

- Comparação das Variantes do Modelo MiniMax Speech 2.6
- Por Que o Speech 2.6 Finalmente Torna os Agentes de Voz em Tempo Real Viáveis?
- Quais Novas Capacidades Multilíngues o Speech 2.6 Torna Possíveis?
- Como o Speech 2.6 Aprimora a Clonagem de Voz Personalizada?
- Quais Novos Tipos de Dados Multimodais o Speech 2.6 Pode Ler Sem Pré-processamento?
- Qual Modelo de Voz os Desenvolvedores Devem Usar e Quando?
- Quão Granular é o Controle sobre Pronúncia, Ênfase e Pausas do Speech 2.6?
- O MiniMax Speech 2.6 Suporta Streaming?
- Como Usar o MiniMax Speech 2.5 por um Bom Preço?
O Speech 2.6 não é apenas um sucessor de qualidade superior ao 2.5; ele habilita classes inteiras de aplicações em tempo real, multimodais e orientadas a dados que o 2.5 não conseguia suportar de forma confiável.
Para desenvolvedores que selecionam um backend de agente de voz/TTS para produção, a pergunta crucial não é qual modelo “soa” melhor, mas qual expande o limite do que seu produto pode fazer. Este artigo enquadra ambos os modelos por meio de pontos de dor concretos de desenvolvedores — vozes personalizadas, agentes em tempo real, experiências multilíngues, conteúdo de longa duração, leitura de dados multimodais e controle de custos — e explica como o Speech 2.6 levanta vários tetos de aplicação.
Comparação das Variantes do Modelo MiniMax Speech 2.6
| Dimensão | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| Objetivo Principal | Baixa latência e eficiência de custos | Fidelidade e expressividade máximas |
| Latência Ponta a Ponta | < 250 ms para frases típicas | ~0,8–1,0 s para frases curtas |
| Throughput | Mais rápido que o tempo real para textos longos; otimizado para streaming | Throughput menor; otimizado para qualidade |
| Suporte a Streaming | Sim; primeiros tokens de áudio em poucas centenas de ms | Parcial; suporta tempo real para comprimento de entrada moderado |
| Qualidade de Prosódia | Prosódia padrão; prioriza velocidade | Prosódia aprimorada, microdetalhes, suporte a Fluent Emotion |
| Capacidade Multilíngue | Mais de 40 idiomas; troca sem interrupções | Mais de 40 idiomas com naturalidade aprimorada |
| Estilos de Emoção | Suportado (básico) | Suportado com maior expressividade |
| Precificação | $0,06 / 1.000 caracteres | $0,10 / 1.000 caracteres |
| Melhores Casos de Uso | Agentes interativos, chatbots, diálogo em streaming | Dublagens, audiolivros, narração de nível de estúdio |
Por Que o Speech 2.6 Finalmente Torna os Agentes de Voz em Tempo Real Viáveis?
A latência de menos de 250 ms do Speech 2.6 e o streaming estabilizado desbloqueiam fluxos de trabalho de interação de voz natural que o Speech 2.5 não consegue suportar.
A interação em tempo real é a maior lacuna entre o 2.5 e o 2.6. Desenvolvedores que criam bots de atendimento ao cliente, assistentes para lojas ou recursos de interface de usuário por voz frequentemente relatavam que a latência do Speech 2.5 — embora aceitável para TTS síncrono — parecia muito lenta para um diálogo verdadeiro.
O Speech 2.6 resolve isso redesenhando o pipeline de decodificação e o agendador de streaming, reduzindo o atraso de ida e volta para menos de 250 ms e tornando a troca de turnos quase instantânea da perspectiva do usuário. Essa alteração transforma o modelo de um gerador de conteúdo em uma camada de voz interativa adequada para agentes de produção. Os desenvolvedores não precisam mais contornar atrasos ou adicionar pausas artificiais; o modelo finalmente se encaixa no timing de conversação.
Experimente o MiniMax Speech 2.6 Agora!
Quais Novas Capacidades Multilíngues o Speech 2.6 Torna Possíveis?
O Speech 2.6 aprimora a prosódia entre idiomas, permitindo que agentes multilíngues troquem de idioma naturalmente em uma única fala.
Para aplicativos globais, os desenvolvedores precisam de precisão de pronúncia em misturas de chinês e inglês, mercados do Sudeste Asiático e fluxos de clientes multilíngues. O Speech 2.6 aprimora a prosódia interlíngue e mantém as vozes clonadas estáveis em mais de 40 idiomas.
| Recurso | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| Número de Idiomas | Mais de 40 | Mais de 40 |
| Troca de Código (Code-Switching) | Boa | Fluida e natural |
| Preservação de Sotaque | Estável | Mais estável entre idiomas |
| Leitura de Formato Misto | Limitada | Robusta, consciente de localidade |
Experimente o MiniMax Speech 2.6 Agora!
Como o Speech 2.6 Aprimora a Clonagem de Voz Personalizada?
O Speech 2.6 oferece vozes clonadas mais expressivas e emocionalmente coerentes, permitindo a propriedade de voz de marca e criador a longo prazo.
Desenvolvedores que criam influenciadores de IA, plataformas de aprendizado, agentes de interpretação de papéis ou avatares de marca precisam de identidades de voz consistentes e reutilizáveis. O Speech 2.5 introduziu a clonagem zero-shot usando um codificador de locutor aprendível, um marco importante para conteúdo personalizado.
Codificador de Locutor Treinado Conjuntamente
O codificador de locutor aprendível, treinado conjuntamente com o transformador principal, alcança fidelidade de clonagem de voz de última geração sem transcrições do áudio de referência. A exposição a múltiplos idiomas durante o treinamento permite timbre consistente, estabilidade de sotaque e comportamento multilíngue robusto.
Fluent LoRA para Adaptação Rápida de Voz
O Fluent LoRA fornece uma adaptação de baixo posto eficiente para personalização de voz refinada. Mesmo amostras de referência imperfeitas contendo desvios de sotaque ou ruído de fundo podem ser convertidas em vozes sintetizadas limpas e fluidas, permitindo implantação rápida em ambientes diversos.
Experimente o MiniMax Speech 2.6 Agora!
Quais Novos Tipos de Dados Multimodais o Speech 2.6 Pode Ler Sem Pré-processamento?
O Speech 2.6 introduz a formatação inteligente, permitindo que desenvolvedores insiram URLs brutas, e-mails, números, moedas e datas diretamente sem limpeza de expressões regulares.
Em aplicações reais — painéis, alertas, atualizações de CRM, notificações de logística, pipelines de RAG — o TTS geralmente precisa ler dados estruturados. O Speech 2.5 só consegue ler esse conteúdo literalmente, resultando em soletração letra por letra estranha ou pronúncia incorreta.
O Speech 2.6 inclui normalização de texto integrada que interpreta automaticamente URLs, números de telefone, endereços IP, moedas e formatos de data e hora. Isso reduz drasticamente o trabalho de pré-processamento e permite que desenvolvedores integrem o TTS diretamente em fluxos multimodais dinâmicos, como ler painéis de análise em voz alta ou emitir notificações de comércio eletrônico em várias localidades. Por exemplo, uma entrada de “$1,234.56” será falada como “one thousand two hundred thirty-four dollars and fifty-six cents” automaticamente, e um endereço IP como “192.168.1.1” se torna “one nine two dot one six eight dot one dot one” sem que você precise soletrá-lo. Isso aumenta significativamente a precisão em leituras técnicas ou financeiras e é uma força única do MiniMax Speech 2.6.
| Tipo de Dado | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URLs | Caracteres literais | Corretas, conscientes do contexto |
| E-mails | Frequentemente mal lidos | Naturais, conscientes de segmentos |
| Datas, Horários | Inconsistentes | Estáveis por localidade |
| Moedas / Números | Básico | Formatação numérica inteligente |
Experimente o MiniMax Speech 2.6 Agora!
Qual Modelo de Voz os Desenvolvedores Devem Usar e Quando?
O Speech 2.6 é Mais Adequado Para
- desenvolvedores que criam agentes de conversação em tempo real,
- aplicativos que exigem troca de código multilíngue,
- produtos que precisam de vozes clonadas expressivas,
- sistemas que leem dados multimodais estruturados (URLs, e-mails, números),
- fluxos de UX que exigem tom emocional semelhante ao humano.
O Speech 2.5 é Mais Adequado Para
- plataformas que geram TTS de longa duração em massa,
- conteúdo educacional, audiolivros, vídeos com roteiro,
- pipelines sensíveis a custos com volume previsível,
- saídas de voz estáveis onde a expressividade é menos crítica.
Padrão de desenvolvedor emergente em produção
- O Speech 2.6 lida com fluxos interativos, em tempo real, multilíngues ou ricos em dados.
- O Speech 2.5 lida com narração de longa duração, em lote ou em grande escala.
- As implantações mais robustas combinam ambos:
- Speech 2.6 para diálogo ao vivo
- Speech 2.5 para geração de conteúdo
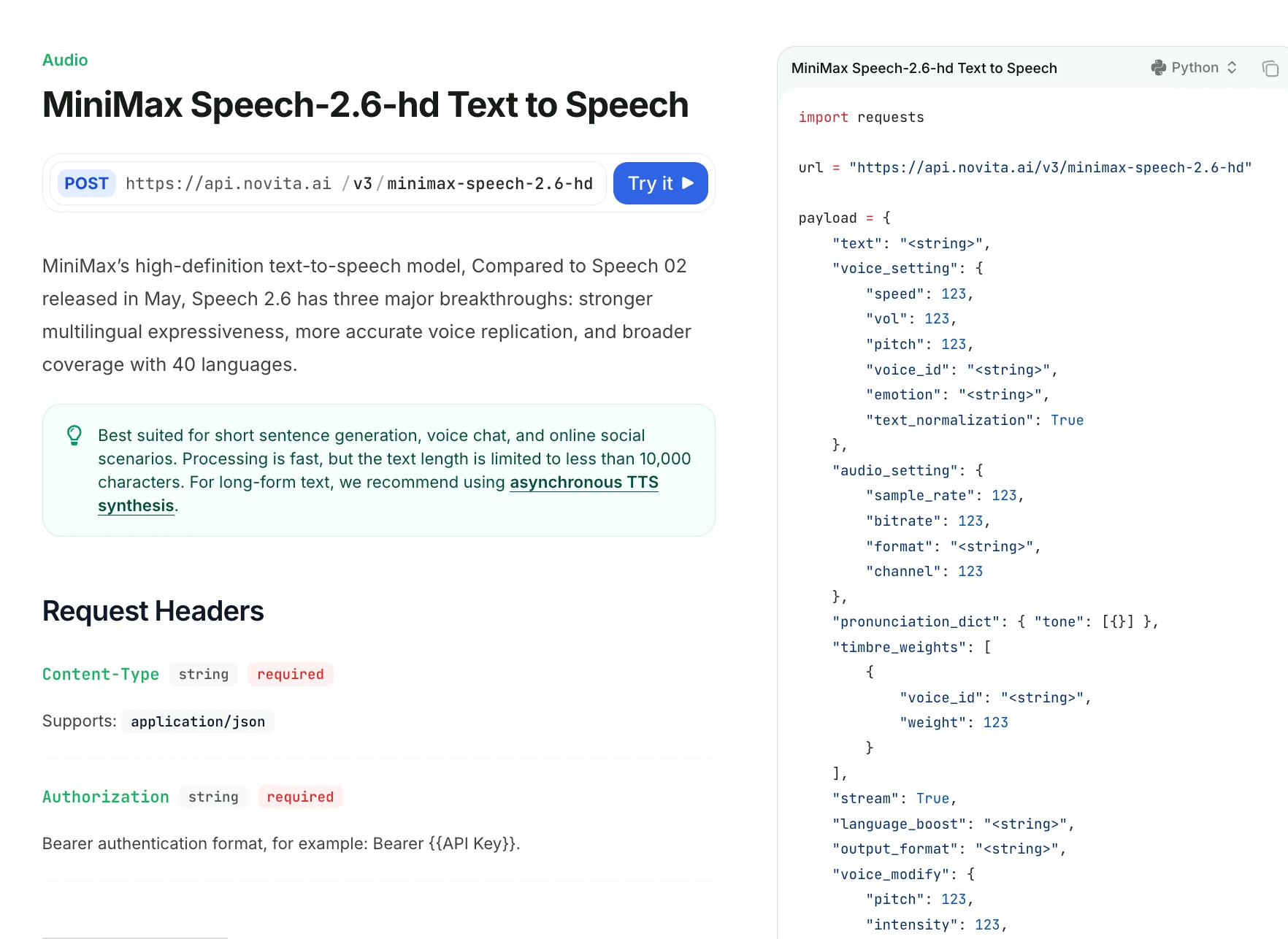
Quão Granular é o Controle sobre Pronúncia, Ênfase e Pausas do Speech 2.6?
| Campo | Descrição |
|---|---|
| text | Texto para sintetizar (<10.000 caracteres). Suporta pausas <#x#> (x em segundos). Sem marcadores de pausa consecutivos. |
| voice_setting | Controla velocidade, volume, pitch, ID de timbre, emoção e normalização. |
| speed | 0,5–2,0; velocidade da fala (padrão 1,0). |
| vol | 0–10; volume do áudio (padrão 1,0). |
| pitch | -12 a 12; alteração de pitch em semitons. |
| voice_id | ID de timbre; vozes do sistema ou clonadas. Obrigatório a menos que use timbre_weights. |
| emotion | Uma de: happy, sad, angry, fearful, disgusted, surprised, neutral. |
| text_normalization | Normalização de texto em inglês (padrão falso). |
| audio_setting | Controla a qualidade da saída de áudio. |
| sample_rate | Um de: 8000–44100 (padrão 32000). |
| bitrate | Apenas mp3; 32000–256000 (padrão 128000). |
| format | mp3 / pcm / flac / wav (wav não serve para streaming). |
| channel | 1 (mono) ou 2 (estéreo); padrão 1. |
| pronunciation_dict | Regras de pronúncia personalizadas; suporte a substituição de tons chineses. |
| tone | Substitui texto ou tons (ex.: "omg" → "oh my god"). |
| timbre_weights | Obrigatório se voice_id não for usado. Até 4 timbres mistos. |
| oice_id | ID de timbre para mistura. |
| weight | 1–100; proporção de mistura. |
| stream | Habilita saída de streaming (padrão falso). |
| language_boost | Melhora o desempenho para um idioma/dialeto, ex.: chinês, inglês, japonês, auto. |
| output_format | hex (padrão) ou url; url apenas no modo não-streaming. |
| voice_modify | Efeitos de voz de pós-processamento. |
| pitch | -100 a 100; mais escuro ↔ mais brilhante. |
| ntensity | -100 a 100; mais forte ↔ mais suave. |
| timbre | -100 a 100; magnético ↔ nítido. |
| sound_effects | spacious_echo, auditorium_echo, lofi_telephone, robotic. |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Experimente o MiniMax Speech 2.6 Agora!
O MiniMax Speech 2.6 Suporta Streaming?
Sim. O MiniMax Speech 2.5 suporta streaming tanto para reconhecimento de fala (ASR) quanto para texto para fala (TTS). A API inclui explicitamente o campo:
"stream": true
em uma solicitação de TTS, o sistema começa a gerar áudio imediatamente e o envia de volta em segmentos. Isso permite que a reprodução comece antes que a frase completa seja sintetizada. A latência de inicialização típica do TTS é de alguns segundos, e cenários otimizados podem atingir tempos de resposta ponta a ponta de menos de um segundo.
Como Usar o MiniMax Speech 2.5 por um Bom Preço?
Passo 1: Faça Login e Acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Experimente o MiniMax Speech 2.6 Agora!
Passo 3: Inicie Seu Teste Gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Ao acessar a página “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

O MiniMax Speech 2.6 oferece novas capacidades — latência de menos de 250 ms, prosódia multilíngue perfeita, clonagem expressiva com Fluent LoRA e formatação automática para URLs, e-mails, números e datas — habilitando aplicações de voz em tempo real, multimodais e ricas em dados que o MiniMax Speech 2.5 não consegue suportar de forma confiável. Enquanto isso, o Speech 2.5 continua sendo a escolha estável e econômica para conteúdo de longa duração e geração de TTS em massa. Juntos, os dois modelos formam um pipeline complementar: Speech 2.6 para diálogo interativo e Speech 2.5 para produção de conteúdo escalável.
Perguntas Frequentes
O que torna o MiniMax Speech 2.6 mais adequado para aplicações em tempo real do que o MiniMax Speech 2.5? O MiniMax Speech 2.6 oferece latência de <250 ms e streaming mais estável, enquanto o MiniMax Speech 2.5 tem atraso maior e é mais adequado para TTS síncrono.
Como o MiniMax Speech 2.6 aprimora a saída multilíngue em comparação com o MiniMax Speech 2.5? O MiniMax Speech 2.6 fortalece a prosódia entre idiomas, a estabilidade de sotaque e a fluência de idiomas mistos, enquanto o MiniMax Speech 2.5 lida com texto multilíngue, mas com troca menos natural.
A clonagem de voz é mais expressiva no MiniMax Speech 2.6 do que no MiniMax Speech 2.5? Sim. O MiniMax Speech 2.6 usa o Fluent LoRA e um codificador de locutor treinado conjuntamente para maior coerência emocional, enquanto o MiniMax Speech 2.5 oferece clonagem sólida, mas menos expressiva.
Novita AI é a plataforma de nuvem tudo-em-um que capacita suas ambições de IA. APIs integradas, serverless, Instâncias de GPU — as ferramentas econômicas que você precisa. Elimine infraestrutura, comece gratuitamente e torne sua visão de IA uma realidade.



