

По мере того как большие языковые модели продолжают масштабироваться за пределы 70 миллиардов параметров, спрос на GPU, способные справляться с задачами ИИ, ограниченными памятью, становится как никогда высоким. Представляем NVIDIA H200 — ускоритель нового поколения, созданный для расширения границ генеративного ИИ, научных вычислений и визуализации в реальном времени.
Оснащённый памятью HBM3e, производительностью тензорных ядер FP8 и поддержкой нескольких моделей MIG, H200 обещает сократить количество GPU, необходимых для массивных рабочих нагрузок, одновременно ускоряя обучение и инференс как никогда раньше. Но возникает вопрос: подходит ли этот монстр именно вам?
Эта статья разбирает, в чём H200 лучше всего, какие модели он может поддерживать, когда его использование имеет смысл, а когда выгоднее сэкономить с более разумными альтернативами, такими как RTX 4090 или облачные платформы вроде Novita AI.
Что такое H200?
NVIDIA представляет H200 как значительный шаг вперёд по сравнению с H100, созданный специально для самых требовательных задач генеративного ИИ и высокопроизводительных вычислений (HPC), особенно тех, которые упираются в память. В основе этого обновления лежит дебют памяти HBM3e, обеспечивающей до 1,8× большую ёмкость и примерно в 1,4× более высокую пропускную способность по сравнению с предшественником. Это означает, что для эффективного запуска массивных моделей требуется меньше GPU. H200 ориентирован на гипермасштабируемые облачные платформы, передовые исследовательские лаборатории и предприятия, работающие с крупными LLM или требующими высокой точности симуляциями.

| Параметр | H200 SXM | H200 NVL |
|---|---|---|
| Память | 141 ГБ @ 4,8 ТБ/с | 141 ГБ @ 4,8 ТБ/с |
| Ядра CUDA | 16 896 | 16 896 |
| Тензорные ядра (4-е поколение) | FP8 3,96 PFLOPS; FP16 1,98 PFLOPS; TF32 0,99 PFLOPS | FP8 3,34 PFLOPS; FP16 1,67 PFLOPS; TF32 0,84 PFLOPS |
| RT-ядра | 142 | 142 |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| FP64 / FP64 Tensor | 34 / 67 TFLOPS | 30 / 60 TFLOPS |
| Срезы MIG | 7 × 18 ГБ | 7 × 16,5 ГБ |
| TDP | До 700 Вт | До 600 Вт |
| Интерконнект | NVIDIA NVLink™: 900 ГБ/с PCIe Gen5: 128 ГБ/с |
2- или 4-канальный мост NVIDIA NVLink: 900 ГБ/с на GPU PCIe Gen5: 128 ГБ/с |
| Конфиденциальные вычисления | Поддерживается | Поддерживается |
Какие LLM можно запускать на H200 в 2025 году?
| Модель (2025) | Параметры | Требуется VRAM* | Помещается на 1× H200? | Примечания |
|---|---|---|---|---|
| Llama 3.3 70B | 70 B dense | 70 ГБ (FP8) | ✔ | Для FP16 нужно 2 GPU. |
| Qwen 2.5 72B | 72 B dense | 72 ГБ (FP8) | ✔ | Впритык, но работает. |
| Любая dense-модель ≤ 70 B | — | ≤ 70 ГБ (FP8) | ✔ | Практический потолок для одной карты. |
| Малые модели ≤ 30 B | — | ≤ 60 ГБ (FP16) | ✔ (но неэффективно) | Лучше на более дешёвых GPU. |
С весами FP8 dense-модель на 140 B является теоретическим максимумом для одного GPU до превышения 141 ГБ. Архитектуры MoE могут превышать триллион параметров, поскольку каждый токен активна только часть модели.
Стоимость и энергопотребление H200
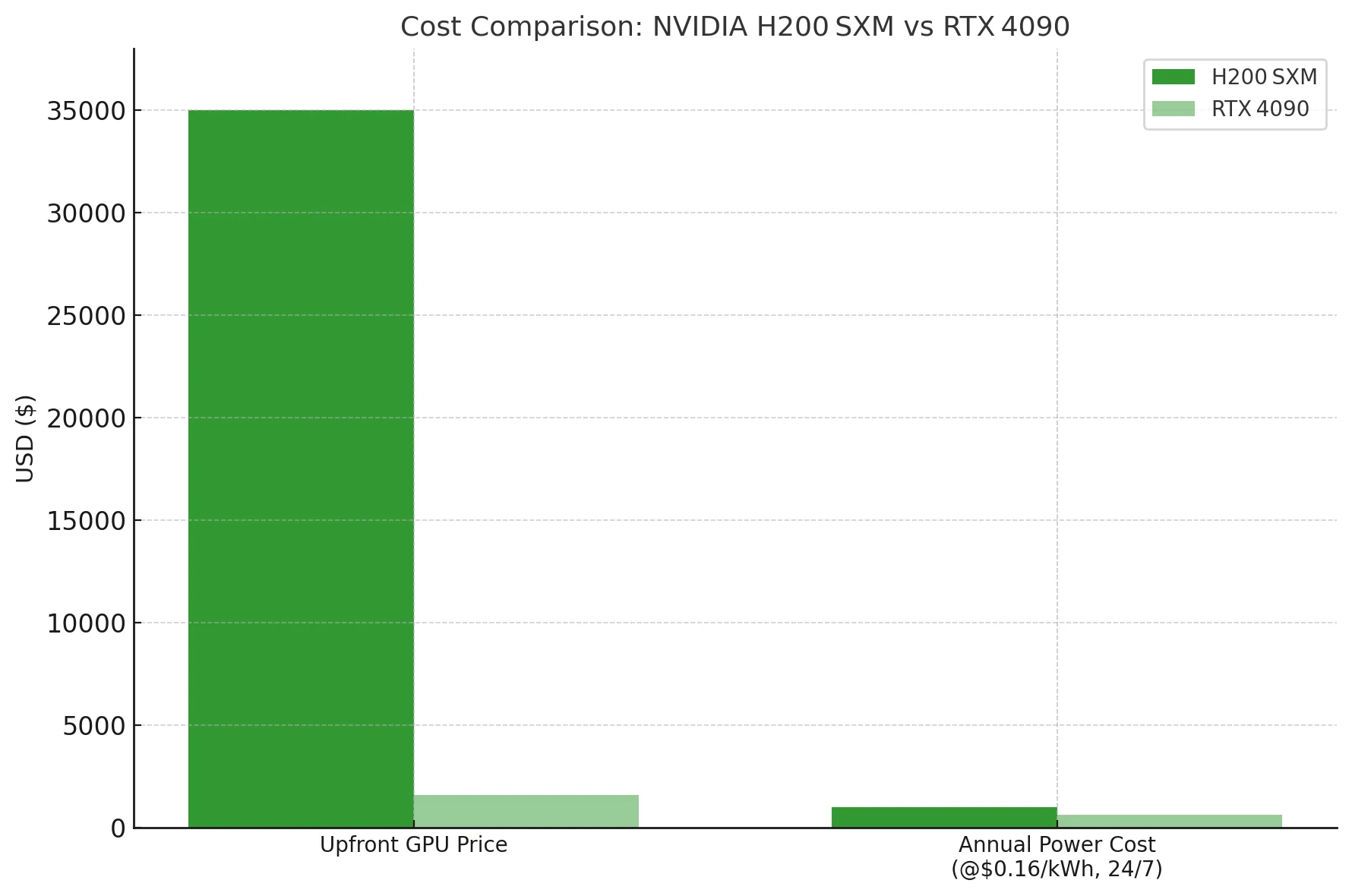
Если вам не нужно размещать dense LLM объёмом 70B или больше на одной карте, то 4090 обеспечивает на порядки лучшую стоимость за токен — даже без учёта электроэнергии. H200 — это кувалда для дата-центров; 4090 — бюджетный молоток.
Реальные сценарии использования NVIDIA H200
Обучение и инференс ИИ
Благодаря высокой пропускной способности тензорных ядер FP8 и TF32, H200 значительно ускоряет обучение и инференс, особенно для задач, ограниченных памятью, таких как механизмы внимания в больших языковых моделях (LLM). По сравнению с H100, он быстрее завершает эпохи и обеспечивает меньшую задержку ответов на запросы. Кроме того, благодаря поддержке Multi-Instance GPU (MIG) одну карту можно разделить для одновременного запуска нескольких моделей среднего размера, повышая эффективность использования ресурсов в периоды простоя.
Графика и визуализация
Оснащённый 142 RT-ядрами, H200 обеспечивает трассировку лучей в реальном времени для научной визуализации, что делает его пригодным для продвинутых задач рендеринга в исследованиях и инженерии.
Высокоточные HPC
С производительностью до 34 TFLOPS FP64 (вариант SXM) H200 обеспечивает работу требовательных симуляций в таких областях, как вычислительная гидродинамика (CFD), климатическое моделирование и количественные финансы. Более того, он поддерживает интеграцию суррогатных моделей ИИ в той же системе, объединяя традиционное моделирование и современный ИИ.
Когда H200 имеет смысл?
| ✅ Отличное соответствие | ❌ Не идеален |
|---|---|
| Обучение моделей класса GPT (≥100B) в сжатые сроки | Запуск моделей <30B для чат-ботов или RAG — избыточно по мощности и стоимости |
| Инференс dense-моделей 70B+ с целевой задержкой менее 10 мс | Развёртывание на периферии/в офисе без надёжного охлаждения и питания |
| Высокоточные HPC-нагрузки с большими потребностями в памяти и интеграцией ИИ | Чисто графический рендеринг — GPU RTX или Quadro более экономичны |
H200 против других GPU
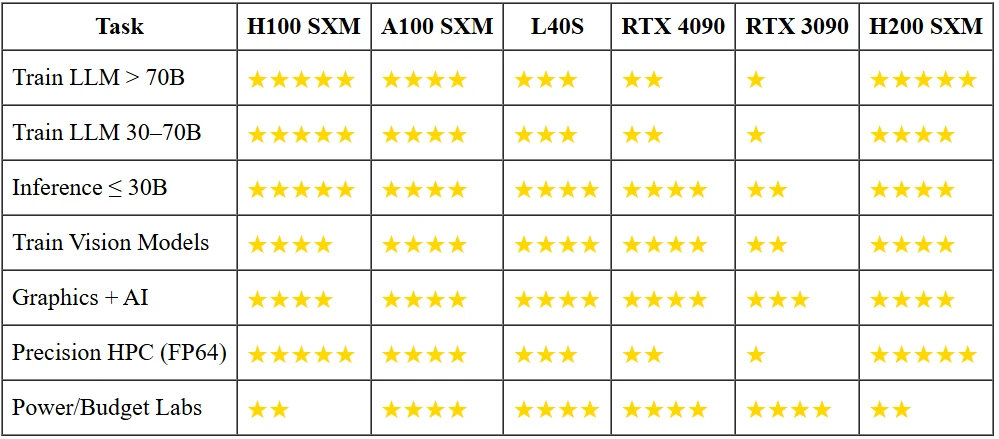
Почему малым моделям не нужно тяжёлое вооружение?
Запуск чат-бота с 13B параметров в 16-битном формате требует менее 30 ГБ VRAM. Это уже помещается на RTX 3090 при трети энергопотребления H100, а 4090 выдаст в пять раз больше токенов в секунду за десятую часть цены покупки. Если вам не нужно уместить модель 70B в задержку в несколько миллисекунд или обучать её с нуля, флагманские ускорители — это позолоченные молотки для гвоздей размером с арахис.
Как выбрать подходящий GPU по очень низкой цене?
Novita AI предлагает облачную платформу с высокопроизводительными GPU-инстансами. Благодаря мощным GPU она обеспечивает эффективную производительность для сложных задач, повышает доступность развёртывания на различном оборудовании и предлагает экономичное решение по сравнению с поддержкой локального оборудования для масштабных развёртываний ИИ.
Шаг 1: Зарегистрируйте аккаунт
Создайте аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел “Explore” на боковой панели, чтобы просмотреть предложения GPU и начать путь разработки ИИ.

Шаг 2: Изучите шаблоны и GPU-серверы
Выберите шаблон, например PyTorch, TensorFlow или CUDA, соответствующий потребностям вашего проекта. Затем выберите предпочтительную конфигурацию GPU — доступны такие мощные варианты, как L40S, RTX 4090, H200 или A100 SXM4, каждый с различными характеристиками VRAM, RAM и хранилища.
Шаг 3: Настройте развёртывание
Настройте своё окружение, выбрав предпочтительную операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных рабочих нагрузок ИИ и задач разработки.

Шаг 4: Запустите инстанс
Нажмите “Launch Instance”, чтобы начать развёртывание. Ваша высокопроизводительная GPU-среда будет готова в течение нескольких минут, позволяя немедленно приступить к машинному обучению, рендерингу или вычислительным проектам.

NVIDIA H200 — это мощное обновление по сравнению с H100, созданное специально для крупномасштабного обучения ИИ, инференса и высокоточных HPC-нагрузок. Благодаря передовой памяти HBM3e, исключительной производительности FP8 и поддержке MIG, он превосходно справляется с запуском dense-моделей 70B+ или объединением ИИ с традиционным моделированием.
Однако для небольших моделей или менее интенсивных задач более доступные GPU, такие как RTX 4090, предлагают гораздо лучшую экономическую эффективность. Если вы не связаны нагрузками, требовательными к памяти, рассмотрите более скромную конфигурацию или изучите облачные платформы, такие как Novita AI, чтобы получить мощность уровня H200 без затрат на инфраструктуру.
Часто задаваемые вопросы
Для чего используется H200?
Он идеально подходит для обучения или обслуживания крупных (70B+) LLM, инференса ИИ в реальном времени, научной визуализации с трассировкой лучей и HPC-симуляций с высокой точностью FP64.
Можно ли запустить модель 70B на одном H200?
Да, если используется FP8-квантизация. Но всё, что превышает 70B (dense), может потребовать разделения модели или нескольких GPU.
Является ли H200 избыточным для малых моделей?
Да. Модель 13B легко помещается на GPU, такие как RTX 3090 или 4090, которые гораздо дешевле и энергоэффективнее.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развёртывания моделей ИИ с помощью нашего простого API, а также предоставляет доступное и надёжное GPU-облако для создания и масштабирования.
Рекомендуемое чтение



