

Da große Sprachmodelle weiterhin die 70-Milliarden-Parameter-Marke überschreiten, ist die Nachfrage nach GPUs, die speicherintensive KI-Workloads bewältigen können, größer denn je. Hier kommt die NVIDIA H200 ins Spiel – ein Next-Gen-Beschleuniger, der die Grenzen von generativer KI, wissenschaftlichem Rechnen und Echtzeitvisualisierung verschiebt.
Ausgestattet mit HBM3e-Speicher, FP8-Tensor-Core-Leistung und MIG-Multimodell-Unterstützung verspricht die H200, die Anzahl der benötigten GPUs für massive Workloads zu reduzieren und gleichzeitig Training und Inferenz wie nie zuvor zu beschleunigen. Aber hier ist die Frage: Ist dieses Kraftpaket das Richtige für Sie?
Dieser Artikel zeigt auf, was die H200 am besten kann, welche Modelle sie unterstützt, wann sie sinnvoll ist – und wann Sie mit intelligenteren Alternativen wie der RTX 4090 oder Cloud-Plattformen wie Novita AI besser sparen.
Was ist die H200?
NVIDIA stellt die H200 als großen Schritt über die H100 hinaus vor, speziell optimiert für die anspruchsvollsten Aufgaben der generativen KI und des High-Performance-Computing (HPC) – insbesondere solche, die durch den Speicher begrenzt werden. Im Kern dieses Upgrades steht der Debüt des HBM3e-Speichers, der bis zu 1,8× mehr Kapazität und etwa 1,4× höhere Bandbreite im Vergleich zum Vorgänger bietet. Das bedeutet, dass weniger GPUs benötigt werden, um große Modelle effizient auszuführen. Die H200 ist für Hyperscale-Cloud-Plattformen, fortschrittliche Forschungslabore und Unternehmen zugeschnitten, die groß angelegte LLMs oder präzisionsintensive Simulationen bewältigen.

| Metrik | H200 SXM | H200 NVL |
|---|---|---|
| Speicher | 141 GB @ 4,8 TB/s | 141 GB @ 4,8 TB/s |
| CUDA Cores | 16 896 | 16 896 |
| Tensor Cores (Gen 4) | FP8 3,96 PFLOPS; FP16 1,98 PFLOPS; TF32 0,99 PFLOPS | FP8 3,34 PFLOPS; FP16 1,67 PFLOPS; TF32 0,84 PFLOPS |
| RT Cores | 142 | 142 |
| FP32 | 67 TFLOPS | 60 TFLOPS |
| FP64 / FP64 Tensor | 34 / 67 TFLOPS | 30 / 60 TFLOPS |
| MIG Slices | 7 × 18 GB | 7 × 16,5 GB |
| TDP | Bis zu 700 W | Bis zu 600 W |
| Interconnect | NVIDIA NVLink™: 900GB/s PCIe Gen5: 128GB/s |
2- oder 4-Wege-NVIDIA-NVLink-Bridge: 900GB/s pro GPU PCIe Gen5: 128GB/s |
| Vertrauliches Rechnen | Unterstützt | Unterstützt |
Welches LLM kann 2025 auf der H200 ausgeführt werden?
| Modell (2025) | Parameter | VRAM-Bedarf* | Passt auf 1 × H200? | Anmerkungen |
|---|---|---|---|---|
| Llama 3.3 70B | 70 B dicht | 70 GB (FP8) | ✔ | FP16 benötigt 2 GPUs. |
| Qwen 2.5 72B | 72 B dicht | 72 GB (FP8) | ✔ | knapp, aber es funktioniert. |
| Beliebiges dichtes Modell ≤ 70 B | — | ≤ 70 GB (FP8) | ✔ | Praktische Obergrenze für eine einzelne Karte. |
| Kleine Modelle ≤ 30 B | — | ≤ 60 GB (FP16) | ✔ (aber verschwenderisch) | Besser auf günstigeren GPUs. |
Mit FP8-Gewichten ist ein dichtes 140 B-Modell das theoretische Maximum auf einer einzelnen GPU, bevor 141 GB überschritten werden. MoE-Architekturen können weit über eine Billion Parameter hinausgehen, da pro Token nur eine Teilmenge aktiv ist.
Kosten- und Stromverbrauch der H200
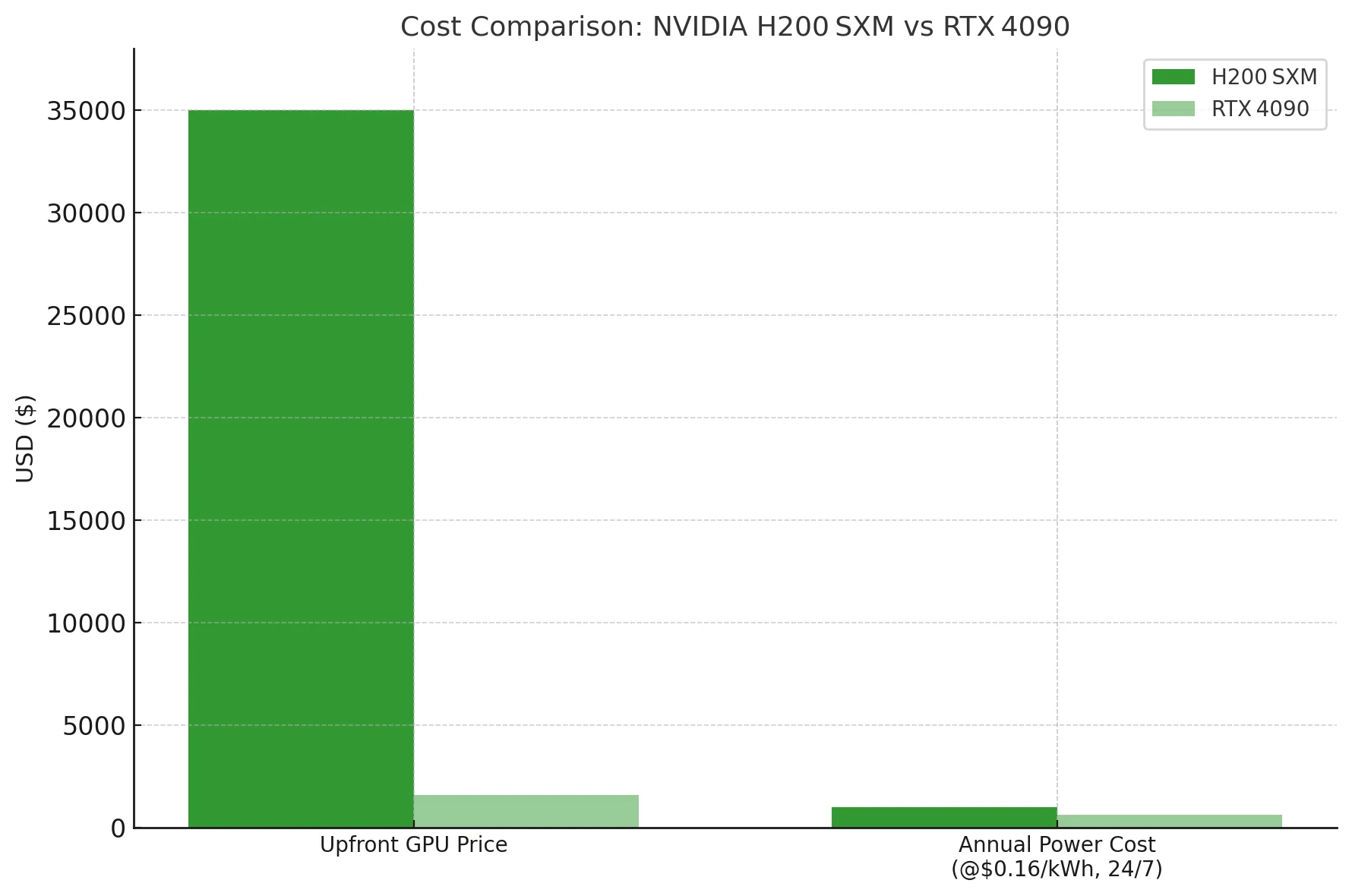
Wenn Sie nicht unbedingt ein dichtes 70 B LLM oder größeres auf einer einzelnen Karte unterbringen müssen, liefert die 4090 eine um Größenordnungen bessere Kosten-pro-Token-Effizienz – selbst vor dem Stromverbrauch. Die H200 ist ein Vorschlaghammer für Rechenzentren; die 4090 ist ein budgetfreundlicher Hammer.
Anwendungsfälle für die NVIDIA H200 in der Praxis
KI-Training & Inferenz
Dank ihres hohen FP8- und TF32-Tensor-Core-Durchsatzes beschleunigt die H200 Training und Inferenz erheblich – besonders bei speichergebundenen Aufgaben wie Aufmerksamkeitsmechanismen in großen Sprachmodellen (LLMs). Im Vergleich zur H100 schließt sie Epochen schneller ab und liefert Prompt-Antworten mit geringerer Latenz.
Darüber hinaus kann dieselbe Karte mit Unterstützung für Multi-Instance GPU (MIG) partitioniert werden, um mehrere mittelgroße Modelle gleichzeitig auszuführen, was die Ressourceneffizienz in Leerlaufzeiten verbessert.
Grafik & Visualisierung
Mit 142 RT Cores ermöglicht die H200 ray-getreue wissenschaftliche Visualisierung in Echtzeit und ist damit für anspruchsvolle Rendering-Workloads in Forschung und Technik geeignet.
Präzisions-HPC
Mit bis zu 34 TFLOPS FP64-Leistung (SXM-Variante) treibt die H200 anspruchsvolle Simulationen in Bereichen wie numerischer Strömungsmechanik (CFD), Klimamodellierung und quantitativer Finanzwelt an. Noch besser: Sie unterstützt die Integration von KI-Surrogatmodellen im selben System und verbindet traditionelle Simulation mit moderner KI.
Wann ist die H200 sinnvoll?
| ✅ Gut geeignet | ❌ Nicht ideal |
|---|---|
| Training von GPT-ähnlichen Modellen (≥100B) unter knappen Zeitvorgaben | Ausführung von <30B-Modellen für Chatbots oder RAG – überdimensioniert in Leistung und Kosten |
| Inferenz von 70B+ dichten Modellen mit Latenzzielen unter 10 ms | Edge-/Bürobereitstellungen ohne robuste Kühlung und Stromversorgung |
| Doppelt genaue HPC-Workloads mit großem Speicherbedarf für KI-Integration | Reine Grafik-Rendering – RTX- oder Quadro-GPUs sind wirtschaftlicher |
H200 im Vergleich zu anderen GPUs
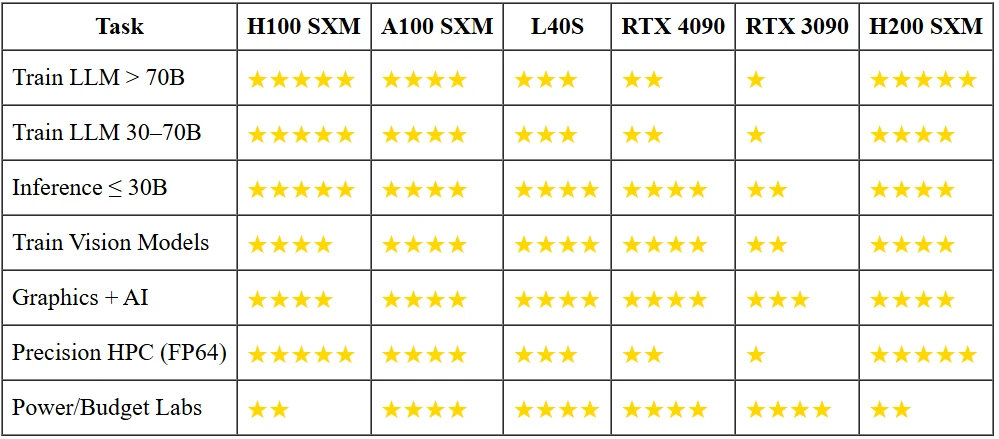
Warum kleine Modelle die großen Geschütze nicht brauchen?
Ein 13B-Parameter-Chatbot in 16-Bit benötigt <30 GB VRAM. Das passt bereits auf eine RTX 3090 bei einem Drittel des Stromverbrauchs einer H100, und eine 4090 liefert fünfmal so viele Tokens pro Sekunde zu einem Zehntel des Kaufpreises. Wenn Sie nicht unbedingt ein 70B-Modell mit einstelligen Millisekunden ausführen oder von Grund auf trainieren müssen, sind die Flaggschiff-Beschleuniger vergoldete Hämmer für erdnussgroße Nägel.
Wie wählt man eine geeignete GPU zu einem sehr niedrigen Preis aus?
Novita AI bietet eine cloudbasierte Plattform mit leistungsstarken GPU-Instanzen. Mit leistungsstarken GPUs gewährleistet sie eine effiziente Leistung für komplexe Aufgaben, verbessert die Zugänglichkeit für die Bereitstellung auf verschiedener Hardware und bietet eine kosteneffektive Lösung im Vergleich zur lokalen Wartung von Hardware für groß angelegte KI-Bereitstellungen.
Schritt 1: Registrieren Sie ein Konto
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Navigieren Sie nach der Registrierung zum Bereich “Explore” in der linken Seitenleiste, um unsere GPU-Angebote zu sehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die Ihren Projektanforderungen entsprechen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarke L40S, RTX 4090, H200 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Speicherspezifikationen.
Schritt 3: Ihre Bereitstellung anpassen
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten.

Schritt 4: Starten Sie eine Instanz
Wählen Sie “Launch Instance”, um Ihre Bereitstellung zu starten. Ihre leistungsstarke GPU-Umgebung ist innerhalb von Minuten bereit, sodass Sie sofort mit Ihren Machine-Learning-, Rendering- oder Rechenprojekten beginnen können.

Die NVIDIA H200 ist ein leistungsstarkes Upgrade gegenüber der H100, speziell entwickelt für groß angelegtes KI-Training, Inferenz und präzisionsorientierte HPC-Workloads. Mit modernstem HBM3e-Speicher, außergewöhnlicher FP8-Leistung und MIG-Unterstützung glänzt sie bei der Ausführung dichter 70B±LLMs oder der Kombination von KI mit traditionellen Simulationen.
Für kleinere Modelle oder weniger intensive Aufgaben bieten jedoch günstigere GPUs wie die RTX 4090 eine weitaus bessere Kosteneffizienz. Wenn Sie nicht an speicherintensive Anwendungsfälle gebunden sind, sollten Sie ein schlankeres Setup in Betracht ziehen – oder Cloud-Plattformen wie Novita AI erkunden, um H200-Klasse-Leistung ohne Infrastrukturkosten zu erhalten.
Häufig gestellte Fragen
Wofür wird die H200 verwendet?
Sie ist ideal für das Training oder den Betrieb großer (70B+) LLMs, Echtzeit-KI-Inferenz, ray-getreue wissenschaftliche Visualisierung und FP64-intensive HPC-Simulationen.
Kann ich ein 70B-Modell auf einer einzelnen H200 ausführen?
Ja, wenn Sie FP8-Quantisierung verwenden. Aber alles, was über 70B (dicht) hinausgeht, erfordert möglicherweise Modellaufteilung oder mehrere GPUs.
Ist die H200 für kleine Modelle übertrieben?
Ja. Ein 13B-Modell passt problemlos auf GPUs wie die RTX 3090 oder 4090, die viel günstiger und energieeffizienter sind.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig die erschwingliche und zuverlässige GPU-Cloud für den Aufbau und die Skalierung bereitstellt.
Empfohlene Lektüre



