

مع استمرار نماذج اللغة الكبيرة في التوسع لتتجاوز 70 مليار معامل، لم يكن الطلب على وحدات معالجة الرسوميات (GPUs) القادرة على التعامل مع أعباء عمل الذكاء الاصطناعي المقيدة بالذاكرة أكبر من أي وقت مضى. تقدّم NVIDIA H200—وهو مسرّع من الجيل التالي مصمم ليدفع حدود الذكاء الاصطناعي التوليدي والحوسبة العلمية والتصور في الوقت الفعلي.
مزودة بذاكرة HBM3e وأداء Tensor Core FP8 ودعم MIG للنماذج المتعددة، تَعِد H200 بتقليل عدد وحدات GPU اللازمة لأعباء العمل الضخمة مع تسريع التدريب والاستدلال كما لم يحدث من قبل. لكن السؤال هو: هل هذه القوة الهائلة مناسبة لك؟
يحلل هذا المقال ما تتفوق فيه H200، وما النماذج التي يمكنها دعمها، ومتى يكون استخدامها منطقيًا—ومتى يكون من الأفضل توفير المال عبر بدائل أكثر ذكاءً مثل RTX 4090 أو منصات سحابية مثل Novita AI.
ما هو H200؟
تُقدّم NVIDIA H200 كخطوة رئيسية بعد H100، مصممة خصيصًا لأكثر مهام الذكاء الاصطناعي التوليدي والحوسبة عالية الأداء (HPC) تطلبًا—خاصة تلك التي تعاني من اختناق الذاكرة. في قلب هذه الترقية يكمن ظهور ذاكرة HBM3e، التي توفر سعة أكبر تصل إلى 1.8× وعرض نطاق ترددي أعلى بنحو 1.4× مقارنة بسابقتها. وهذا يعني الحاجة إلى عدد أقل من وحدات GPU لتشغيل النماذج الضخمة بكفاءة. صُمّمت H200 لمنصات السحابة فائقة الاتساع ومختبرات الأبحاث المتقدمة والمؤسسات التي تتعامل مع نماذج LLM واسعة النطاق أو عمليات المحاكاة عالية الدقة.

| المقياس | H200 SXM | H200 NVL |
|---|---|---|
| الذاكرة | 141 جيجابايت @ 4.8 تيرابايت/ثانية | 141 جيجابايت @ 4.8 تيرابايت/ثانية |
| نوى CUDA | 16,896 | 16,896 |
| نوى Tensor (الجيل الرابع) | FP8 3.96 PFLOPS; FP16 1.98 PFLOPS; TF32 0.99 PFLOPS | FP8 3.34 PFLOPS; FP16 1.67 PFLOPS; TF32 0.84 PFLOPS |
| نوى RT | 142 | 142 |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| FP64 / FP64 Tensor | 34 / 67 TFLOPS | 30 / 60 TFLOPS |
| شرائح MIG | 7 × 18 جيجابايت | 7 × 16.5 جيجابايت |
| TDP | حتى 700 واط | حتى 600 واط |
| الربط البيني | NVIDIA NVLink™: 900 جيجابايت/ثانية PCIe Gen5: 128 جيجابايت/ثانية |
جسر NVIDIA NVLink ثنائي أو رباعي الاتجاه: 900 جيجابايت/ثانية لكل GPU PCIe Gen5: 128 جيجابايت/ثانية |
| الحوسبة السرية | مدعومة | مدعومة |
ما هي نماذج LLM التي يمكن تشغيلها على H200 في 2025؟
| النموذج (2025) | المعلمات | احتياج VRAM* | هل يناسب 1 × H200؟ | ملاحظات |
|---|---|---|---|---|
| Llama 3.3 70B | 70 B كثيف | 70 جيجابايت (FP8) | ✔ | يتطلب FP16 وحدتي GPU. |
| Qwen 2.5 72B | 72 B كثيف | 72 جيجابايت (FP8) | ✔ | ضيق لكن يعمل. |
| أي نموذج كثيف ≤ 70 B | — | ≤ 70 جيجابايت (FP8) | ✔ | سقف عملي لبطاقة واحدة. |
| نماذج صغيرة ≤ 30 B | — | ≤ 60 جيجابايت (FP16) | ✔ (لكن إهدار) | أفضل على وحدات GPU أرخص. |
باستخدام أوزان FP8، فإن نموذجًا كثيفًا بحجم 140 B هو الحد النظري الأقصى لبطاقة GPU واحدة قبل تجاوز 141 جيجابايت. يمكن للهندسات المعمارية MoE تجاوز تريليون معامل نظرًا لتنشيط مجموعة فرعية فقط لكل رمز.
تكلفة H200 واعتبارات الطاقة
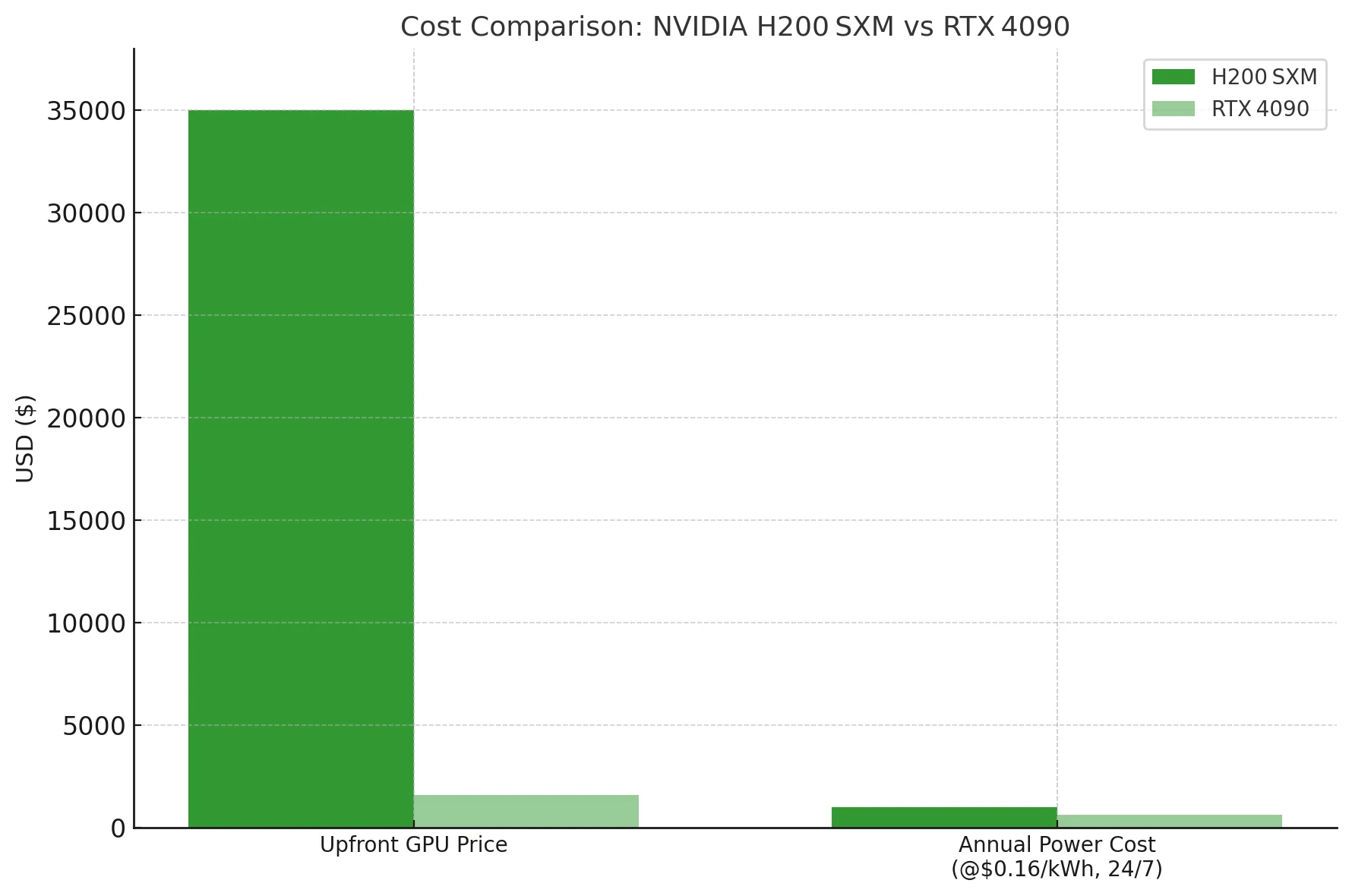
ما لم تكن مضطرًا لتشغيل نموذج LLM كثيف بحجم 70 B أو أكبر على بطاقة واحدة، فإن 4090 تُحقق تكلفة لكل رمز أفضل بكثير—حتى قبل حساب الكهرباء. H200 هي مطرقة ثقيلة لمراكز البيانات؛ أما 4090 فهي مطرقة عادية صديقة للميزانية.
حالات الاستخدام الواقعية لـ NVIDIA H200
تدريب واستدلال الذكاء الاصطناعي
بفضل سرعة Tensor Core العالية في FP8 وTF32، تُسرّع H200 التدريب والاستدلال بشكل كبير—خاصة للمهام المقيدة بالذاكرة مثل آليات الانتباه في نماذج اللغة الكبيرة (LLMs). مقارنة بـ H100، تُنهي العصور بشكل أسرع وتقدم استجابات أقل زمنًا للطلبات.
بالإضافة إلى ذلك، بفضل دعم Multi-Instance GPU (MIG)، يمكن تقسيم نفس البطاقة لتشغيل عدة نماذج متوسطة الحجم في وقت واحد، مما يحسن كفاءة الموارد خلال فترات الخمول.
الرسوميات والتصور
مزودة بـ 142 نواة RT، تُمكّن H200 التصور العلمي المُتبعّر بالأشعة في الوقت الفعلي، مما يجعلها قابلة للاستخدام في أعباء عمل التقديم المتقدمة في مجالي البحث والهندسة.
الحوسبة عالية الأداء (HPC) عالية الدقة
مع أداء FP64 يصل إلى 34 TFLOPS (إصدار SXM)، تُشغّل H200 عمليات المحاكاة الصعبة في مجالات مثل ديناميكا الموائع الحاسوبية (CFD)، ونمذجة المناخ، والتمويل الكمي. والأفضل من ذلك، أنها تدعم دمج نماذج الذكاء الاصطناعي البديلة داخل نفس النظام، مما يمزج بين المحاكاة التقليدية والذكاء الاصطناعي الحديث.
متى تكون H200 خيارًا منطقيًا؟
| ✅ مناسبة جدًا | ❌ غير مثالية |
|---|---|
| تدريب نماذج من فئة GPT (≥100B) بجداول زمنية ضيقة | تشغيل نماذج <30B للدردشة أو RAG—إهدار في الطاقة والتكلفة |
| استدلال نماذج كثيفة بحجم 70B+ بهدف زمن استجابة أقل من 10 ميللي ثانية | نشر في المواقع الطرفية أو المكاتب التي تفتقر إلى التبريد والطاقة المناسبين |
| أعباء عمل HPC مزدوجة الدقة مع احتياجات كبيرة للذاكرة لدمج الذكاء الاصطناعي | تقديم رسوميات بحتة—وحدات RTX أو Quadro أكثر اقتصادًا |
H200 مقابل وحدات GPU أخرى
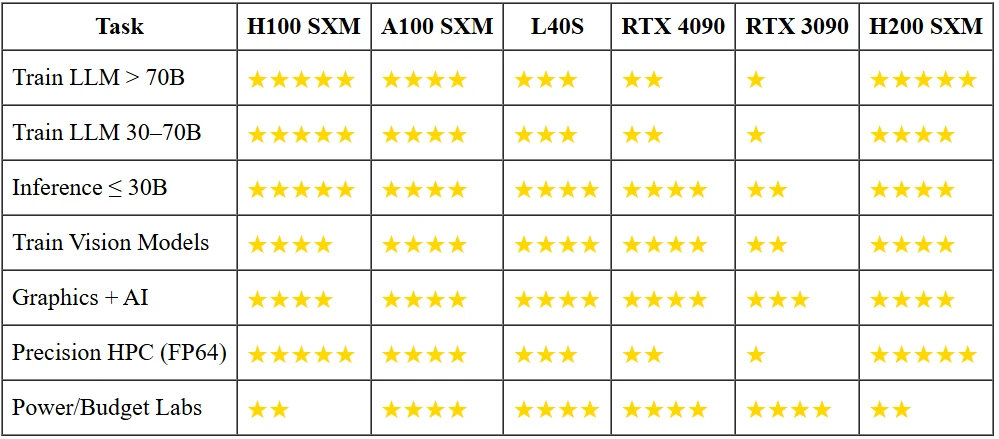
لماذا لا تحتاج النماذج الصغيرة إلى المدافع الكبيرة؟
تشغيل روبوت محادثة بمعاملات 13B بتنسيق 16 بت يحتاج إلى أقل من 30 جيجابايت من VRAM. هذا يكفي لبطاقة RTX 3090 بطاقة ثلث طاقة H100، وستخدم 4090 خمسة أضعاف عدد الرموز في الثانية مقابل عُشر سعر الشراء. ما لم تكن مضطرًا لحشر نموذج 70B في زمن استجابة أحادي الرقم أو تدريبه من الصفر، فإن المسرعات الرائدة هي مطارق مطلية بالذهب لمسامير بحجم الفول السوداني.
كيفية اختيار GPU المناسبة بسعر منخفض جدًا؟
توفر Novita AI منصة سحابية تحتوي على مثيلات GPU عالية الأداء. بفضل وحدات GPU القوية، تضمن أداءً فعالًا للمهام المعقدة، وتُعزز إمكانية الوصول للنشر عبر أجهزة متنوعة، وتقدم حلاً فعالاً من حيث التكلفة مقارنة بصيانة الأجهزة المحلية لنشر الذكاء الاصطناعي على نطاق واسع.
الخطوة 1: إنشاء حساب
أنشئ حسابك في Novita AI من خلال موقعنا. بعد التسجيل، انتقل إلى قسم “Explore” في الشريط الجانبي الأيسر لعروض GPU الخاصة بنا وابدأ رحلة تطوير الذكاء الاصطناعي.

الخطوة 2: استكشاف القوالب وخوادم GPU
اختر من بين قوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم حدد تكوين GPU المفضل لديك—تتضمن الخيارات L40S القوية أو RTX 4090 أو H200 أو A100 SXM4، ولكل منها مواصفات مختلفة من VRAM وRAM والتخزين.
الخطوة 3: تخصيص النشر
خصص بيئتك باختيار نظام التشغيل المفضل وخيارات التكوين لضمان أداء أمثل لأعباء عمل الذكاء الاصطناعي واحتياجات التطوير الخاصة بك.

الخطوة 4: تشغيل مثيل
اختر “Launch Instance” لبدء النشر. ستكون بيئة GPU عالية الأداء جاهزة في غضون دقائق، مما يسمح لك بالبدء فورًا في مشاريع التعلم الآلي أو التقديم أو الحوسبة.

تعتبر NVIDIA H200 ترقية قوية عن H100، مصممة خصيصًا لأعباء العمل الكبيرة في تدريب واستدلال الذكاء الاصطناعي والحوسبة عالية الأداء. بفضل ذاكرة HBM3e المتطورة والأداء الاستثنائي لـ FP8 ودعم MIG، تتفوق في تشغيل نماذج LLM الكثيفة بحجم 70B+ أو دمج الذكاء الاصطناعي مع المحاكاة التقليدية.
ومع ذلك، بالنسبة للنماذج الأصغر أو المهام الأقل كثافة، توفر وحدات GPU الأقل تكلفة مثل RTX 4090 كفاءة تكلفة أفضل بكثير. إذا لم تكن مقيدًا بحالات الاستخدام الثقيلة على الذاكرة، ففكر في إعدادات أخف—أو استكشف المنصات السحابية مثل Novita AI للوصول إلى قوة فئة H200 دون تكلفة البنية التحتية.
الأسئلة الشائعة
ما هو استخدام H200؟
إنها مثالية لتدريب أو تقديم نماذج LLM كبيرة (70B+) أو الاستدلال في الوقت الفعلي للذكاء الاصطناعي أو التصور العلمي المُتبعّر بالأشعة أو محاكاة HPC الثقيلة على FP64.
هل يمكن تشغيل نموذج 70B على بطاقة H200 واحدة؟
نعم، إذا استخدمت تكميم FP8. لكن أي نموذج يتجاوز 70B (كثيف) قد يتطلب تقسيم النموذج أو استخدام عدة وحدات GPU.
هل H200 مبالغ فيها للنماذج الصغيرة؟
نعم. نموذج 13B يناسب بسهولة وحدات GPU مثل RTX 3090 أو 4090، وهي أرخص بكثير وأكثر كفاءة في استهلاك الطاقة.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات (API) البسيطة، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء والتوسع.
قراءة موصى بها



