

- MiniMax Speech 2.6 モデルバリアントの比較
- なぜ Speech 2.6 はついにリアルタイム音声エージェントを実現可能にしたのか?
- Speech 2.6 で新たに可能になった多言語とは?
- Speech 2.6 はカスタム音声クローンをどのように改善するか?
- Speech 2.6 は前処理なしでどのような新しいマルチモーダルデータタイプを読み取れるか?
- 開発者はいつどの Speech モデルを使うべきか?
- Speech 2.6 の発音、強調、ポーズの制御はどの程度細かいか?
- Minimax Speech 2.6 はストリームに対応していますか?
- 低価格で MiniMax Speech 2.5 を使用する方法
Speech 2.6 は単に 2.5 よりも高品質な後継モデルではありません。リアルタイム、マルチモーダル、データ認識型アプリケーションのクラス全体を実現し、2.5 では確実にサポートできなかったものです。
本番環境で TTS/音声エージェントのバックエンドを選定する開発者にとって、重要な問いは「どのモデルがより良く聞こえるか」ではなく、「どのモデルが 製品の対応範囲 を広げるか」です。この記事では、両モデルを具体的な開発者の課題(カスタム音声、リアルタイムエージェント、多言語体験、長文コンテンツ、マルチモーダルデータ読み取り、コスト管理)に基づいて比較し、Speech 2.6 がどのようにいくつかのアプリケーションの限界を押し上げるかを解説します。
MiniMax Speech 2.6 モデルバリアントの比較
| 次元 | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| 主目的 | 低レイテンシとコスト効率 | 最大限の忠実度と表現力 |
| エンドツーエンドのレイテンシ | 典型的な文で < 250 ms | 短い文で ~0.8–1.0 秒 |
| スループット | 長文でもリアルタイムより高速;ストリーミング最適化 | スループットは低い;品質最適化 |
| ストリーミング対応 | あり;最初の音声トークンが数百ミリ秒以内 | 部分対応;適度な入力長でリアルタイム対応 |
| 韻律品質 | 標準的な韻律;速度重視 | 強化された韻律、マイクロディテール、Fluent Emotion 対応 |
| 多言語能力 | 40 以上の言語;シームレスな切り替え | 40 以上の言語、自然性が向上 |
| 感情スタイル | 対応(基本) | より高い表現力で対応 |
| 価格 | $0.06 / 1,000 文字 | $0.10 / 1,000 文字 |
| 最適なユースケース | インタラクティブエージェント、チャットボット、ストリーミング対話 | ナレーション、オーディオブック、スタジオ品質の読み上げ |
なぜ Speech 2.6 はついにリアルタイム音声エージェントを実現可能にしたのか?
Speech 2.6 の 250 ms 未満のレイテンシと安定したストリーミングにより、Speech 2.5 ではサポートできなかった自然な音声対話ワークフローが実現します。
リアルタイムインタラクションは、2.5 と 2.6 の間で最大のギャップです。カスタマーサービスボット、店内アシスタント、または音声 UI 機能を構築する開発者は、Speech 2.5 のレイテンシが同期 TTS には許容できるものの、真の対話には遅すぎると報告していました。
Speech 2.6 は、デコードパイプラインとストリーミングスケジューラを再設計し、往復遅延を 250 ms 未満に削減し、ユーザーの視点からはターンテイキングがほぼ瞬時に行われるようにすることで、この問題に対処しています。この変更により、モデルはコンテンツ生成器から、本番エージェントに適したインタラクティブな音声層へと移行します。開発者はもはや遅延を回避したり、人工的なポーズを追加する必要はありません。モデルがついに会話のタイミングに適合したのです。
Speech 2.6 で新たに可能になった多言語とは?
Speech 2.6 は言語間の韻律を改善し、マルチリンガルエージェントが単一の発話内で自然に言語を切り替えられるようにします。
グローバルアプリ向けには、開発者は中国語と英語の混在、東南アジア市場、多言語のカスタマーフローにおいて発音精度を必要とします。Speech 2.6 は言語間の韻律を改善し、クローン音声を 40 以上の言語で安定させます。
| 機能 | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| 言語数 | 40+ | 40+ |
| コードスイッチング | 良好 | 流動的で自然 |
| アクセント保持 | 安定 | 言語間でより安定 |
| 混合フォーマット読み取り | 限定的 | 堅牢、ロケール認識 |
Speech 2.6 はカスタム音声クローンをどのように改善するか?
Speech 2.6 はより表現力豊かで感情的に一貫したクローン音声を提供し、長期的なブランド・クリエイターの音声所有を可能にします。
AI インフルエンサー、学習プラットフォーム、ロールプレイングエージェント、ブランドアバターを構築する開発者には、一貫性のある再利用可能な音声アイデンティティが必要です。Speech 2.5 は学習可能な話者エンコーダを使用したゼロショットクローンを導入し、パーソナライズされたコンテンツにとって大きなマイルストーンとなりました。
共同訓練された話者エンコーダ
メインのトランスフォーマーと共同訓練された学習可能な話者エンコーダは、参照音声の書き起こしなしで最先端の音声クローン忠実度を実現します。訓練中に複数の言語にさらされることで、一貫した音色、アクセントの安定性、堅牢な多言語動作が可能になります。
Fluent LoRA による高速音声適応
Fluent LoRA は、きめ細かい音声カスタマイズのための効率的な低ランク適応を提供します。アクセントのずれや背景ノイズを含む不完全な参照サンプルでも、クリーンで流暢な合成音声に変換でき、多様な環境での迅速なデプロイを可能にします。
Speech 2.6 は前処理なしでどのような新しいマルチモーダルデータタイプを読み取れるか?
Speech 2.6 はインテリジェントなフォーマッティングを導入し、開発者は正規表現によるクリーンアップなしで生の URL、メール、数値、通貨、日付を直接入力できます。
実際のアプリケーション(ダッシュボード、アラート、CRM 更新、物流通知、RAG パイプライン)では、TTS はしばしば構造化データを読み取る必要があります。Speech 2.5 はそのようなコンテンツを文字通りにしか読み取ることができず、ぎこちない文字単位のスペルや誤った発音になります。
Speech 2.6 には、URL、電話番号、IP アドレス、通貨、タイムスタンプ形式を自動的に解釈する組み込みのテキスト正規化機能が含まれています。これにより、前処理作業が大幅に削減され、開発者は動的なマルチモーダルフローに TTS を直接統合できるようになります。たとえば、「$1,234.56」という入力は自動的に「one thousand two hundred thirty-four dollars and fifty-six cents」と発話され、「192.168.1.1」のような IP アドレスは「one nine two dot one six eight dot one dot one」と、スペルアウトしなくても読み上げられます。これにより、技術文書や財務文書の読み上げにおいて精度が大幅に向上し、MiniMax Speech 2.6 の独自の強みです。
| データタイプ | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URL | 文字通り | 正しく、コンテキスト認識 |
| メール | 誤読されることが多い | 自然、セグメント認識 |
| 日付、時刻 | 不安定 | ロケールごとに安定 |
| 通貨 / 数値 | 基本 | スマートな数値フォーマッティング |
開発者はいつどの Speech モデルを使うべきか?
Speech 2.6 最適な用途
- リアルタイム対話エージェント を構築する開発者
- 多言語コードスイッチング が必要なアプリ
- 表現力豊かなクローン音声 を必要とする製品
- 構造化マルチモーダルデータ(URL、メール、数値)を読み取るシステム
- 人間らしい感情トーン を要求する UX フロー
Speech 2.5 最適な用途
- 大量の長文 TTS を生成するプラットフォーム
- 教育コンテンツ、オーディオブック、スクリプト動画
- 予測可能なボリュームがあるコスト重視のパイプライン
- 表現力があまり重要でない安定した音声出力
本番環境で浮上している開発パターン
- Speech 2.6 は インタラクティブ、リアルタイム、多言語、データリッチなフロー を担当
- Speech 2.5 は 長文、バッチ、大規模ナレーション を担当
- 最も堅牢なデプロイメントは両方を組み合わせる:
- ライブ対話には Speech 2.6
- コンテンツ生成には Speech 2.5
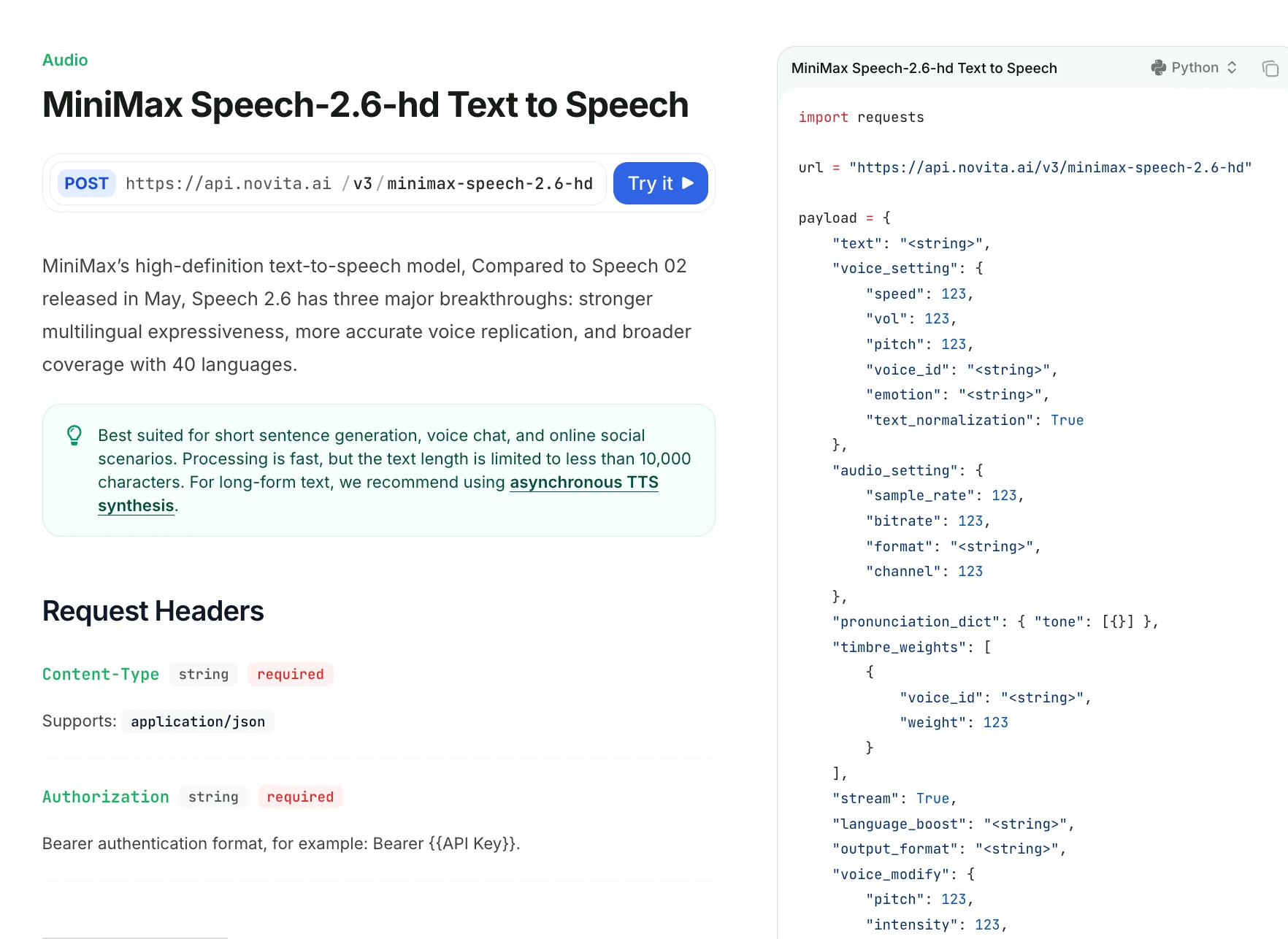
Speech 2.6 の発音、強調、ポーズの制御はどの程度細かいか?
| フィールド | 説明 |
|---|---|
| text | 合成するテキスト(10,000 文字未満)。<#x#> でポーズ(x は秒)を指定可能。連続したポーズマーカーは不可。 |
| voice_setting | 速度、音量、ピッチ、音色 ID、感情、正規化を制御。 |
| speed | 0.5–2.0;話速(デフォルト 1.0)。 |
| vol | 0–10;音量(デフォルト 1.0)。 |
| pitch | -12~12;半音単位のピッチシフト。 |
| voice_id | 音色 ID;システム音声またはクローン音声。timbre_weights を使用しない場合は必須。 |
| emotion | happy, sad, angry, fearful, disgusted, surprised, neutral のいずれか。 |
| text_normalization | 英語テキストの正規化(デフォルト false)。 |
| audio_setting | 音声出力品質を制御。 |
| sample_rate | 8000~44100 のいずれか(デフォルト 32000)。 |
| bitrate | mp3 のみ;32000~256000(デフォルト 128000)。 |
| format | mp3 / pcm / flac / wav(wav はストリーミング不可)。 |
| channel | 1(モノラル)または 2(ステレオ);デフォルト 1。 |
| pronunciation_dict | カスタム発音ルール;中国語の声調上書きをサポート。 |
| tone | テキストまたは声調を置換(例:"omg" → "oh my god")。 |
| timbre_weights | voice_id を使用しない場合に必要。最大 4 つの混合音色。 |
| voice_id | 混合する音色 ID。 |
| weight | 1–100;混合比率。 |
| stream | ストリーミング出力を有効にする(デフォルト false)。 |
| language_boost | 言語/方言のパフォーマンスを向上。例:中文, English, 日本語, auto。 |
| output_format | hex(デフォルト)または url;url は非ストリームモードのみ。 |
| voice_modify | 後処理の音声エフェクト。 |
| pitch | -100~100;暗い↔明るい。 |
| intensity | -100~100;強い↔柔らかい。 |
| timbre | -100~100;磁性的↔はっきり。 |
| sound_effects | spacious_echo, auditorium_echo, lofi_telephone, robotic。 |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Minimax Speech 2.6 はストリームに対応していますか?
はい。MiniMax Speech 2.5 は 音声認識 (ASR) と テキスト読み上げ (TTS) の両方でストリーミングをサポートしています。API は明示的にフィールドを含んでいます:
"stream": true
TTS リクエストでこれを指定すると、システムは即座に音声の生成を開始し、セグメントで返送します。これにより、文全体が合成される前に再生を開始できます。一般的な TTS の起動遅延は数秒以内で、最適化されたシナリオではエンドツーエンドの応答時間が 1 秒未満になります。
低価格で MiniMax Speech 2.5 を使用する方法
ステップ 1: ログインしてモデルライブラリにアクセス
アカウントにログインし、Model Library ボタンをクリックします。

ステップ 2: モデルを選択
利用可能なオプションからニーズに合ったモデルを選択します。
ステップ 3: 無料トライアルを開始
選択したモデルの機能を無料トライアルで試してみましょう。
ステップ 4: API キーを取得
API 認証のために、新しい API キーを提供します。「Settings」ページに移動し、画像のように API キーをコピーします。

MiniMax Speech 2.6 は、250 ms 未満のレイテンシ、シームレスな多言語韻律、Fluent LoRA による表現力豊かなクローン、URL、メール、数値、日付の自動フォーマッティングといった新機能を提供し、MiniMax Speech 2.5 では確実にサポートできなかったリアルタイム、マルチモーダル、データリッチな音声アプリケーションを実現します。一方、Speech 2.5 は長文コンテンツやバルク TTS 生成において安定したコスト効率の高い選択肢であり続けます。両モデルは補完的なパイプラインを形成します。Speech 2.6 はインタラクティブな対話に、Speech 2.5 はスケーラブルなコンテンツ制作に最適です。
よくある質問
MiniMax Speech 2.6 は MiniMax Speech 2.5 よりリアルタイムアプリケーションに適している理由は?
MiniMax Speech 2.6 は 250 ms 未満のレイテンシとより安定したストリーミングを提供しますが、MiniMax Speech 2.5 は遅延が大きく、同期 TTS に適しています。
MiniMax Speech 2.6 は MiniMax Speech 2.5 と比較して多言語出力をどのように改善しますか?
MiniMax Speech 2.6 は言語間の韻律、アクセントの安定性、混合言語の流暢さを強化します。一方、MiniMax Speech 2.5 は多言語テキストを扱えますが、切り替えが自然ではありません。
音声クローンは MiniMax Speech 2.6 の方が MiniMax Speech 2.5 より表現力豊かですか?
はい。MiniMax Speech 2.6 は Fluent LoRA と共同訓練された話者エンコーダを使用し、より高い感情的一貫性を実現します。MiniMax Speech 2.5 は堅実ですが表現力は劣ります。
Novita AI は AI の野心を強化するオールインワンのクラウドプラットフォームです。統合 API、サーバーレス、GPU インスタンス——必要なコスト効率の高いツール。インフラを排除し、無料で始めて、AI ビジョンを現実にしましょう。



