

El modelo Gemma 3 27B de Google es un gran avance en modelos de IA abiertos, que ofrece un rendimiento de última generación en hardware de consumo. Sin embargo, su versión de precisión completa exige recursos computacionales significativos. Mediante la cuantización—especialmente el entrenamiento consciente de la cuantización (QAT) de Google—este modelo se vuelve accesible sin grandes sacrificios de rendimiento. A continuación, te mostramos cómo optimizar Gemma 3 27B para lograr eficiencia.
Entendiendo Gemma 3 27B
Gemma 3 27B es un modelo de lenguaje de última generación que combina una arquitectura avanzada con datos de entrenamiento extensos para ofrecer capacidades de modelado de lenguaje de alta calidad. Su diseño le permite manejar una variedad de tareas, desde la comprensión del lenguaje natural hasta la generación de texto, con una impresionante competencia. Sin embargo, ejecutar el modelo con precisión completa puede ser computacionalmente intensivo. A continuación, algunos puntos clave sobre Gemma 3 27B:
- Arquitectura y escala: El modelo consta de 27 mil millones de parámetros, lo que lo sitúa a la vanguardia de la investigación moderna en IA.
- Requisitos de recursos: Ejecutar el modelo con precisión completa requiere una cantidad significativa de memoria y potencia de procesamiento, lo que dificulta su implementación en hardware de consumo.
- Casos de uso: A pesar de las demandas de hardware, Gemma 3 27B es adecuado para diversas aplicaciones, como agentes conversacionales, generación de contenido y análisis de datos en tiempo real.
¿Por qué cuantizar Gemma 3 27B? Entendiendo los beneficios
La cuantización reduce la precisión de los números utilizados para representar los parámetros del modelo. En lugar de usar 16 bits por número (BFloat16), la cuantización permite usar menos bits, como 8 (int8) o incluso 4 (int4), lo que reduce drásticamente los requisitos de memoria.
Los beneficios de cuantizar Gemma 3 27B incluyen:
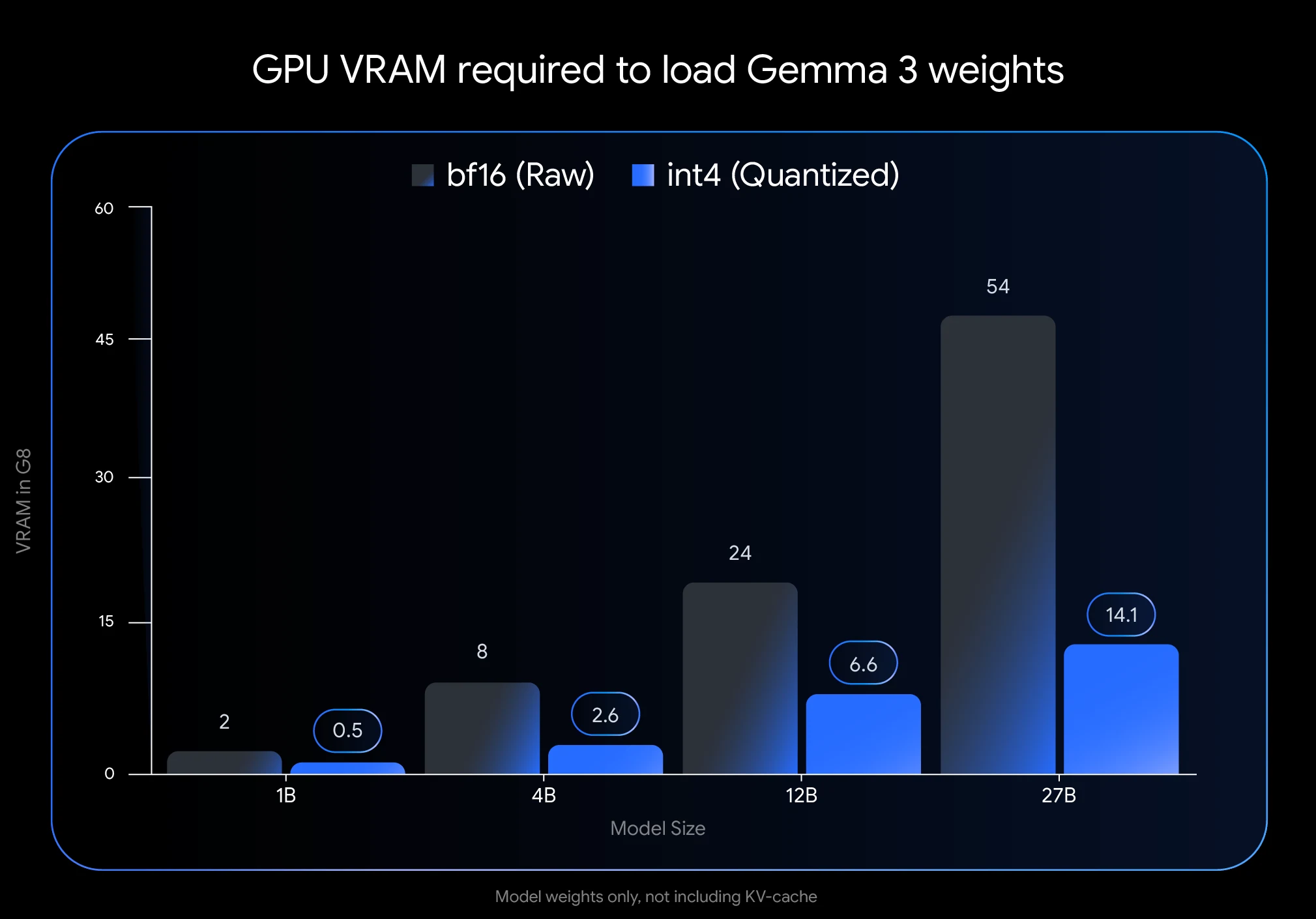
- Ahorro masivo de VRAM: Cuantizar Gemma 3 27B a int4 reduce su huella de memoria de 54 GB (BF16) a solo 14.1 GB, una reducción del 74 %. Esto permite ejecutarlo en GPUs de consumo como la NVIDIA RTX 3090 con 24 GB de VRAM.
- Compatibilidad de hardware más amplia: Con la cuantización, puedes ejecutar Gemma 3 27B en GPUs de escritorio en lugar de requerir costoso hardware de centro de datos, democratizando el acceso a la IA de última generación.
- Eficiencia de costos: Usar hardware de consumo reduce significativamente el costo de implementar y experimentar con modelos Gemma 3.
- Rendimiento mantenido: Gracias al enfoque de entrenamiento consciente de la cuantización (QAT) de Google, los modelos cuantizados mantienen una calidad impresionante a pesar de la precisión reducida. QAT incorpora la cuantización durante el proceso de entrenamiento, reduciendo las caídas de perplejidad en un 54 % en comparación con la cuantización estándar posterior al entrenamiento.
El enfoque QAT de Google aplica aproximadamente 5,000 pasos de entrenamiento utilizando probabilidades del checkpoint no cuantizado como objetivos, lo que resulta en modelos robustos a los efectos de la cuantización.
fuente: https://developers.googleblog.com/
Configuración de hardware y software: preparándose para ejecutar
Para ejecutar eficazmente Gemma 3 27B cuantizado, necesitarás lo siguiente:
Requisitos de hardware:
- GPU: Una GPU de consumo con al menos 16 GB de VRAM, como la NVIDIA RTX 3090 (24 GB) para un funcionamiento cómodo
- RAM: Mínimo 32 GB de memoria del sistema
- Almacenamiento: Almacenamiento SSD para una carga más rápida del modelo
Requisitos de software:
- Controladores y toolkit CUDA recientes
- Entorno Python con las bibliotecas necesarias (Transformers, PyTorch, etc.)
- Bibliotecas específicas de cuantización según tu enfoque
Herramientas de software para la implementación:
Google se ha asociado con varias herramientas populares para facilitar la implementación de modelos Gemma 3 cuantizados:
- Ollama: Compatible con modelos Gemma 3 QAT de forma nativa con comandos simples
- LM Studio: Proporciona una interfaz fácil de usar para ejecutar estos modelos
- MLX: Optimizado para inferencia eficiente en Apple Silicon
- Gemma.cpp: Implementación dedicada en C++ para inferencia en CPU
- llama.cpp: Compatible con modelos QAT en formato GGUF para una fácil integración
Al configurar tu entorno, ten en cuenta dos consideraciones clave:
- Las cifras de VRAM mencionadas (14.1 GB para Gemma 3 27B cuantizado a int4) solo representan el espacio necesario para los pesos del modelo. Necesitarás VRAM adicional para la caché KV, que almacena información sobre conversaciones en curso.
- Diferentes formatos de cuantización ofrecen diferentes compensaciones entre eficiencia de memoria y rendimiento. El formato Q4_0 es ampliamente compatible con herramientas como Ollama, llama.cpp y MLX.
Elige Novita AI para ejecutar Gemma 3 27B
Al seleccionar el proveedor de nube adecuado para ejecutar tu modelo cuantizado de manera eficiente, Novita AI se destaca como una opción ideal. Novita AI ofrece servicios robustos de GPU en la nube, utilizando GPUs de vanguardia como la NVIDIA A100 y RTX 3090, perfectas para ejecutar modelos a gran escala como Gemma 3 27B. Novita AI simplifica el proceso de implementación con varias ventajas clave:
- Entornos preoptimizados: Novita AI proporciona entornos listos para usar, específicamente configurados para ejecutar modelos cuantizados de manera eficiente.
- Asignación flexible de recursos: Escala los recursos hacia arriba o hacia abajo según tus necesidades sin preocuparte por limitaciones de hardware.
- Integración API simple: Accede a tus modelos implementados a través de API REST sencillas que se integran fácilmente con tus aplicaciones.
- Gestión de costos: Paga solo por los recursos que utilizas, haciendo que la IA de alto rendimiento sea accesible sin grandes inversiones iniciales.
Al aprovechar Novita AI, puedes evitar costos iniciales sustanciales de hardware, asegurando que tu modelo Gemma 3 funcione sin problemas y con el máximo rendimiento. ¡Inicia sesión en Novita AI ahora y desbloquea todo el potencial de Gemma!

Prueba las GPUs de alto rendimiento de Novita AI
Para tutoriales detallados, consulta: Guía paso a paso: Ejecutando Gemma 7B en instancias GPU de Novita AI
Conclusiones
La cuantización está allanando el camino hacia una implementación más eficiente y rentable de grandes modelos de lenguaje. Como se demostró con Gemma 3 27B, reducir la precisión del modelo puede generar mejoras significativas en la velocidad de inferencia, la eficiencia de memoria y el rendimiento general del sistema, manteniendo al mismo tiempo la robustez del modelo.
Al comprender la arquitectura y los desafíos de implementación de Gemma 3 27B, configurar un entorno adecuado y utilizar plataformas como Novita AI, puedes aprovechar al máximo estas herramientas avanzadas de IA sin necesidad de una supercomputadora. Esperamos que esta guía te haya proporcionado la información y los pasos prácticos necesarios para comenzar tu viaje de cuantización con Gemma 3 27B.
Preguntas frecuentes
¿Qué es Gemma 3 27B y por qué debería preocuparme por la cuantización?
Gemma 3 27B es el último modelo de lenguaje grande de Google que normalmente requiere hardware de alta gama como GPUs NVIDIA H100. La cuantización reduce sus requisitos de memoria, permitiendo que se ejecute en GPUs de consumo mientras mantiene el rendimiento.
¿Qué es el entrenamiento consciente de la cuantización (QAT)?
QAT es una técnica que incorpora la cuantización durante el proceso de entrenamiento, en lugar de aplicarla solo después. Esto ayuda a que los modelos sean más robustos a los efectos de la cuantización, reduciendo la degradación del rendimiento. Google aplicó QAT en aproximadamente 5,000 pasos de entrenamiento para los modelos Gemma 3.
¿Puedo ejecutar Gemma 3 27B en mi computadora personal?
¡Sí, con cuantización! La versión cuantizada a int4 puede ejecutarse en GPUs de consumo como la NVIDIA RTX 3090 con 24 GB de VRAM, haciéndola accesible para entusiastas y desarrolladores con hardware de gaming/estación de trabajo decente.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Lectura recomendada
Cómo acceder a Gemma 3 27B localmente, mediante API, en GPU en la nube
Requisitos de hardware para ejecutar Gemma 3: guía completa
Guía paso a paso: ejecutando Gemma 7B en instancias GPU de Novita AI



