

A medida que los modelos de lenguaje grandes siguen escalando más allá de los 70 mil millones de parámetros, la demanda de GPUs que puedan manejar cargas de trabajo de IA limitadas por memoria nunca ha sido mayor. Presentamos la NVIDIA H200—un acelerador de próxima generación construido para ampliar los límites de la IA generativa, la computación científica y la visualización en tiempo real.
Equipada con memoria HBM3e, rendimiento FP8 Tensor Core y soporte multi-modelo MIG, la H200 promete reducir la cantidad de GPUs necesarias para cargas de trabajo masivas mientras acelera el entrenamiento y la inferencia como nunca antes. Pero aquí está la pregunta: ¿Es esta potencia adecuada para ti?
Este artículo desglosa lo que la H200 hace mejor, qué modelos puede soportar, cuándo tiene sentido—y cuándo es mejor ahorrar dinero con alternativas más inteligentes como la RTX 4090 o plataformas en la nube como Novita AI.
¿Qué es la H200?
NVIDIA presenta la H200 como un gran paso más allá de la H100, diseñada a propósito para las tareas más exigentes de IA generativa y computación de alto rendimiento (HPC)—especialmente aquellas limitadas por la memoria. En el corazón de esta actualización está el debut de la memoria HBM3e, que ofrece hasta 1.8× más capacidad y aproximadamente 1.4× mayor ancho de banda en comparación con su predecesora. Esto significa que se necesitan menos GPUs para ejecutar modelos masivos de manera eficiente. La H200 está diseñada para plataformas en la nube a hiperescala, laboratorios de investigación avanzados y empresas que abordan LLMs a gran escala o simulaciones de alta precisión.

| Métrica | H200 SXM | H200 NVL |
|---|---|---|
| Memoria | 141 GB @ 4.8 TB/s | 141 GB @ 4.8 TB/s |
| Núcleos CUDA | 16 896 | 16 896 |
| Núcleos Tensor (gen 4) | FP8 3.96 PFLOPS; FP16 1.98 PFLOPS; TF32 0.99 PFLOPS | FP8 3.34 PFLOPS; FP16 1.67 PFLOPS; TF32 0.84 PFLOPS |
| Núcleos RT | 142 | 142 |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| FP64 / Tensor FP64 | 34 / 67 TFLOPS | 30 / 60 TFLOPS |
| Slices MIG | 7 × 18 GB | 7 × 16.5 GB |
| TDP | Hasta 700 W | Hasta 600 W |
| Interconexión | NVIDIA NVLink™: 900 GB/s PCIe Gen5: 128 GB/s |
Puente NVIDIA NVLink de 2 o 4 vías: 900 GB/s por GPU PCIe Gen5: 128 GB/s |
| Computación confidencial | Soportada | Soportada |
¿Qué LLM se puede ejecutar en la H200 en 2025?
| Modelo (2025) | Parámetros | Necesidad de VRAM* | ¿Cabe en 1 × H200? | Notas |
|---|---|---|---|---|
| Llama 3.3 70B | 70 B denso | 70 GB (FP8) | ✔ | FP16 necesita 2 GPUs. |
| Qwen 2.5 72B | 72 B denso | 72 GB (FP8) | ✔ | Ajustado pero funciona. |
| Cualquier modelo denso ≤ 70 B | — | ≤ 70 GB (FP8) | ✔ | Techo práctico de una sola tarjeta. |
| Modelos pequeños ≤ 30 B | — | ≤ 60 GB (FP16) | ✔ (pero derrochador) | Mejor en GPUs más baratas. |
Con pesos FP8, un modelo denso de 140 B es el máximo teórico de una sola GPU antes de superar los 141 GB. Las arquitecturas MoE pueden superar el billón de parámetros porque solo un subconjunto está activo por token.
Consideraciones de costo y energía de la H200
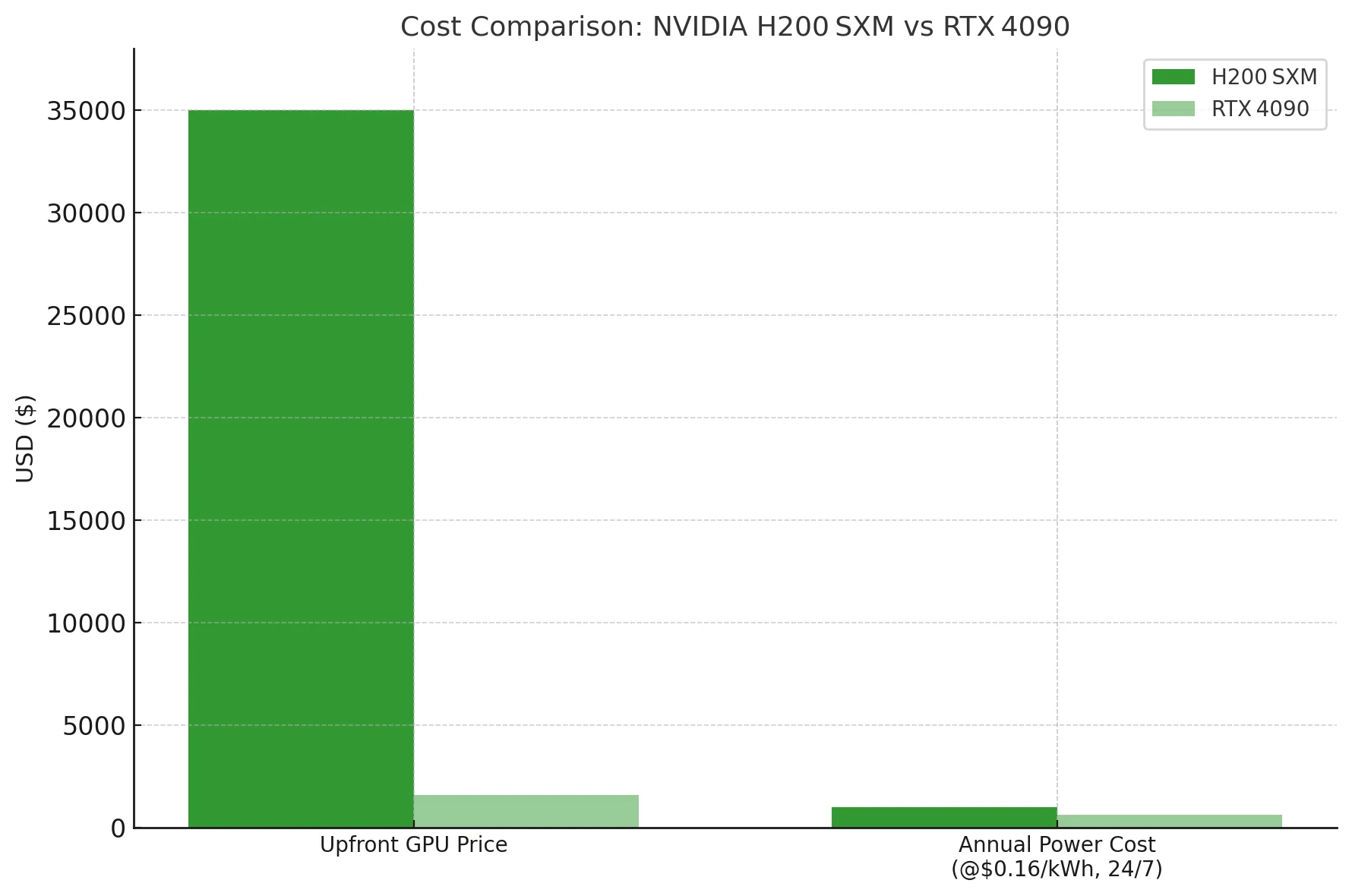
A menos que debas encajar un LLM denso de 70 B o más grande en una sola tarjeta, la 4090 ofrece un costo por token órdenes de magnitud mejor—incluso antes de la electricidad. La H200 es un martillo neumático de centro de datos; la 4090 es un mazo económico.
Casos de uso reales de la NVIDIA H200
Entrenamiento e inferencia de IA
Gracias a su alto rendimiento FP8 y TF32 Tensor Core, la H200 acelera significativamente el entrenamiento y la inferencia—especialmente para tareas limitadas por memoria como los mecanismos de atención en modelos de lenguaje grandes (LLMs). En comparación con la H100, completa épocas más rápido y ofrece respuestas de prompt con menor latencia.
Además, con soporte Multi-Instance GPU (MIG), la misma tarjeta se puede dividir para ejecutar varios modelos de tamaño mediano simultáneamente, mejorando la eficiencia de recursos durante períodos de inactividad.
Gráficos y visualización
Equipada con 142 núcleos RT, la H200 permite la visualización científica con trazado de rayos en tiempo real, haciéndola viable para cargas de trabajo de renderizado avanzado en investigación e ingeniería.
HPC de precisión
Con hasta 34 TFLOPS de rendimiento FP64 (variante SXM), la H200 impulsa simulaciones exigentes en campos como la dinámica de fluidos computacional (CFD), el modelado climático y las finanzas cuantitativas. Aún mejor, admite la integración de modelos sustitutos de IA dentro del mismo sistema, combinando simulación tradicional e IA moderna.
¿Cuándo tiene sentido la H200?
| ✅ Gran ajuste | ❌ No es ideal |
|---|---|
| Entrenar modelos tipo GPT (≥100B) con plazos ajustados | Ejecutar modelos <30B para chatbots o RAG—excesivo en potencia y costo |
| Inferencia de modelos densos de 70B+ con objetivos de latencia por debajo de 10ms | Implementaciones en edge/oficina que carecen de refrigeración y energía robustas |
| Cargas de trabajo HPC de doble precisión con grandes necesidades de memoria para integración de IA | Renderizado gráfico puro—las GPUs RTX o Quadro son más económicas |
H200 vs otras GPUs
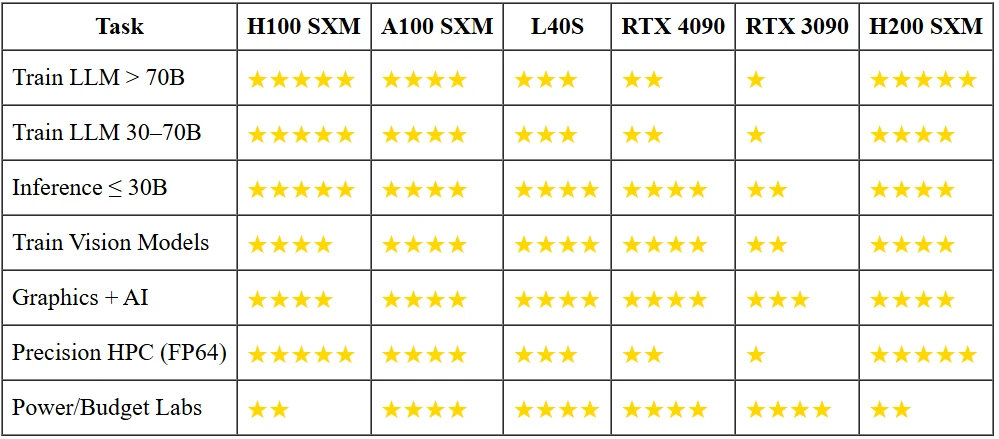
¿Por qué los modelos pequeños no necesitan las armas grandes?
Ejecutar un chatbot de 13B parámetros en 16 bits ocupa <30 GB de VRAM. Eso ya cabe en una RTX 3090 con un tercio de la potencia de una H100, y una 4090 servirá cinco veces más tokens por segundo por una décima parte del precio de compra. A menos que debas meter un modelo de 70B con latencia de un solo dígito o entrenarlo desde cero, los aceleradores insignia son martillos bañados en oro para clavos del tamaño de un maní.
Cómo elegir una GPU adecuada a un precio muy bajo?
Novita AI proporciona una plataforma basada en la nube con instancias GPU de alto rendimiento. Con potentes GPUs, garantiza un rendimiento eficiente para tareas complejas, mejora la accesibilidad para la implementación en diversos hardware y ofrece una solución rentable en comparación con el mantenimiento de hardware local para implementaciones de IA a gran escala.
Paso 1: Registra una cuenta
Crea tu cuenta de Novita AI a través de nuestro sitio web. Después del registro, navega a la sección “Explore” en la barra lateral izquierda para ver nuestras ofertas de GPU y comenzar tu viaje de desarrollo de IA.

Paso 2: Explora plantillas y servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se adapten a las necesidades de tu proyecto. Luego selecciona tu configuración de GPU preferida—las opciones incluyen la potente L40S, RTX 4090, H200 o A100 SXM4, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.
Paso 3: Personaliza tu implementación
Personaliza tu entorno seleccionando tu sistema operativo preferido y opciones de configuración para garantizar un rendimiento óptimo para tus cargas de trabajo de IA y necesidades de desarrollo específicas.

Paso 4: Lanza una instancia
Selecciona “Launch Instance” para iniciar tu implementación. Tu entorno GPU de alto rendimiento estará listo en minutos, permitiéndote comenzar de inmediato tus proyectos de machine learning, renderizado o computación.

La NVIDIA H200 es una actualización potente sobre la H100, diseñada a propósito para entrenamiento, inferencia y cargas de trabajo HPC de precisión a gran escala. Con memoria HBM3e de vanguardia, rendimiento FP8 excepcional y soporte MIG, sobresale en la ejecución de LLMs densos de 70B+ o en la combinación de IA con simulación tradicional.
Sin embargo, para modelos más pequeños o tareas menos intensivas, GPUs más asequibles como la RTX 4090 ofrecen una eficiencia de costo mucho mejor. Si no estás limitado por casos de uso intensivos en memoria, considera una configuración más ligera—o explora plataformas en la nube como Novita AI para acceder a potencia de nivel H200 sin el costo de infraestructura.
Preguntas frecuentes
¿Para qué se usa la H200?
Es ideal para entrenar o servir LLMs grandes (70B+), inferencia de IA en tiempo real, visualización científica con trazado de rayos y simulaciones HPC pesadas en FP64.
¿Puedo ejecutar un modelo de 70B en una sola H200?
Sí, si usas cuantificación FP8. Pero cualquier cosa más allá de 70B (denso) puede requerir división del modelo o múltiples GPUs.
¿Es la H200 un exceso para modelos pequeños?
Sí. Un modelo de 13B cabe fácilmente en GPUs como la RTX 3090 o 4090, que son mucho más baratas y eficientes energéticamente.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, al mismo tiempo que proporciona la nube GPU asequible y confiable para construir y escalar.
Lectura recomendada



