추론 속도, 메모리 효율성 및 전반적인 시스템 성능이 크게 향상되면서도 모델의 견고성을 유지할 수 있습니다.
Gemma 3 27B의 아키텍처와 배포 과제를 이해하고, 적절한 환경을 설정하며, Novita AI와 같은 플랫폼을 활용하면 슈퍼컴퓨터 없이도 이러한 고급 AI 도구의 잠재력을 최대한 발휘할 수 있습니다. 이 가이드가 Gemma 3 27B와 함께 양자화 여정을 시작하는 데 필요한 통찰력과 실행 가능한 단계를 제공했기를 바랍니다.
자주 묻는 질문
Gemma 3 27B란 무엇이며, 양자화를 왜 고려해야 하나요?
Gemma 3 27B는 Google의 최신 대규모 언어 모델로, 일반적으로 NVIDIA H100 GPU와 같은 고급 하드웨어가 필요합니다. 양자화는 메모리 요구 사항을 줄여 성능을 유지하면서 소비자급 GPU에서도 실행할 수 있게 합니다.
QAT(Quantization-Aware Training)란 무엇인가요?
QAT는 양자화를 학습 과정에 통합하는 기술로, 이후에 적용하는 것보다 모델이 양자화 효과에 더 강건해지도록 하여 성능 저하를 줄입니다. Google은 Gemma 3 모델에 약 5,000개의 학습 단계 동안 QAT를 적용했습니다.
내 개인용 컴퓨터에서 Gemma 3 27B를 실행할 수 있나요?
네, 양자화를 사용하면 가능합니다! int4 양자화 버전은 24GB VRAM의 NVIDIA RTX 3090과 같은 소비자 GPU에서 실행할 수 있어 적절한 게이밍/워크스테이션 하드웨어를 가진 사용자와 개발자도 접근할 수 있습니다.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks)는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있도록 지원하는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공합니다.
추천 자료
Gemma 3 27B 로컬, API, 클라우드 GPU에서 사용하는 방법
[Gemma 3 실행을 위한 하드웨어 요구 사항: 완벽 가이드](http://Hardware Requirements for Running Gemma 3: A Complete Guide)
[단계별 가이드: Novita AI GPU 인스턴스에서 Gemma 7B 실행하기](http://Step-by-Step Guide: Running Gemma 7B on Novita AI GPU Instances)



