

À medida que os grandes modelos de linguagem continuam a escalar além de 70 bilhões de parâmetros, a demanda por GPUs capazes de lidar com cargas de trabalho de IA limitadas por memória nunca foi tão grande. Conheça o NVIDIA H200 — um acelerador de nova geração construído para ultrapassar os limites da IA generativa, da computação científica e da visualização em tempo real.
Equipado com memória HBM3e, desempenho FP8 Tensor Core e suporte multi-modelo MIG, o H200 promete reduzir o número de GPUs necessárias para cargas de trabalho massivas, acelerando o treinamento e a inferência como nunca antes. Mas a questão é: Este potente dispositivo é ideal para você?
Este artigo detalha o que o H200 faz de melhor, quais modelos ele pode suportar, quando faz sentido — e quando é melhor economizar com alternativas mais inteligentes, como a RTX 4090 ou plataformas em nuvem como a Novita AI.
O que é o H200?
A NVIDIA apresenta o H200 como um grande passo além do H100, projetado especificamente para as tarefas mais exigentes de IA generativa e computação de alto desempenho (HPC) — especialmente aquelas limitadas pela memória. No centro desta atualização está a estreia da memória HBM3e, oferecendo até 1,8× mais capacidade e aproximadamente 1,4× mais largura de banda em comparação com seu antecessor. Isso significa que menos GPUs são necessárias para executar modelos massivos de forma eficiente. O H200 é voltado para plataformas de nuvem hiperescala, laboratórios de pesquisa avançados e empresas que lidam com LLMs de grande porte ou simulações de alta precisão.

| Métrica | H200 SXM | H200 NVL |
|---|---|---|
| Memória | 141 GB @ 4,8 TB/s | 141 GB @ 4,8 TB/s |
| Núcleos CUDA | 16 896 | 16 896 |
| Tensor Cores (gen 4) | FP8 3,96 PFLOPS; FP16 1,98 PFLOPS; TF32 0,99 PFLOPS | FP8 3,34 PFLOPS; FP16 1,67 PFLOPS; TF32 0,84 PFLOPS |
| Núcleos RT | 142 | 142 |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| FP64 / FP64 Tensor | 34 / 67 TFLOPS | 30 / 60 TFLOPS |
| Fatias MIG | 7 × 18 GB | 7 × 16,5 GB |
| TDP | Até 700 W | Até 600 W |
| Interconexão | NVIDIA NVLink™: 900 GB/s PCIe Gen5: 128 GB/s |
Bridge NVIDIA NVLink de 2 ou 4 vias: 900 GB/s por GPU PCIe Gen5: 128 GB/s |
| Computação Confidencial | Suportada | Suportada |
Quais LLMs Podem Ser Executados no H200 em 2025?
| Modelo (2025) | Parâmetros | Necessidade de VRAM* | Cabe em 1 × H200? | Observações |
|---|---|---|---|---|
| Llama 3.3 70B | 70 B denso | 70 GB (FP8) | ✔ | FP16 precisa de 2 GPUs. |
| Qwen 2.5 72B | 72 B denso | 72 GB (FP8) | ✔ | apertado, mas funciona. |
| Qualquer modelo denso ≤ 70 B | — | ≤ 70 GB (FP8) | ✔ | Teto prático de placa única. |
| Modelos pequenos ≤ 30 B | — | ≤ 60 GB (FP16) | ✔ (mas desperdício) | Melhor em GPUs mais baratas. |
Com pesos FP8, um modelo denso de 140 B é o máximo teórico de GPU única antes de exceder 141 GB. Arquiteturas MoE podem ultrapassar um trilhão de parâmetros porque apenas um subconjunto está ativo a cada token.
Custo e Considerações de Energia do H200
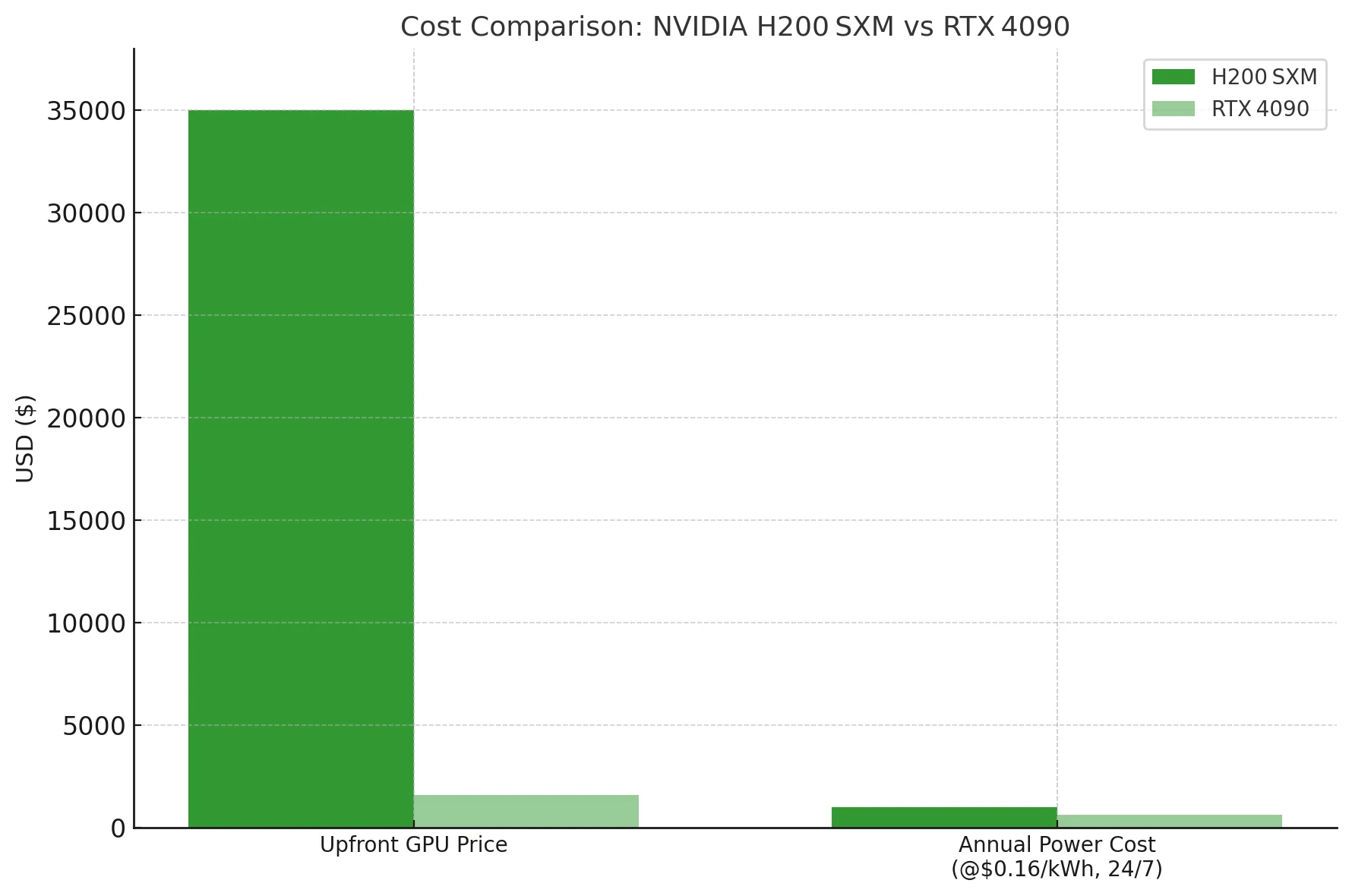
A menos que você precise encaixar um LLM denso de 70 B ou maior em uma única placa, a 4090 oferece uma relação custo-por-token ordens de grandeza melhor — mesmo antes de considerar a eletricidade. O H200 é uma marreta de datacenter; a 4090 é um martelo econômico.
Casos de Uso Reais do NVIDIA H200
Treinamento e Inferência de IA
Graças à sua alta taxa de transferência FP8 e TF32 Tensor Core, o H200 acelera significativamente o treinamento e a inferência — especialmente para tarefas limitadas por memória, como mecanismos de atenção em grandes modelos de linguagem (LLMs). Comparado ao H100, ele completa épocas mais rapidamente e oferece respostas de prompt com menor latência.
Além disso, com suporte a Multi-Instance GPU (MIG), a mesma placa pode ser particionada para executar vários modelos de médio porte simultaneamente, melhorando a eficiência dos recursos durante períodos ociosos.
Gráficos e Visualização
Equipado com 142 núcleos RT, o H200 permite visualização científica com ray tracing em tempo real, tornando-se viável para cargas de trabalho avançadas de renderização em pesquisa e engenharia.
HPC de Precisão
Com até 34 TFLOPS de desempenho FP64 (variante SXM), o H200 alimenta simulações exigentes em áreas como dinâmica de fluidos computacional (CFD), modelagem climática e finanças quantitativas. Melhor ainda, ele suporta a integração de modelos substitutos de IA no mesmo sistema, mesclando simulação tradicional e IA moderna.
Quando o H200 Faz Sentido?
| ✅ Ótimo Ajuste | ❌ Não é Ideal |
|---|---|
| Treinar modelos tipo GPT (≥100B) em prazos apertados | Executar modelos <30B para chatbots ou RAG — exagero em potência e custo |
| Inferência de modelos densos 70B+ com metas de latência abaixo de 10ms | Implantações em borda/escritório sem resfriamento e energia robustos |
| Cargas de trabalho HPC de dupla precisão com grandes necessidades de memória para integração de IA | Renderização gráfica pura — GPUs RTX ou Quadro são mais econômicas |
H200 vs Outras GPUs
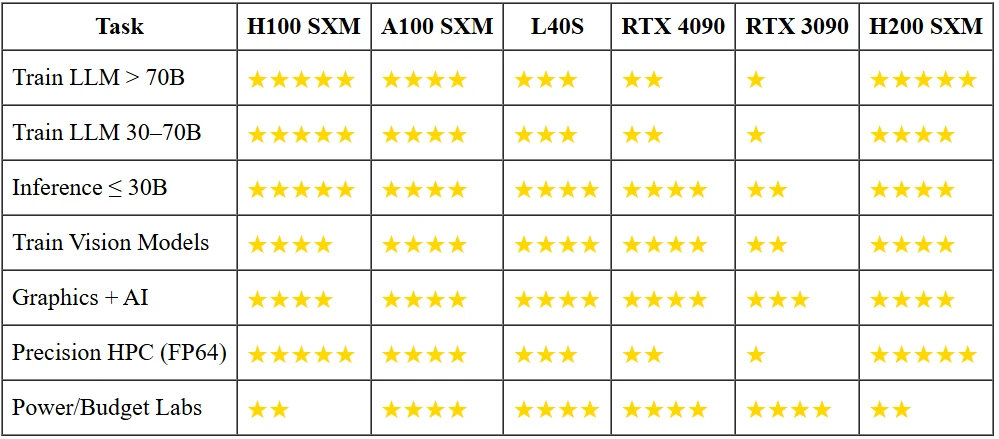
Por que Modelos Pequenos Não Precisam das Armas Pesadas?
Executar um chatbot de 13B parâmetros em 16 bits consome menos de 30 GB de VRAM. Isso já cabe em uma RTX 3090 com um terço da potência de um H100, e uma 4090 servirá cinco vezes mais tokens por segundo por um décimo do preço de compra. A menos que você precise encaixar um modelo de 70B em latência de dígito único ou treiná-lo do zero, os aceleradores principais são martelos banhados a ouro para pregos do tamanho de amendoins.
Como Escolher a GPU Adequada a um Preço Muito Baixo?
A Novita AI fornece uma plataforma baseada em nuvem com instâncias de GPU de alto desempenho. Com GPUs potentes, garante desempenho eficiente para tarefas complexas, melhora a acessibilidade para implantação em vários hardwares e oferece uma solução econômica em comparação com a manutenção de hardware local para implantações de IA em larga escala.
Passo 1: Crie uma conta
Crie sua conta Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e iniciar sua jornada de desenvolvimento de IA.

Passo 2: Explore modelos e servidores GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que atendam às necessidades do seu projeto. Em seguida, selecione sua configuração de GPU preferida — as opções incluem as potentes L40S, RTX 4090, H200 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.
Passo 3: Personalize sua implantação
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir desempenho ideal para suas cargas de trabalho específicas de IA e necessidades de desenvolvimento.

Passo 4: Inicie uma instância
Selecione “Iniciar Instância” para começar sua implantação. Seu ambiente de GPU de alto desempenho estará pronto em minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computação.

O NVIDIA H200 é uma atualização poderosa em relação ao H100, projetado especificamente para treinamento de IA em larga escala, inferência e cargas de trabalho HPC de precisão. Com memória HBM3e de ponta, desempenho FP8 excepcional e suporte MIG, ele se destaca na execução de LLMs densos de 70B+ ou na combinação de IA com simulação tradicional.
No entanto, para modelos menores ou tarefas menos intensivas, GPUs mais acessíveis como a RTX 4090 oferecem uma relação custo-benefício muito melhor. Se você não estiver preso a casos de uso com uso intensivo de memória, considere uma configuração mais enxuta — ou explore plataformas em nuvem como a Novita AI para acessar o poder equivalente ao H200 sem o custo de infraestrutura.
Perguntas Frequentes
Para que serve o H200?
É ideal para treinar ou servir LLMs grandes (70B+), inferência de IA em tempo real, visualização científica com ray tracing e simulações HPC pesadas em FP64.
Posso executar um modelo de 70B em um único H200?
Sim, se você usar quantização FP8. Mas qualquer coisa além de 70B (denso) pode exigir divisão de modelo ou várias GPUs.
O H200 é exagero para modelos pequenos?
Sim. Um modelo de 13B cabe facilmente em GPUs como a RTX 3090 ou 4090, que são muito mais baratas e eficientes em termos de energia.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem GPU acessível e confiável para construir e escalar.
Leitura Recomendada



