

O Gemma 3 27B do Google é um avanço nos modelos de IA abertos, oferecendo desempenho de ponta em hardware de consumo. No entanto, sua versão de precisão total exige recursos computacionais significativos. Por meio da quantização — especialmente o treinamento ciente de quantização (QAT) do Google — este modelo se torna acessível sem grandes sacrifícios de desempenho. Veja como otimizar o Gemma 3 27B para eficiência.
Compreendendo o Gemma 3 27B
O Gemma 3 27B é um modelo de linguagem de ponta que combina arquitetura avançada com dados de treinamento extensos para fornecer capacidades de modelagem de linguagem de alta qualidade. Seu design permite lidar com uma variedade de tarefas — desde compreensão de linguagem natural até geração de texto — com proficiência impressionante. No entanto, executar o modelo com precisão total pode ser computacionalmente intensivo. Aqui estão alguns pontos-chave sobre o Gemma 3 27B:
- Arquitetura e Escala: O modelo consiste em 27 bilhões de parâmetros, posicionando-o na vanguarda da pesquisa moderna de IA.
- Requisitos de Recursos: Executar o modelo com precisão total exige memória e poder de processamento significativos, tornando desafiador implantá-lo em hardware de nível consumidor.
- Casos de Uso: Apesar das demandas de hardware, o Gemma 3 27B é adequado para diversas aplicações, incluindo agentes conversacionais, geração de conteúdo e análise de dados em tempo real.
Por que Quantizar o Gemma 3 27B? Compreendendo os Benefícios
A quantização reduz a precisão dos números usados para representar os parâmetros do modelo. Em vez de usar 16 bits por número (BFloat16), a quantização permite usar menos bits, como 8 (int8) ou até 4 (int4), reduzindo drasticamente os requisitos de memória.
Os benefícios de quantizar o Gemma 3 27B incluem:
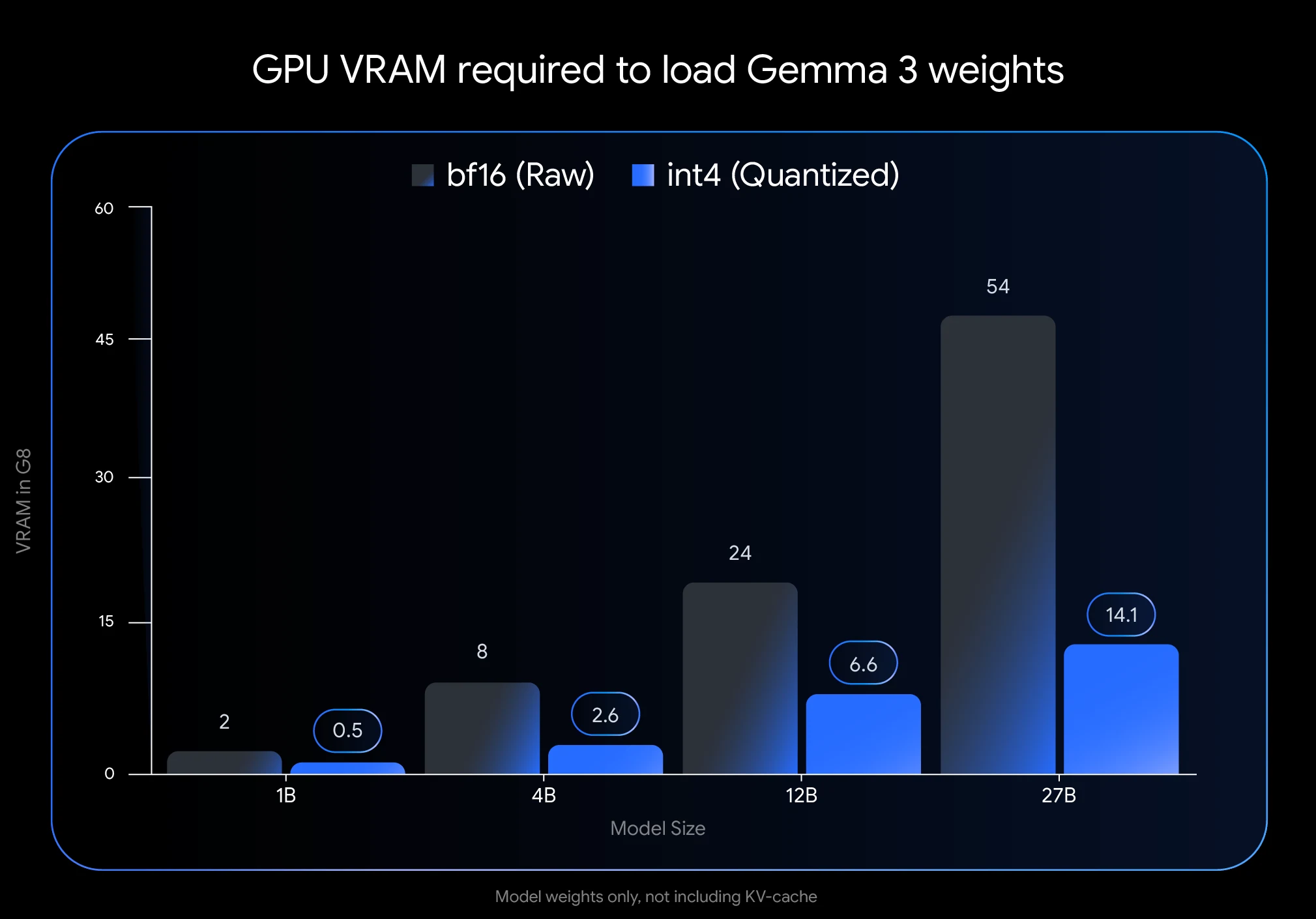
- Economia Massiva de VRAM: Quantizar o Gemma 3 27B para int4 reduz seu consumo de memória de 54GB (BF16) para apenas 14,1GB, uma redução de 74%. Isso torna possível executá-lo em GPUs de nível consumidor, como a NVIDIA RTX 3090 com 24GB de VRAM.
- Maior Compatibilidade de Hardware: Com a quantização, você pode executar o Gemma 3 27B em GPUs de desktop, em vez de exigir hardware caro de datacenter, democratizando o acesso à IA de ponta.
- Eficiência de Custos: Usar hardware de consumo reduz significativamente o custo de implantação e experimentação com modelos Gemma 3.
- Desempenho Mantido: Graças à abordagem de treinamento ciente de quantização (QAT) do Google, os modelos quantizados mantêm qualidade impressionante apesar da precisão reduzida. O QAT incorpora a quantização durante o processo de treinamento, reduzindo as quedas de perplexidade em 54% em comparação com a quantização pós-treinamento padrão.
A abordagem do Google para QAT aplica aproximadamente 5.000 etapas de treinamento usando probabilidades do checkpoint não quantizado como alvos, resultando em modelos robustos aos efeitos da quantização.
fonte: https://developers.googleblog.com/
Configuração de Hardware e Software: Preparando-se para Executar
Para executar efetivamente o Gemma 3 27B quantizado, você precisará do seguinte:
Requisitos de Hardware:
- GPU: Uma GPU de nível consumidor com pelo menos 16GB de VRAM, como a NVIDIA RTX 3090 (24GB) para operação confortável
- RAM: Mínimo de 32GB de memória do sistema
- Armazenamento: Armazenamento SSD para carregamento mais rápido do modelo
Requisitos de Software:
- Drivers e toolkit CUDA recentes
- Ambiente Python com as bibliotecas necessárias (Transformers, PyTorch, etc.)
- Bibliotecas específicas de quantização, dependendo da sua abordagem
Ferramentas de Software para Implantação:
O Google fez parceria com várias ferramentas populares para facilitar a implantação de modelos Gemma 3 quantizados:
- Ollama: Suporta modelos Gemma 3 QAT nativamente com comandos simples
- LM Studio: Fornece uma interface amigável para executar esses modelos
- MLX: Otimizado para inferência eficiente em Apple Silicon
- Gemma.cpp: Implementação dedicada em C++ para inferência em CPU
- llama.cpp: Suporta modelos QAT no formato GGUF para integração fácil
Ao configurar seu ambiente, esteja atento a duas considerações importantes:
- Os valores de VRAM mencionados (14,1GB para o Gemma 3 27B quantizado em int4) representam apenas o espaço necessário para os pesos do modelo. Você precisará de VRAM adicional para o cache KV, que armazena informações sobre conversas em andamento.
- Diferentes formatos de quantização oferecem diferentes compensações entre eficiência de memória e desempenho. O formato Q4_0 é amplamente suportado em ferramentas como Ollama, llama.cpp e MLX.
Escolha a Novita AI para executar o Gemma 3 27B
Ao selecionar o provedor de nuvem certo para executar seu modelo quantizado de forma eficiente, a Novita AI se destaca como uma escolha ideal. A Novita AI oferece serviços robustos de GPU em nuvem, utilizando GPUs de ponta como a NVIDIA A100 e RTX 3090, perfeitas para executar modelos de grande escala como o Gemma 3 27B. A Novita AI simplifica o processo de implantação com várias vantagens importantes:
- Ambientes Pré-otimizados: A Novita AI fornece ambientes prontos para uso, especificamente configurados para executar modelos quantizados de forma eficiente.
- Alocação Flexível de Recursos: Escale os recursos para cima ou para baixo conforme sua necessidade, sem se preocupar com limitações de hardware.
- Integração Simples via API: Acesse seus modelos implantados por meio de REST APIs diretas que se integram facilmente às suas aplicações.
- Gerenciamento de Custos: Pague apenas pelos recursos que usar, tornando a IA de alto desempenho acessível sem grandes investimentos iniciais.
Ao aproveitar a Novita AI, você evita custos substanciais de hardware inicial, garantindo que seu modelo Gemma 3 opere sem problemas com desempenho máximo. Faça login na Novita AI agora e desbloqueie todo o potencial do Gemma!

[Experimente as GPUs de Alto Desempenho da Novita AI](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks)
Para tutoriais detalhados, consulte: Guia Passo a Passo: Executando o Gemma 7B em Instâncias GPU da Novita AI
Conclusões
A quantização está abrindo caminho para uma implantação mais eficiente e econômica de grandes modelos de linguagem. Como demonstrado com o Gemma 3 27B, reduzir a precisão do modelo pode levar a melhorias significativas na velocidade de inferência, eficiência de memória e desempenho geral do sistema — tudo isso mantendo a robustez do modelo.
Ao compreender a arquitetura e os desafios de implantação do Gemma 3 27B, configurar um ambiente adequado e utilizar plataformas como a Novita AI, você pode aproveitar ao máximo essas ferramentas avançadas de IA sem precisar de um supercomputador. Esperamos que este guia tenha fornecido insights e etapas acionáveis para iniciar sua jornada de quantização com o Gemma 3 27B.
Perguntas Frequentes
O que é o Gemma 3 27B e por que devo me importar com a quantização?
O Gemma 3 27B é o mais recente modelo de linguagem grande do Google que normalmente exige hardware de alto nível, como GPUs NVIDIA H100. A quantização reduz seus requisitos de memória, permitindo que ele seja executado em GPUs de nível consumidor, mantendo o desempenho.
O que é Treinamento Ciente de Quantização (QAT)?
QAT é uma técnica que incorpora a quantização durante o processo de treinamento, em vez de aplicá-la apenas posteriormente. Isso ajuda os modelos a se tornarem mais robustos aos efeitos da quantização, reduzindo a degradação do desempenho. O Google aplicou QAT em aproximadamente 5.000 etapas de treinamento para os modelos Gemma 3.
Posso executar o Gemma 3 27B no meu computador pessoal?
Sim, com quantização! A versão quantizada em int4 pode ser executada em GPUs de consumo como a NVIDIA RTX 3090 com 24GB de VRAM, tornando-a acessível para entusiastas e desenvolvedores com hardware de jogos/workstation decente.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks) é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer GPUs em nuvem acessíveis e confiáveis para construir e escalar.
Leitura Recomendada
Como Acessar o Gemma 3 27B Localmente, via API, em GPU na Nuvem
[Requisitos de Hardware para Executar o Gemma 3: Um Guia Completo](http://Hardware Requirements for Running Gemma 3: A Complete Guide)
[Guia Passo a Passo: Executando o Gemma 7B em Instâncias GPU da Novita AI](http://Step-by-Step Guide: Running Gemma 7B on Novita AI GPU Instances)



