

- Comparaison des variantes du modèle MiniMax Speech 2.6
- Pourquoi Speech 2.6 rend-il enfin les agents vocaux en temps réel viables ?
- Quelles nouvelles fonctionnalités multilingues sont possibles avec Speech 2.6 ?
- Comment Speech 2.6 améliore-t-il le clonage de voix personnalisées ?
- Quels nouveaux types de données multimodales Speech 2.6 peut-il lire sans prétraitement ?
- Quel modèle Speech les développeurs doivent-ils utiliser et quand ?
- Quel est le niveau de contrôle fin sur la prononciation, l'emphase et les pauses de Speech 2.6 ?
- MiniMax Speech 2.6 prend-il en charge le streaming ?
- Comment utiliser MiniMax Speech 2.5 à un bon prix ?
Speech 2.6 n’est pas seulement un successeur de meilleure qualité de la version 2.5 ; il permet des classes entières d’applications en temps réel, multimodales et exploitant des données que la version 2.5 ne pouvait pas prendre en charge de manière fiable.
Pour les développeurs qui choisissent un backend TTS/agent vocal de production, la question cruciale n’est pas de savoir quel modèle « sonne » mieux, mais lequel étend les limites de ce que votre produit peut faire. Cet article présente les deux modèles à travers des points de douleur concrets des développeurs : voix personnalisées, agents en temps réel, expériences multilingues, contenu long, lecture de données multimodales et contrôle des coûts, et explique comment Speech 2.6 lève plusieurs plafonds d’applications.
Comparaison des variantes du modèle MiniMax Speech 2.6
| Dimension | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| Objectif principal | Faible latence et efficacité des coûts | Fidélité et expressivité maximales |
| Latence de bout en bout | < 250 ms pour des phrases typiques | ~0,8 à 1,0 s pour des phrases courtes |
| Débit | Plus rapide que le temps réel pour les textes longs ; optimisé pour le streaming | Débit plus faible ; optimisé pour la qualité |
| Prise en charge du streaming | Oui ; premiers tokens audio en quelques centaines de ms | Partielle ; prend en charge le temps réel pour des longueurs d’entrée modérées |
| Qualité de la prosodie | Prosodie standard ; priorise la vitesse | Prosodie améliorée, micro-détails, prise en charge des émotions fluides |
| Capacité multilingue | 40+ langues ; commutation transparente | 40+ langues avec une naturalité améliorée |
| Styles d’émotion | Pris en charge (basique) | Pris en charge avec une expressivité accrue |
| Tarification | 0,06 $ / 1 000 caractères | 0,10 $ / 1 000 caractères |
| Cas d’usage optimaux | Agents interactifs, chatbots, dialogue en streaming | Voix off, livres audio, narration de qualité studio |
Pourquoi Speech 2.6 rend-il enfin les agents vocaux en temps réel viables ?
La latence inférieure à 250 ms de Speech 2.6 et le streaming stabilisé débloquent des workflows d’interaction vocale naturelle que Speech 2.5 ne peut pas prendre en charge.
L’interaction en temps réel est l’écart le plus important entre les versions 2.5 et 2.6. Les développeurs qui créent des bots de service client, des assistants en magasin ou des fonctionnalités d’interface vocale ont souvent signalé que la latence de Speech 2.5, bien qu’acceptable pour la TTS synchrone, était trop lente pour un véritable dialogue.
Speech 2.6 résout ce problème en repensant le pipeline de décodage et le planificateur de streaming, réduisant le délai aller-retour à moins de 250 ms et rendant la prise de tour quasi instantanée du point de vue de l’utilisateur. Cette modification transforme le modèle d’un générateur de contenu en une couche vocale interactive adaptée aux agents de production. Les développeurs n’ont plus besoin de contourner les délais ou d’ajouter des pauses artificielles ; le modèle correspond enfin au timing des conversations.
Essayez MiniMax Speech 2.6 dès maintenant !
Quelles nouvelles fonctionnalités multilingues sont possibles avec Speech 2.6 ?
Speech 2.6 améliore la prosodie interlangues, permettant aux agents multilingues de changer de langue de manière naturelle en une seule énoncé.
Pour les applications mondiales, les développeurs ont besoin d’une précision de prononciation pour les mélanges chinois-anglais, les marchés d’Asie du Sud-Est et les flux clients multilingues. Speech 2.6 améliore la prosodie interlingue et maintient les voix clonées stables dans plus de 40 langues.
| Fonctionnalité | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| Nombre de langues | 40+ | 40+ |
| Commutation de code | Bon | Fluide et naturel |
| Préservation des accents | Stable | Plus stable dans toutes les langues |
| Lecture de format mixte | Limité | Robuste, adapté aux paramètres régionaux |
Essayez MiniMax Speech 2.6 dès maintenant !
Comment Speech 2.6 améliore-t-il le clonage de voix personnalisées ?
Speech 2.6 fournit des voix clonées plus expressives et émotionnellement cohérentes, permettant la propriété de voix de marque et de créateur à long terme.
Les développeurs qui créent des influenceurs IA, des plateformes d’apprentissage, des agents de jeu de rôle ou des avatars de marque ont besoin d’identités vocales cohérentes et réutilisables. Speech 2.5 avait introduit le clonage zero-shot utilisant un encodeur de locuteur apprenable, une étape majeure pour le contenu personnalisé.
Encodeur de locuteur entraîné conjointement
L’encodeur de locuteur apprenable, entraîné conjointement avec le transformeur principal, atteint une fidélité de clonage vocal de pointe sans transcript de l’audio de référence. L’exposition à plusieurs langues pendant l’entraînement permet un timbre cohérent, une stabilité des accents et un comportement multilingue robuste.
Fluent LoRA pour une adaptation vocale rapide
Fluent LoRA fournit une adaptation low-rank efficace pour une personnalisation vocale fine. Même des échantillons de référence imparfaits contenant des déviations d’accent ou du bruit de fond peuvent être convertis en voix synthétisées claires et fluides, permettant un déploiement rapide dans des environnements divers.
Essayez MiniMax Speech 2.6 dès maintenant !
Quels nouveaux types de données multimodales Speech 2.6 peut-il lire sans prétraitement ?
Speech 2.6 introduit un formatage intelligent, permettant aux développeurs de fournir directement des URL brutes, des e-mails, des nombres, des devises et des dates sans nettoyage par regex.
Dans les applications réelles — tableaux de bord, alertes, mises à jour CRM, notifications logistiques, pipelines RAG — la TTS a souvent besoin de lire des données structurées. Speech 2.5 ne peut lire ce contenu que littéralement, ce qui entraîne une orthographe lettre par lettre maladroite ou des erreurs de prononciation.
Speech 2.6 inclut une normalisation de texte intégrée qui interprète automatiquement les URL, les numéros de téléphone, les adresses IP, les devises et les formats d’horodatage. Cela réduit considérablement le travail de prétraitement et permet aux développeurs d’intégrer la TTS directement dans des flux multimodaux dynamiques, comme la lecture à haute voix de tableaux de bord analytiques ou la vocalisation de notifications e-commerce dans plusieurs paramètres régionaux. Par exemple, une entrée de « 1 234,56 $ » sera prononcée automatiquement « mille deux cent trente-quatre dollars et cinquante-six centimes », et une adresse IP comme « 192.168.1.1 » devient « un neuf deux point un six huit point un point un » sans que vous ayez besoin de l’épeler. Cela améliore considérablement la précision des lectures techniques ou financières et constitue une force unique de MiniMax Speech 2.6.
| Type de données | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URL | Caractères littéraux | Correct, adapté au contexte |
| E-mails | Souvent mal lus | Naturel, adapté aux segments |
| Dates, heures | Incohérent | Stable selon le paramètre régional |
| Devises / Nombres | Basique | Formatage numérique intelligent |
Essayez MiniMax Speech 2.6 dès maintenant !
Quel modèle Speech les développeurs doivent-ils utiliser et quand ?
Speech 2.6 convient le mieux aux
- développeurs qui créent des agents conversationnels en temps réel,
- applications nécessitant une commutation de code multilingue,
- produits nécessitant des voix clonées expressives,
- systèmes lisant des données multimodales structurées (URL, e-mails, nombres),
- flux UX nécessitant un ton émotionnel humain.
Speech 2.5 convient le mieux aux
- plateformes générant de la TTS longue forme en masse,
- contenu éducatif, livres audio, vidéos avec scénario,
- pipelines sensibles aux coûts avec un volume prévisible,
- sorties vocales stables où l’expressivité est moins critique.
Modèle de développeur émergeant en production
- Speech 2.6 gère les flux interactifs, en temps réel, multilingues ou riches en données.
- Speech 2.5 gère les flux longs, par lots ou de narration à grande échelle.
- Les déploiements les plus robustes combinent les deux :
- Speech 2.6 pour le dialogue en direct
- Speech 2.5 pour la génération de contenu
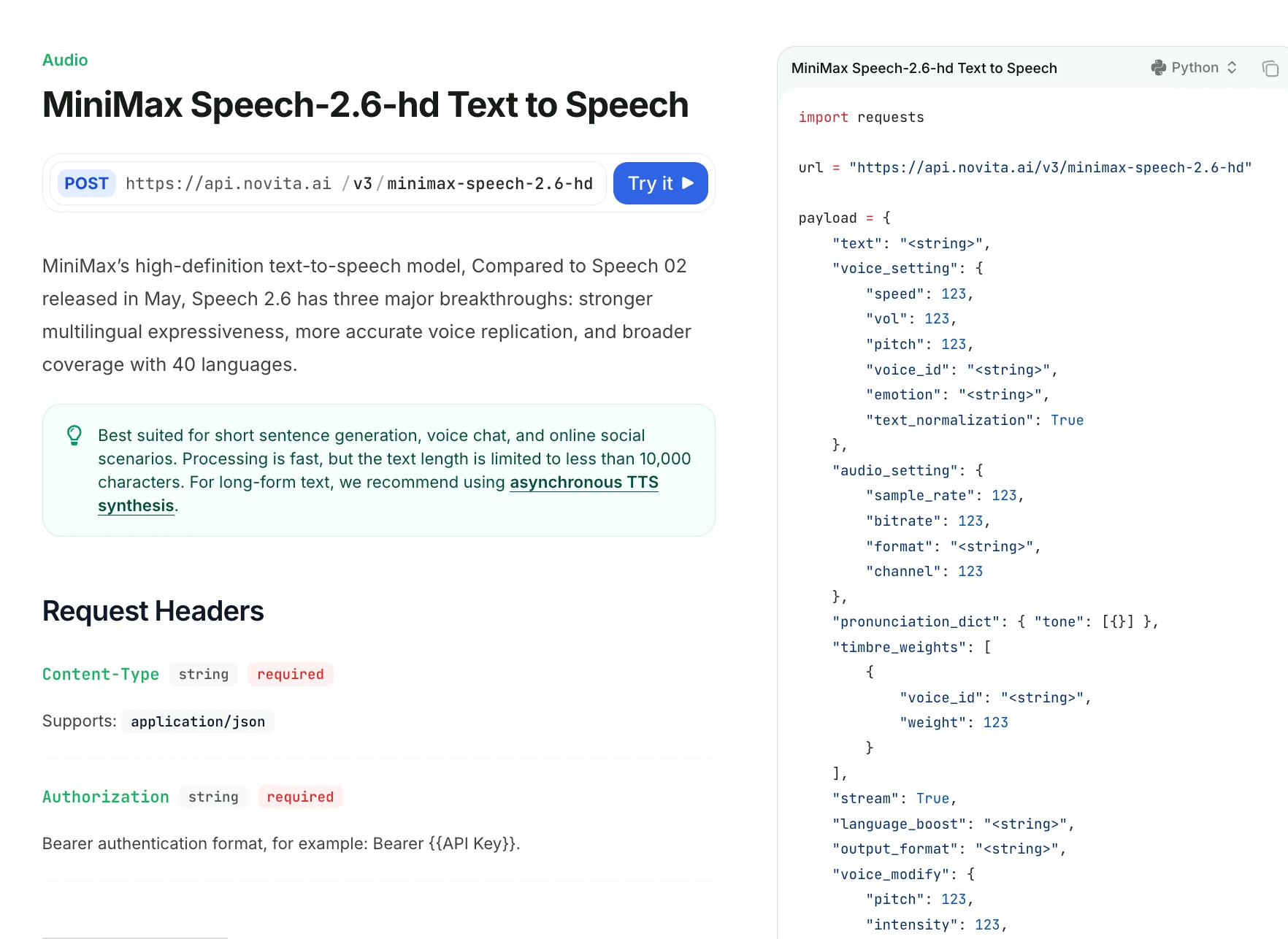
Quel est le niveau de contrôle fin sur la prononciation, l’emphase et les pauses de Speech 2.6 ?
| Champ | Description |
|---|---|
| text | Texte à synthétiser (<10 000 caractères). Prend en charge les pauses <#x#> (x en secondes). Pas de marqueurs de pause consécutifs. |
| voice_setting | Contrôle la vitesse, le volume, la hauteur, l’ID de timbre, l’émotion et la normalisation. |
| speed | 0,5 à 2,0 ; vitesse de parole (par défaut 1,0). |
| vol | 0 à 10 ; volume audio (par défaut 1,0). |
| pitch | -12 à 12 ; décalage de hauteur en demi-tons. |
| voice_id | ID de timbre ; voix système ou clonées. Requis sauf si vous utilisez timbre_weights. |
| emotion | Une des valeurs suivantes : happy, sad, angry, fearful, disgusted, surprised, neutral. |
| text_normalization | Normalisation de texte anglais (par défaut false). |
| audio_setting | Contrôle la qualité de sortie audio. |
| sample_rate | Une des valeurs suivantes : 8000 à 44100 (par défaut 32000). |
| bitrate | mp3 uniquement ; 32000 à 256000 (par défaut 128000). |
| format | mp3 / pcm / flac / wav (wav non pris en charge pour le streaming). |
| channel | 1 (mono) ou 2 (stéréo) ; par défaut 1. |
| pronunciation_dict | Règles de prononciation personnalisées ; remplacement de tons chinois pris en charge. |
| tone | Remplacer du texte ou des tons (par exemple, "omg" → "oh my god"). |
| timbre_weights | Requis si voice_id n’est pas utilisé. Jusqu’à 4 timbres mélangés. |
| oice_id | ID de timbre pour le mélange. |
| weight | 1 à 100 ; ratio de mélange. |
| stream | Activer la sortie en streaming (par défaut false). |
| language_boost | Améliore les performances pour une langue/dialecte, par exemple chinois, anglais, japonais, auto. |
| output_format | hex (par défaut) ou url ; url uniquement en mode non-stream. |
| voice_modify | Effets vocaux de post-traitement. |
| pitch | -100 à 100 ; plus sombre ↔ plus brillant. |
| ntensity | -100 à 100 ; plus fort ↔ plus doux. |
| timbre | -100 à 100 ; magnétique ↔ clair. |
| sound_effects | spacious_echo, auditorium_echo, lofi_telephone, robotic. |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Essayez MiniMax Speech 2.6 dès maintenant !
MiniMax Speech 2.6 prend-il en charge le streaming ?
Oui. MiniMax Speech 2.5 prend en charge le streaming pour la reconnaissance vocale (ASR) et la synthèse vocale (TTS). L’API inclut explicitement le champ :
"stream": true
dans une requête TTS, le système commence à générer de l’audio immédiatement et le renvoie par segments. Cela permet de démarrer la lecture avant que la phrase complète ne soit synthétisée. La latence de démarrage typique de la TTS est de quelques secondes, et les scénarios optimisés peuvent atteindre des temps de réponse de bout en bout inférieurs à une seconde.
Comment utiliser MiniMax Speech 2.5 à un bon prix ?
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Essayez MiniMax Speech 2.6 dès maintenant !
Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les fonctionnalités du modèle sélectionné.
Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En vous rendant sur la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

MiniMax Speech 2.6 offre de nouvelles fonctionnalités — latence inférieure à 250 ms, prosodie multilingue transparente, clonage expressif Fluent LoRA et formatage automatique pour les URL, les e-mails, les nombres et les dates — permettant des applications vocales en temps réel, multimodales et riches en données que MiniMax Speech 2.5 ne peut pas prendre en charge de manière fiable. Parallèlement, Speech 2.5 reste le choix stable et économique pour le contenu longue forme et la génération de TTS en masse. Ensemble, les deux modèles forment un pipeline complémentaire : Speech 2.6 pour le dialogue interactif et Speech 2.5 pour la production de contenu scalable.
Questions fréquemment posées
Qu’est-ce qui rend MiniMax Speech 2.6 plus adapté aux applications en temps réel que MiniMax Speech 2.5 ?
MiniMax Speech 2.6 offre une latence <250 ms et un streaming plus stable, tandis que MiniMax Speech 2.5 a un délai plus élevé et est mieux adapté à la TTS synchrone.
Comment MiniMax Speech 2.6 améliore-t-il les sorties multilingues par rapport à MiniMax Speech 2.5 ?
MiniMax Speech 2.6 renforce la prosodie interlangues, la stabilité des accents et la fluidité des langues mélangées, tandis que MiniMax Speech 2.5 gère les textes multilingues mais avec une commutation moins naturelle.
Le clonage vocal est-il plus expressif dans MiniMax Speech 2.6 que dans MiniMax Speech 2.5 ?
Oui. MiniMax Speech 2.6 utilise Fluent LoRA et un encodeur de locuteur entraîné conjointement pour une cohérence émotionnelle plus élevée, tandis que MiniMax Speech 2.5 propose un clonage solide mais moins expressif.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions IA. API intégrées, serverless, instance GPU — les outils économiques dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et concrétisez votre vision IA.



