

Alors que les grands modèles de langage continuent de dépasser les 70 milliards de paramètres, la demande en GPU capables de gérer des charges de travail d’IA limitées par la mémoire n’a jamais été aussi forte. Voici le NVIDIA H200 — un accélérateur de nouvelle génération conçu pour repousser les limites de l’IA générative, du calcul scientifique et de la visualisation en temps réel.
Équipé de la mémoire HBM3e, des performances FP8 Tensor Core et de la prise en charge multi-modèles MIG, le H200 promet de réduire le nombre de GPU nécessaires pour des charges de travail massives tout en accélérant l’entraînement et l’inférence comme jamais auparavant. Mais la question est : ce monstre de puissance est-il fait pour vous ?
Cet article détaille ce que le H200 fait de mieux, quels modèles il peut supporter, dans quels cas il est pertinent — et quand il est préférable d’économiser de l’argent avec des alternatives plus intelligentes comme le RTX 4090 ou des plateformes cloud comme Novita AI.
Qu’est-ce que le H200 ?
NVIDIA présente le H200 comme une avancée majeure par rapport au H100, spécialement conçu pour les tâches les plus exigeantes d’IA générative et de calcul haute performance (HPC) — en particulier celles limitées par la mémoire. Au cœur de cette mise à niveau se trouve le lancement de la mémoire HBM3e, offrant jusqu’à 1,8× la capacité et environ 1,4× la bande passante par rapport à son prédécesseur. Cela signifie qu’il faut moins de GPU pour exécuter efficacement des modèles massifs. Le H200 est adapté aux plateformes cloud hyperscale, aux laboratoires de recherche avancés et aux entreprises qui travaillent avec des LLM à grande échelle ou des simulations de haute précision.

| Métrique | H200 SXM | H200 NVL |
|---|---|---|
| Mémoire | 141 Go @ 4,8 To/s | 141 Go @ 4,8 To/s |
| Cœurs CUDA | 16 896 | 16 896 |
| Tensor Cores (gen 4) | FP8 3,96 PFLOPS ; FP16 1,98 PFLOPS ; TF32 0,99 PFLOPS | FP8 3,34 PFLOPS ; FP16 1,67 PFLOPS ; TF32 0,84 PFLOPS |
| RT Cores | 142 | 142 |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| FP64 / FP64 Tensor | 34 / 67 TFLOPS | 30 / 60 TFLOPS |
| Tranches MIG | 7 × 18 Go | 7 × 16,5 Go |
| TDP | Jusqu’à 700 W | Jusqu’à 600 W |
| Interconnexion | NVIDIA NVLink™ : 900 Go/s PCIe Gen5 : 128 Go/s |
Pont NVIDIA NVLink 2 ou 4 voies : 900 Go/s par GPU PCIe Gen5 : 128 Go/s |
| Calcul confidentiel | Pris en charge | Pris en charge |
Quels LLM peuvent être exécutés sur H200 en 2025 ?
| Modèle (2025) | Paramètres | Besoin en VRAM* | Tient sur 1 × H200 ? | Remarques |
|---|---|---|---|---|
| Llama 3.3 70B | 70 B dense | 70 Go (FP8) | ✔ | Le FP16 nécessite 2 GPU. |
| Qwen 2.5 72B | 72 B dense | 72 Go (FP8) | ✔ | Limite mais fonctionne. |
| Tout modèle dense ≤ 70 B | — | ≤ 70 Go (FP8) | ✔ | Plafond pratique pour une seule carte. |
| Petits modèles ≤ 30 B | — | ≤ 60 Go (FP16) | ✔ (mais gaspillage) | Mieux sur des GPU moins chers. |
Avec des poids en FP8, un modèle dense de 140 B est le maximum théorique sur un seul GPU avant de dépasser 141 Go. Les architectures MoE peuvent dépasser un billion de paramètres car seul un sous-ensemble est actif à chaque jeton.
Coût et consommation électrique du H200
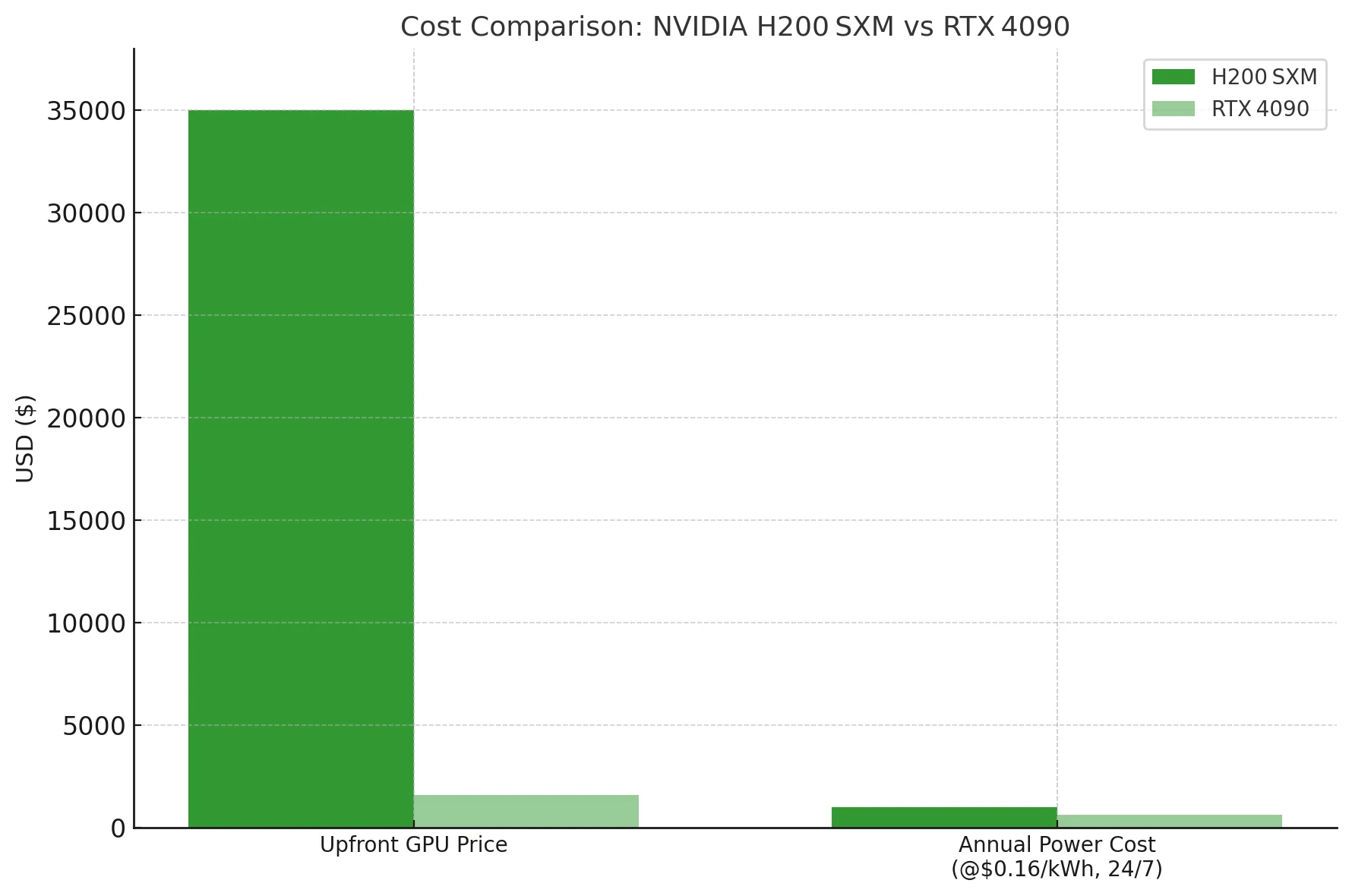
Sauf si vous devez absolument faire tenir un LLM dense de 70 B ou plus sur une seule carte, le 4090 offre un rapport coût-par-jeton bien meilleur de plusieurs ordres de grandeur — même avant l’électricité. Le H200 est un marteau-pilon de centre de données ; le 4090 est un maillet économique.
Cas d’utilisation réels du NVIDIA H200
Entraînement et inférence IA
Grâce à son débit élevé en FP8 et TF32 Tensor Core, le H200 accélère significativement l’entraînement et l’inférence — en particulier pour les tâches limitées par la mémoire comme les mécanismes d’attention dans les grands modèles de langage (LLM). Comparé au H100, il termine les époques plus rapidement et offre des réponses à latence réduite.
De plus, grâce au support Multi-Instance GPU (MIG), la même carte peut être partitionnée pour exécuter plusieurs modèles de taille moyenne simultanément, améliorant ainsi l’efficacité des ressources pendant les périodes d’inactivité.
Graphisme et visualisation
Équipé de 142 RT Cores, le H200 permet la visualisation scientifique avec lancer de rayons en temps réel, ce qui le rend viable pour des charges de travail de rendu avancées dans la recherche et l’ingénierie.
HPC de précision
Avec jusqu’à 34 TFLOPS de performances FP64 (variante SXM), le H200 alimente des simulations exigeantes dans des domaines comme la dynamique des fluides computationnelle (CFD), la modélisation climatique et la finance quantitative. Mieux encore, il prend en charge l’intégration de modèles d’IA de substitution au sein du même système, fusionnant simulation traditionnelle et IA moderne.
Quand le H200 a-t-il du sens ?
| ✅ Bon choix | ❌ Pas idéal |
|---|---|
| Entraînement de modèles de type GPT (≥100B) avec des délais serrés | Exécution de modèles <30B pour chatbots ou RAG — excessif en puissance et en coût |
| Inférence de modèles denses 70B+ avec des objectifs de latence <10ms | Déploiements périphériques ou de bureau sans refroidissement ni alimentation robustes |
| Charges de travail HPC en double précision avec de grands besoins mémoire pour intégration IA | Rendu graphique pur — les GPU RTX ou Quadro sont plus économiques |
H200 vs autres GPU
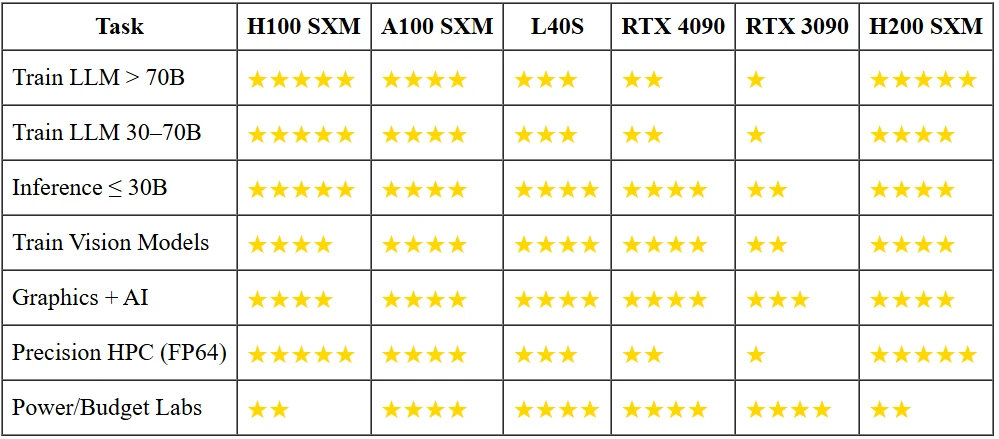
Pourquoi les petits modèles n’ont pas besoin des gros canons ?
Exécuter un chatbot de 13B paramètres en 16 bits nécessite <30 Go de VRAM. Cela tient déjà sur un RTX 3090 pour un tiers de la puissance d’un H100, et un 4090 servira cinq fois plus de tokens par seconde pour un dixième du prix d’achat. Sauf si vous devez faire tenir un modèle 70B avec une latence de quelques millisecondes ou l’entraîner de zéro, les accélérateurs phares sont des marteaux en or pour des clous de la taille d’une cacahuète.
Comment choisir un GPU adapté à très bas prix ?
Novita AI propose une plateforme cloud avec des instances GPU haute performance. Grâce à des GPU puissants, elle garantit des performances efficaces pour les tâches complexes, améliore l’accessibilité pour le déploiement sur divers matériels et offre une solution rentable par rapport au maintien d’un matériel local pour les déploiements IA à grande échelle.
Étape 1 : Créer un compte
Créez votre compte Novita AI via notre site web. Après inscription, naviguez vers la section “Explorer” dans la barre latérale gauche pour voir nos offres GPU et commencer votre parcours de développement IA.

Étape 2 : Explorer les modèles et les serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA correspondant à vos besoins de projet. Sélectionnez ensuite votre configuration GPU préférée — les options incluent les puissants L40S, RTX 4090, H200 ou A100 SXM4, chacun avec des spécifications différentes de VRAM, RAM et stockage.
Étape 3 : Personnaliser votre déploiement
Personnalisez votre environnement en choisissant votre système d’exploitation et vos options de configuration pour garantir des performances optimales pour vos charges de travail IA spécifiques et vos besoins de développement.

Étape 4 : Lancer une instance
Sélectionnez “Lancer l’instance” pour démarrer votre déploiement. Votre environnement GPU haute performance sera prêt en quelques minutes, vous permettant de commencer immédiatement vos projets d’apprentissage automatique, de rendu ou de calcul.

Le NVIDIA H200 est une mise à niveau puissante par rapport au H100, spécialement conçu pour l’entraînement IA à grande échelle, l’inférence et les charges de travail HPC de précision. Avec la mémoire HBM3e de pointe, des performances FP8 exceptionnelles et le support MIG, il excelle dans l’exécution de LLM denses de 70B+ ou dans la fusion de l’IA avec la simulation traditionnelle.
Cependant, pour des modèles plus petits ou des tâches moins intensives, des GPU plus abordables comme le RTX 4090 offrent une bien meilleure efficacité en termes de coût. Si vous n’êtes pas contraint par des cas d’utilisation gourmands en mémoire, envisagez une configuration plus légère — ou explorez des plateformes cloud comme Novita AI pour accéder à la puissance de niveau H200 sans le coût d’infrastructure.
Foire aux questions
À quoi sert le H200 ?
Il est idéal pour entraîner ou servir des LLM volumineux (70B+), l’inférence IA en temps réel, la visualisation scientifique avec lancer de rayons et les simulations HPC lourdes en FP64.
Puis-je exécuter un modèle 70B sur un seul H200 ?
Oui, si vous utilisez la quantification FP8. Mais au-delà de 70B (dense), un fractionnement du modèle ou plusieurs GPU peuvent être nécessaires.
Le H200 est-il excessif pour les petits modèles ?
Oui. Un modèle 13B tient facilement sur des GPU comme le RTX 3090 ou 4090, qui sont beaucoup moins chers et plus économes en énergie.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Lectures recommandées



