

隨著大型語言模型持續突破 700 億個參數,對能處理記憶體密集型 AI 工作負載的 GPU 需求從未如此之高。NVIDIA H200 應運而生——這款次世代加速器專為突破生成式 AI、科學運算與即時視覺化的極限而設計。
搭載 **HBM3e 記憶體 **、**FP8 Tensor Core 效能 ** 以及 MIG 多模型支援,H200 承諾能減少執行大規模工作負載所需的 GPU 數量,同時以前所未有的速度加速訓練與推論。但問題來了:這款猛獸真的適合你嗎?
本文將剖析 H200 的最佳應用場景、可支援的模型、何時選用合理——以及何時該用更聰明的替代方案(如 RTX 4090 或 Novita AI 這類雲端平台)來省錢。
H200 是什麼?
NVIDIA 推出的 H200 是 H100 的重大升級,專為最嚴苛的生成式 AI 與高效能運算(HPC)任務打造——尤其是那些受記憶體瓶頸所困的任務。本次升級的核心是首度導入 HBM3e 記憶體,容量提升至前代的 1.8 倍,頻寬約提升 1.4 倍。這代表可用更少的 GPU 有效率地執行大型模型。H200 專為超大規模雲端平台、先進研究實驗室以及處理大型 LLM 或高精度模擬的企業而設計。

| 指標 | H200 SXM | H200 NVL |
|---|---|---|
| 記憶體 | 141 GB @ 4.8 TB/s | 141 GB @ 4.8 TB/s |
| CUDA 核心數 | 16,896 | 16,896 |
| Tensor Core(第 4 代) | FP8 3.96 PFLOPS;FP16 1.98 PFLOPS;TF32 0.99 PFLOPS | FP8 3.34 PFLOPS;FP16 1.67 PFLOPS;TF32 0.84 PFLOPS |
| RT 核心 | 142 | 142 |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| FP64 / FP64 Tensor | 34 / 67 TFLOPS | 30 / 60 TFLOPS |
| MIG 分片 | 7 × 18 GB | 7 × 16.5 GB |
| TDP | 最高 700 W | 最高 600 W |
| 互連 | NVIDIA NVLink™:900GB/s PCIe Gen5:128GB/s |
2 路或 4 路 NVIDIA NVLink 橋接器: 每 GPU 900GB/s PCIe Gen5:128GB/s |
| 機密運算 | 支援 | 支援 |
2025 年 H200 可執行哪些 LLM?
| 模型(2025) | 參數量 | 所需 VRAM* | 單張 H200 可容納? | 備註 |
|---|---|---|---|---|
| Llama 3.3 70B | 700 億密集 | 70 GB(FP8) | ✔ | FP16 需要 2 張 GPU。 |
| Qwen 2.5 72B | 720 億密集 | 72 GB(FP8) | ✔ | 緊繃但可行。 |
| 任何 ≤ 700 億的密集模型 | — | ≤ 70 GB(FP8) | ✔ | 實務上的單卡上限。 |
| 小模型 ≤ 300 億 | — | ≤ 60 GB(FP16) | ✔(但浪費) | 更適合用便宜 GPU。 |
使用 FP8 權重時,密集 1400 億 模型是單張 GPU 理論上的最大容量(不超過 141 GB)。MoE 架構則可輕鬆突破一兆個參數,因為每次 token 只啟用部分子模型。
H200 成本與功耗考量
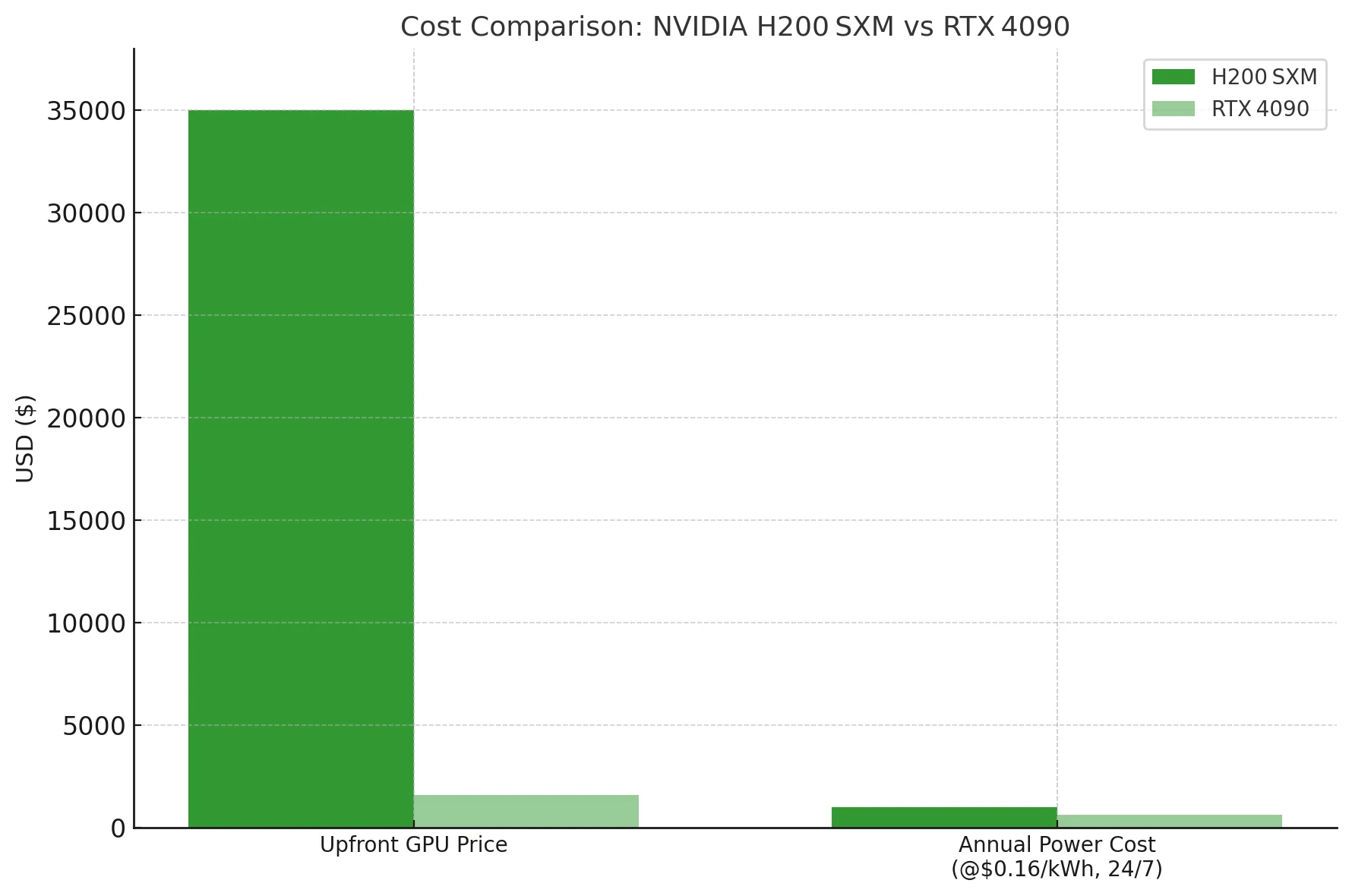
除非你非得把 70B 密集 LLM(或更大)塞進單張顯示卡,否則 4090 在每個 token 的成本上表現好上好幾個數量級——甚至還沒算電費。H200 是資料中心的巨錘;4090 則是預算友善的木槌。
NVIDIA H200 的實際應用場景
AI 訓練與推論
得益於高 FP8 與 TF32 Tensor Core 吞吐量,H200 能大幅加快訓練與推論——尤其是大型語言模型中注意力機制這類記憶體密集型任務。與 H100 相比,它能在更短時間內完成 epoch,並提供更低延遲的提示回應。
此外,借助多實例 GPU(MIG)支援,同一張卡可分割為數個部分,同時執行多箇中型模型,在閒置時提升資源效率。
圖形與視覺化
配備 142 個 RT 核心,H200 能實現即時光線追蹤科學視覺化,適合研究與工程領域的高階渲染工作負載。
高精度 HPC
SXM 版本提供高達 34 TFLOPS 的 FP64 效能,可驅動計算流體力學(CFD)、氣候模擬與量化金融等領域的嚴苛模擬。更重要的是,它支援在同一系統中整合 AI 代理模型,融合傳統模擬與現代 AI。
何時該選 H200?
| ✅ **非常適合 ** | ❌ ** 不適合** |
|---|---|
| 在緊湊時程下訓練 GPT 等級模型(≥1000 億參數) | 執行對話機器人或 RAG 用的 <300 億模型——效能與成本都過高 |
| 以次 10 毫秒延遲目標進行 700 億以上密集模型的推論 | 邊緣或辦公室部署,缺乏完善散熱與電力 |
| 需要大容量記憶體並整合 AI 的雙精度 HPC 工作負載 | 純圖形渲染——RTX 或 Quadro GPU 更具經濟效益 |
H200 與其他 GPU 比較
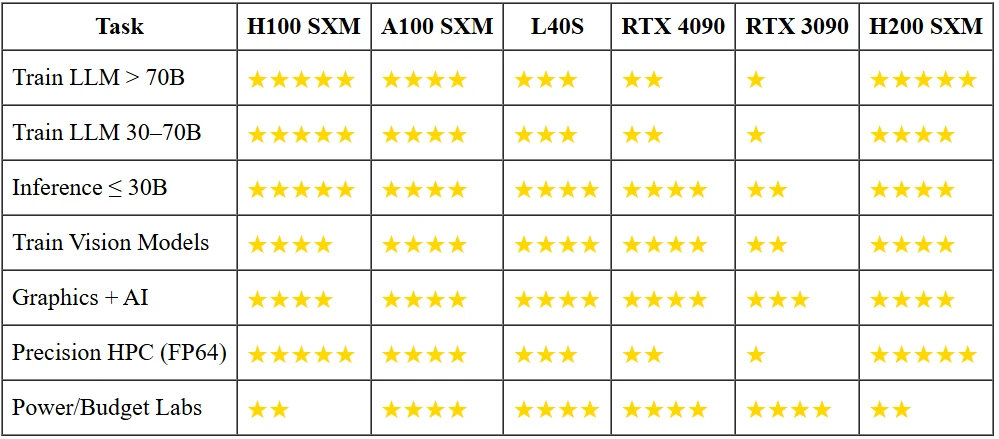
為何小模型不需要大砲?
以 16 位元執行一個 130 億參數的對話機器人只需 <30 GB 的 VRAM。這已經能裝進 3090(功耗僅 H100 的三分之一),而 4090 每秒可處理五倍以上的 token,購買價格卻只有十分之一。除非你必須將 700 億模型壓在個位數毫秒延遲內,或從頭開始訓練它,否則旗艦加速器就像金錘子來釘花生大小的釘子。
如何以極低價格選出適合的 GPU?
Novita AI 提供基於雲端的高效能 GPU 實例平台。憑藉強大的 GPU,能確保複雜任務的高效表現,提升跨不同硬體的部署便利性,且相較於自行維護本地硬體進行大規模 AI 部署,更具成本效益。
第一步:註冊帳號
前往官網建立您的 Novita AI 帳號。註冊完成後,點選左側邊欄的「Explore」查看我們提供的 GPU 方案,開始您的 AI 開發旅程。

第二步:探索範本與 GPU 伺服器
從 PyTorch、TensorFlow 或 CUDA 等範本中選擇符合專案需求的項目。接著挑選偏好的 GPU 配置——選項包括強大的 L40S、RTX 4090、H200 或 A100 SXM4,各有不同的 VRAM、RAM 與儲存規格。
第三步:量身打造部署
透過選擇偏好的作業系統與配置選項來自訂環境,確保滿足特定 AI 工作負載與開發需求的最佳效能。

第四步:啟動實例
點選「Launch Instance」開始部署。數分鐘內即可準備好高效能 GPU 環境,讓您立即投入機器學習、渲染或運算專案。

NVIDIA H200 是 H100 的強力升級,專為大規模 AI 訓練、推論與高精度 HPC 工作負載所設計。搭載尖端 HBM3e 記憶體、卓越的 FP8 效能與 MIG 支援,在執行密集 700 億以上 LLM 或結合 AI 與傳統模擬方面表現出色。
然而,對於較小模型或較不密集的任務,像是 RTX 4090 這類更實惠的 GPU 能提供遠優於成本效率。如果您沒有受記憶體限制的應用需求,請考慮更精簡的配置——或探索像 Novita AI 這樣的雲端平台,以較低的基礎設施成本取得 H200 等級的運算力。
常見問題
H200 的用途是什麼?
它非常適合訓練或服務大型(700 億以上)LLM、即時 AI 推論、光線追蹤科學視覺化,以及 FP64 密集型 HPC 模擬。
能否在單張 H200 上執行 700 億參數模型?
可以,如果使用 FP8 量化。但任何超過 700 億(密集)的模型可能需要模型分割或多張 GPU。
H200 對小模型來說是殺雞用牛刀嗎?
是的。130 億模型很容易裝進像是 RTX 3090 或 4090 這類 GPU,它們便宜得多且更省電。
Novita AI 是一個 AI 雲端平台,為開發者提供使用簡單 API 部署 AI 模型的便捷方式,同時提供價格合理且可靠的 GPU 雲端,用於建構與擴展模型。
推薦閱讀



