

大規模言語モデルが700億パラメータを超えて拡大し続ける中、メモリ制約のあるAIワークロードを処理できるGPUへの需要はかつてないほど高まっています。登場したのは NVIDIA H200 — 生成AI、科学計算、リアルタイム可視化の限界を押し広げるために設計された次世代アクセラレータです。
**HBM3eメモリ **、**FP8 Tensor Core性能 **、MIGマルチモデルサポート を搭載したH200は、大規模ワークロードに必要なGPU数を削減しながら、トレーニングと推論をかつてないスピードで加速することを約束します。しかし問題は、このパワーハウスがあなたに適しているかどうかです。
この記事では、H200が最も得意とする分野、サポートできるモデル、導入が理にかなうケース、そして RTX 4090 や Novita AI のようなクラウドプラットフォームといった賢い代替手段でコストを節約した方が良いケースを解説します。
H200とは何か?
NVIDIAはH200を、H100を大きく超えるステップとして紹介しています。特にメモリがボトルネックとなる、最も要求の厳しい生成AIおよびハイパフォーマンスコンピューティング(HPC)タスク向けに設計されています。このアップグレードの核心は、HBM3eメモリの初採用です。前世代と比較して最大1.8倍の容量と約1.4倍の帯域幅を実現し、大規模モデルを効率的に実行するために必要なGPU数を減らします。H200は、ハイパースケールクラウドプラットフォーム、先進的な研究ラボ、大規模LLMや高精度シミュレーションに取り組む企業向けに調整されています。

| メトリック | H200 SXM | H200 NVL |
|---|---|---|
| メモリ | 141 GB @ 4.8 TB/s | 141 GB @ 4.8 TB/s |
| CUDAコア | 16 896 | 16 896 |
| Tensorコア(第4世代) | FP8 3.96 PFLOPS; FP16 1.98 PFLOPS; TF32 0.99 PFLOPS | FP8 3.34 PFLOPS; FP16 1.67 PFLOPS; TF32 0.84 PFLOPS |
| RTコア | 142 | 142 |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| FP64 / FP64 Tensor | 34 / 67 TFLOPS | 30 / 60 TFLOPS |
| MIGスライス | 7 × 18 GB | 7 × 16.5 GB |
| TDP | 最大700 W | 最大600 W |
| インターコネクト | NVIDIA NVLink™: 900GB/s PCIe Gen5: 128GB/s |
2ウェイまたは4ウェイ NVIDIA NVLinkブリッジ: 900GB/s(GPUあたり) PCIe Gen5: 128GB/s |
| 機密コンピューティング | 対応 | 対応 |
2025年にH200で実行できるLLMは?
| モデル(2025年) | パラメータ | 必要VRAM\ * | 1 × H200に適合? | 備考 |
|---|---|---|---|---|
| Llama 3.3 70B | 70 B (dense) | 70 GB(FP8) | ✔ | FP16では2GPU必要。 |
| Qwen 2.5 72B | 72 B (dense) | 72 GB(FP8) | ✔ | ぎりぎりだが動作。 |
| 70B以下のdenseモデル | — | ≤ 70 GB(FP8) | ✔ | 実用的なシングルカード上限。 |
| 30B以下の小規模モデル | — | ≤ 60 GB(FP16) | ✔ (ただし非効率) | より安価なGPUが適切。 |
FP8ウェイトを使用した場合、dense 140 B モデルが141 GBを超える前の理論上のシングルGPU最大値です。MoEアーキテクチャでは、各トークンでアクティブになるのはサブセットのみであるため、1兆パラメータを超えることも可能です。
H200のコストと電力に関する考慮事項
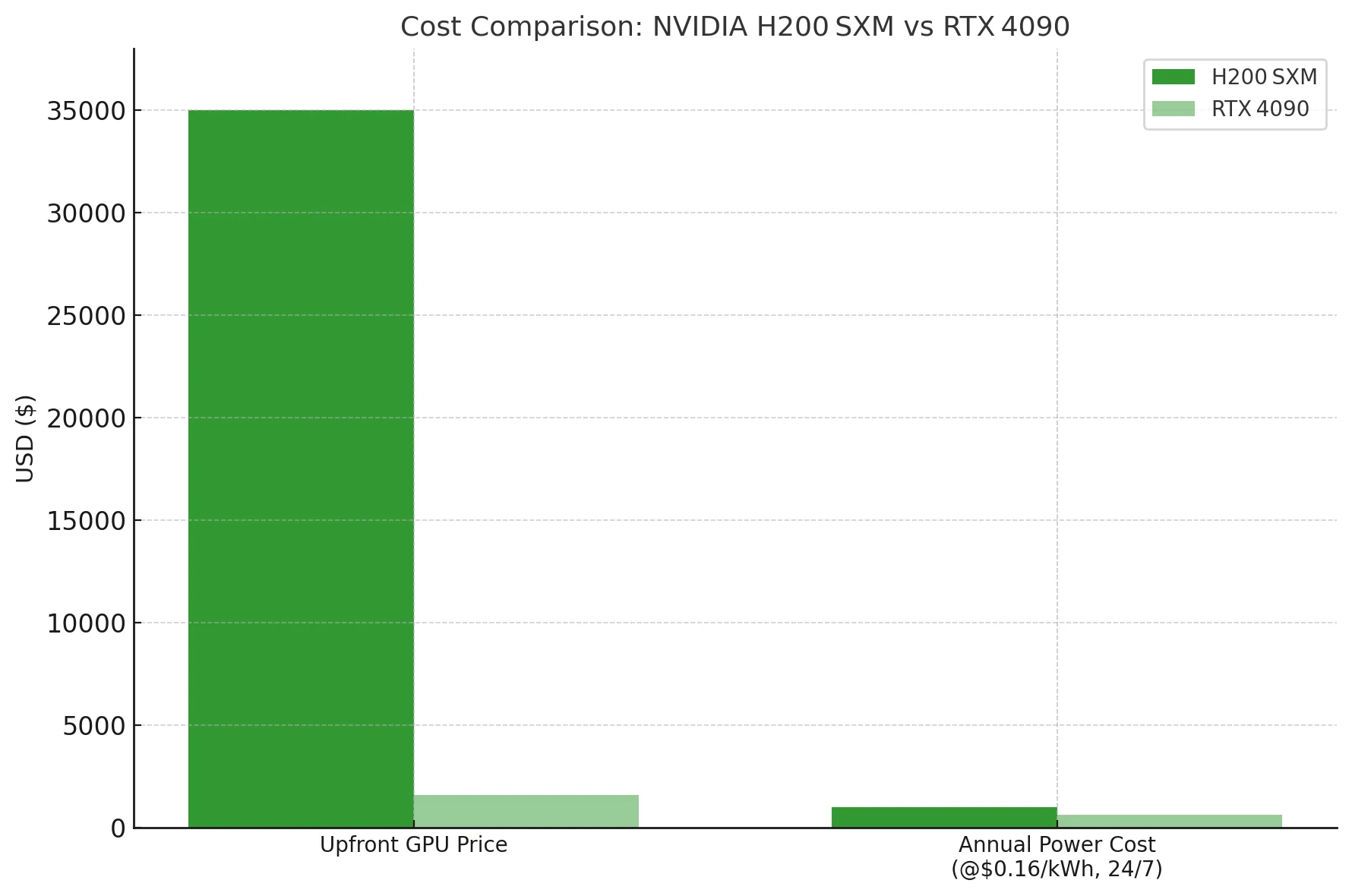
70Bのdense LLM以上を1枚のカードに収める必要がない限り、4090は桁違いに優れたコストパフォーマンス(トークンあたりのコスト)を実現します。電気代を考慮する前からです。H200はデータセンター向けの大ハンマー、4090は予算に優しい木槌です。
NVIDIA H200の実世界でのユースケース
AIトレーニングと推論
高いFP8およびTF32 Tensor Coreスループットにより、H200はトレーニングと推論を大幅に加速します。特に、大規模言語モデル(LLM)の注意機構のようなメモリ制約のあるタスクで効果を発揮します。H100と比較して、エポック完了が速くなり、レイテンシの低いプロンプト応答を実現します。
さらに、マルチインスタンスGPU(MIG)サポートにより、1枚のカードを分割して複数の中規模モデルを同時に実行できるため、アイドル期間中のリソース効率が向上します。
グラフィックスと可視化
142のRTコアを搭載したH200は、リアルタイムのレイトレーシング科学可視化を可能にし、研究やエンジニアリングにおける高度なレンダリングワークロードに適しています。
高精度HPC
最大34 TFLOPSのFP64性能(SXMバリアント)により、H200は流体力学(CFD)、気候モデリング、クオンツファイナンスなどの要求の厳しいシミュレーションを処理します。さらに、同じシステム内でAIサロゲートモデルの統合をサポートし、従来のシミュレーションと最新のAIを融合します。
H200が理にかなうのはいつ?
| ✅ **最適なフィット ** | ❌ ** 理想的ではない** |
|---|---|
| 厳しい納期でGPTクラスモデル(100B以上)をトレーニング | 30B未満のモデルをチャットボットやRAGに使用 — パワーとコストで過剰 |
| 70B以上のdenseモデルをサブ10msレイテンシ目標で推論 | 堅牢な冷却と電力を欠くエッジ/オフィスでの展開 |
| AI統合に大容量メモリを必要とする倍精度HPCワークロード | 純粋なグラフィックスレンダリング — RTXまたはQuadro GPUの方が経済的 |
H200 VS その他のGPU
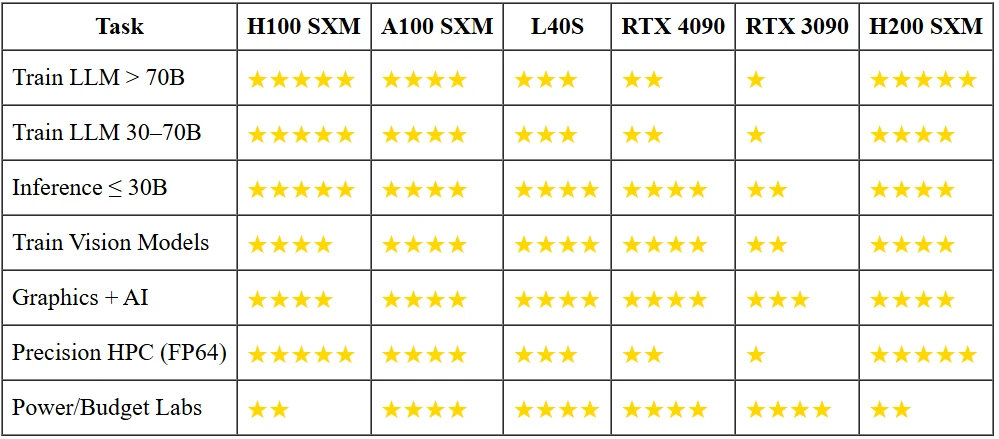
なぜ小規模モデルに大きな武器は必要ないのか?
13Bパラメータのチャットボットを16ビットで実行するには、30 GB未満のVRAMで十分です。これはRTX 3090にすでに収まり、その消費電力はH100の3分の1です。また、4090は購入価格が10分の1で、1秒あたり5倍のトークンを処理できます。70Bモデルを1桁ミリ秒のレイテンシに収めるか、ゼロからトレーニングする必要がない限り、フラッグシップアクセラレータはピーナッツサイズの釘に金メッキのハンマーです。
非常に低価格で適切なGPUを選ぶ方法
Novita AIは、高性能GPUインスタンスを備えたクラウドベースのプラットフォームを提供します。強力なGPUにより、複雑なタスクの効率的なパフォーマンスを保証し、さまざまなハードウェアへの展開アクセシビリティを向上させ、大規模なAI展開においてローカルハードウェアを維持するよりもコスト効率の高いソリューションを提供します。
ステップ1:アカウント登録
ウェブサイトからNovita AIアカウントを作成します。登録後、左サイドバーの「Explore」セクションに移動してGPUの提供内容を確認し、AI開発の旅を始めましょう。

ステップ2:テンプレートとGPUサーバーの探索
プロジェクトのニーズに合ったPyTorch、TensorFlow、CUDAなどのテンプレートを選択します。次に、希望するGPU構成を選択します。L40S、RTX 4090、H200、A100 SXM4などのオプションがあり、それぞれ異なるVRAM、RAM、ストレージ仕様があります。
ステップ3:デプロイメントのカスタマイズ
好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに最適なパフォーマンスを実現します。

ステップ4:インスタンスの起動
「Launch Instance」を選択してデプロイを開始します。高性能GPU環境は数分以内に準備完了し、すぐに機械学習、レンダリング、計算プロジェクトを開始できます。

NVIDIA H200はH100からの強力なアップグレードであり、大規模なAIトレーニング、推論、高精度HPCワークロード向けに設計されています。最先端のHBM3eメモリ、優れたFP8性能、MIGサポートにより、70B以上のdense LLMの実行や、AIと従来のシミュレーションの融合に優れています。
ただし、小規模モデルや負荷の低いタスクでは、RTX 4090のようなより手頃なGPUの方がはるかに優れたコスト効率を発揮します。メモリを大量に消費するユースケースに縛られていないのであれば、より軽量な構成を検討するか、Novita AIのようなクラウドプラットフォームを活用して、インフラコストをかけずにH200クラスのパワーにアクセスすることをお勧めします。
よくある質問
H200は何に使われますか?
大規模(70B以上)LLMのトレーニングやサービング、リアルタイムAI推論、レイトレーシングによる科学可視化、FP64重視のHPCシミュレーションに最適です。
1台のH200で70Bモデルを実行できますか?
はい、FP8量子化を使用すれば可能です。ただし、70B(dense)を超える場合は、モデル分割または複数GPUが必要になる場合があります。
小規模モデルにH200は過剰ですか?
はい。13BモデルはRTX 3090や4090のようなGPUに簡単に収まり、それらははるかに安価で電力効率も優れています。
Novita AI は、シンプルなAPIを使用してAIモデルを簡単にデプロイできる開発者向けのAIクラウドプラットフォームであり、手頃で信頼性の高いGPUクラウドを提供して構築とスケーリングを支援します。
おすすめの記事



