

Google 的 Gemma 3 27B 是開放 AI 模型的一項突破,能在消費級硬體上提供最先進的效能。然而,其完整精確度版本需要大量的運算資源。透過量化,特別是 Google 的量化感知訓練 (QAT),這個模型無需犧牲太多效能就能變得易於存取。以下是如何最佳化 Gemma 3 27B 以提升效率。
認識 Gemma 3 27B
Gemma 3 27B 是一款最先進的語言模型,結合了先進的架構與大量的訓練資料,提供高品質的語言建模能力。其設計使其能夠處理各種任務,從自然語言理解到文字生成,皆具備令人印象深刻的熟練度。然而,以完整精確度運行模型可能會耗費大量運算資源。以下是關於 Gemma 3 27B 的幾個要點:
- 架構與規模: 該模型擁有 270 億個參數,位居現代 AI 研究的前沿。
- 資源需求: 以完整精確度運行模型需要大量記憶體與處理能力,因此在消費級硬體上部署具有挑戰性。
- 使用案例: 儘管硬體需求高,Gemma 3 27B 仍非常適用於各種應用,包括對話代理人、內容生成,以及即時數據分析。
為什麼要量化 Gemma 3 27B?了解其優勢
量化會降低用來表示模型參數的數字精確度。與其每個數字使用 16 位元 (BFloat16),量化讓我們可以使用更少的位元,例如 8 位元 (int8) 甚至 4 位元 (int4),從而大幅減少記憶體需求。
量化 Gemma 3 27B 的優勢包括:
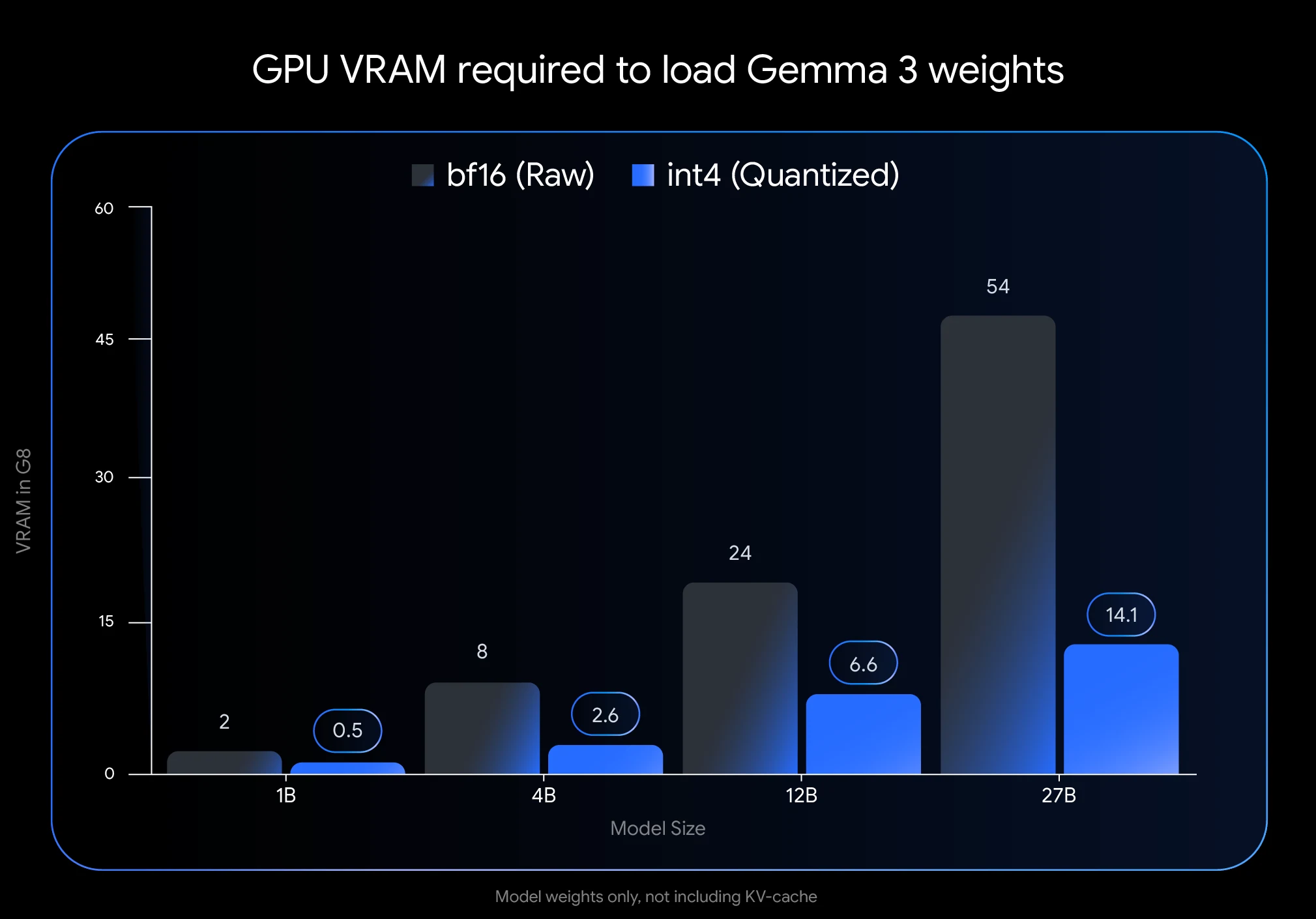
- 大幅節省 VRAM: 將 Gemma 3 27B 量化為 int4,可將其記憶體足跡從 54GB (BF16) 降至僅 14.1GB,減少了 74%。這使得在消費級 GPU 上運行成為可能,例如擁有 24GB VRAM 的 NVIDIA RTX 3090。
- 更廣泛的硬體相容性: 透過量化,您可以在桌上型 GPU 上運行 Gemma 3 27B,而不需要昂貴的資料中心硬體,讓最先進的 AI 更加普及。
- 成本效益: 使用消費級硬體能顯著降低部署與測試 Gemma 3 模型的成本。
- 維持效能: 感謝 Google 的量化感知訓練 (QAT) 方法,量化後的模型儘管精確度降低,仍能保持令人印象深刻的品質。QAT 在訓練過程中就加入了量化,與標準的訓練後量化相比,困惑度下降幅度減少了 54%。
Google 的 QAT 方法約進行 5,000 個訓練步驟,並以非量化檢查點輸出的機率作為目標,從而產生了對量化效果具有穩健性的模型。
來源:https://developers.googleblog.com/
硬體與軟體設定:準備運行
要有效運行量化後的 Gemma 3 27B,您需要以下配備:
硬體需求:
- GPU:消費級 GPU,至少 16GB VRAM,例如 NVIDIA RTX 3090 (24GB) 以獲得流暢體驗。
- RAM:系統記憶體至少 32GB。
- 儲存:SSD 儲存以加快模型載入速度。
軟體需求:
- 最新的 CUDA 驅動程式與工具包。
- 具備必要函式庫的 Python 環境 (Transformers、PyTorch 等)。
- 根據您選擇的方法,安裝量化專用的函式庫。
部署軟體工具:
Google 已與多種熱門工具合作,讓部署量化後的 Gemma 3 模型更加簡單:
- Ollama: 原生支援 Gemma 3 QAT 模型,只需簡單指令即可運行。
- LM Studio: 提供友善的使用者介面來運行這些模型。
- MLX: 針對 Apple Silicon 上的高效推理進行最佳化。
- Gemma.cpp: 專為 CPU 推理設計的 C++ 實作。
- llama.cpp: 支援 GGUF 格式的 QAT 模型,便於整合。
設定環境時,請注意兩個關鍵考量:
- 上面提到的 VRAM 數值 (int4 量化 Gemma 3 27B 的 14.1GB) 僅代表模型權重所需的空間。您還需要額外的 VRAM 給 KV 快取,它會儲存對話的上下文資訊。
- 不同的量化格式在記憶體效率與效能之間提供了不同的取捨。Q4_0 格式廣泛受到如 Ollama、llama.cpp 與 MLX 等工具的支援。
選擇 Novita AI 來運行 Gemma 3 27B
在選擇合適的雲端服務商來高效運行您的量化模型時,Novita AI 是理想的選擇。Novita AI 提供強大的雲端 GPU 服務,採用如 NVIDIA A100 和 RTX 3090 等尖端 GPU,非常適合運行 Gemma 3 27B 這類大型模型。Novita AI 簡化了部署流程,具備以下關鍵優勢:
- 預先最佳化的環境: Novita AI 提供立即可用的環境,專門針對高效運行量化模型而設定。
- 彈性資源分配: 根據您的需求動態調整資源,無需擔心硬體限制。
- 簡單的 API 整合: 透過簡單的 REST API 存取您已部署的模型,輕鬆整合到您的應用程式中。
- 成本管理: 僅需為您使用的資源付費,讓高效能 AI 變得可行,而無需大量前期投資。
透過 Novita AI,您可以避免龐大的前期硬體成本,確保您的 Gemma 3 模型以最佳效能平穩運行。立即登入 Novita AI,釋放 Gemma 的全部潛力!

[試用 Novita AI 的高效能 GPU](https://novita.ai/gpus/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=Running Gemma 3 27B Efficiently: Quantization Tips and Tricks)
如需詳細教學,請參閱:逐步指南:在 Novita AI GPU 實例上運行 Gemma 7B
結論
量化為大型語言模型的部署開闢了一條更高效、更具成本效益的道路。正如 Gemma 3 27B 所展示的,降低模型的精確度能顯著提升推理速度、記憶體效率與整體系統效能,同時維持模型的穩健性。
透過了解 Gemma 3 27B 的架構與部署挑戰,設定合適的環境,並利用如 Novita AI 等平台,您無需超級電腦也能充分發揮這些先進 AI 工具的威力。希望本指南能為您提供所需的見解與可行步驟,讓您開始 Gemma 3 27B 的量化之旅。
常見問題
什麼是 Gemma 3 27B?為什麼我該關心量化?
Gemma 3 27B 是 Google 最新的大型語言模型,通常需要如 NVIDIA H100 GPU 等高端硬體。量化能降低其記憶體需求,讓它能在消費級 GPU 上運行,同時維持效能。
什麼是量化感知訓練 (QAT)?
QAT 是一種在訓練過程中就納入量化的技術,而非事後才應用。這有助於模型對量化效果更具穩健性,減少效能衰減。Google 在 Gemma 3 模型上應用了約 5,000 個訓練步驟的 QAT。
我可以在個人電腦上運行 Gemma 3 27B 嗎?
可以,透過量化!int4 量化版本可以在如 NVIDIA RTX 3090 (24GB VRAM) 等消費級 GPU 上運行,讓擁有中高階遊戲/workstation 硬體的愛好者與開發者能夠使用。
Novita AI 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的簡便方式,同時也提供價格合理且可靠的 GPU 雲端服務,用於建置與擴展。
推薦閱讀



