

- Vergleich der MiniMax Speech 2.6 Modellvarianten
- Warum macht Speech 2.6 endlich Echtzeit-Sprachagenten praktikabel?
- Welche neuen mehrsprachigen Möglichkeiten ergeben sich mit Speech 2.6?
- Wie verbessert Speech 2.6 das benutzerdefinierte Stimmenklonen?
- Welche neuen Multimodal-Datentypen kann Speech 2.6 ohne Vorverarbeitung lesen?
- Welches Sprachmodell sollten Entwickler wählen und wann?
- Wie feingranular ist die Kontrolle über Aussprache, Betonung und Pausen von Speech 2.6?
- Unterstützt MiniMax Speech 2.6 Streaming?
- Wie nutzt man MiniMax Speech 2.5 zu einem guten Preis?
Speech 2.6 ist nicht nur ein qualitativ hochwertigerer Nachfolger von 2.5; es ermöglicht ganze Klassen von Echtzeit-, Multimodal- und datenbewussten Anwendungen, die 2.5 nicht zuverlässig unterstützen konnte.
Für Entwickler, die ein Produktions-Backend für TTS/Sprachagenten auswählen, lautet die entscheidende Frage nicht, welches Modell „besser klingt“, sondern welches die Grenzen dessen, was Ihr Produkt leisten kann, erweitert. Dieser Artikel betrachtet beide Modelle anhand konkreter Entwickler-Schmerzpunkte – benutzerdefinierte Stimmen, Echtzeit-Agenten, mehrsprachige Erlebnisse, Langforminhalte, Multimodal-Datenlesen und Kostenkontrolle – und erklärt, wie Speech 2.6 mehrere Anwendungsgrenzen anhebt.
Vergleich der MiniMax Speech 2.6 Modellvarianten
| Dimension | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| Primäres Ziel | Niedrige Latenz und Kosteneffizienz | Maximale Klangtreue und Ausdrucksstärke |
| End-to-End-Latenz | < 250 ms für typische Sätze | ~0,8–1,0 s für kurze Sätze |
| Durchsatz | Schneller als Echtzeit für lange Texte; optimiert für Streaming | Niedrigerer Durchsatz; optimiert für Qualität |
| Streaming-Unterstützung | Ja; erste Audiotoken innerhalb weniger hundert Millisekunden | Teilweise; unterstützt Echtzeit für moderate Eingabelängen |
| Prosodie-Qualität | Standard-Prosodie; priorisiert Geschwindigkeit | Verbesserte Prosodie, Mikrodetails, Unterstützung für Fluent Emotion |
| Mehrsprachige Fähigkeit | 40+ Sprachen; nahtloses Wechseln | 40+ Sprachen mit verbesserter Natürlichkeit |
| Emotionsstile | Unterstützt (basic) | Unterstützt mit höherer Ausdrucksstärke |
| Preise | $0,06 / 1.000 Zeichen | $0,10 / 1.000 Zeichen |
| Bestmögliche Anwendungsfälle | Interaktive Agenten, Chatbots, Streaming-Dialoge | Voiceovers, Hörbücher, Studio-Narration |
Warum macht Speech 2.6 endlich Echtzeit-Sprachagenten praktikabel?
Die Sub-250-ms-Latenz von Speech 2.6 und das stabilisierte Streaming ermöglichen natürliche Sprachinteraktions-Workflows, die Speech 2.5 nicht unterstützen kann.
Echtzeit-Interaktion ist die größte Lücke zwischen 2.5 und 2.6. Entwickler, die Kundenservice-Bots, In-Store-Assistenten oder Sprach-UI-Funktionen erstellen, berichteten oft, dass die Latenz von Speech 2.5 – obwohl für synchrones TTS akzeptabel – für einen echten Dialog zu langsam war.
Speech 2.6 behebt dies durch eine Neugestaltung der Dekodierungspipeline und des Streaming-Planers, reduziert die Round-Trip-Verzögerung auf unter 250 ms und macht den Sprecherwechsel aus Benutzersicht nahezu augenblicklich. Diese Änderung verwandelt das Modell von einem Inhaltsgenerator in eine interaktive Sprachschicht, die für Produktionsagenten geeignet ist. Entwickler müssen nicht mehr um Verzögerungen herumarbeiten oder künstliche Pausen einfügen; das Modell passt endlich zur Gesprächszeit.
Probieren Sie MiniMax Speech 2.6 jetzt aus!
Welche neuen mehrsprachigen Möglichkeiten ergeben sich mit Speech 2.6?
Speech 2.6 verbessert die sprachübergreifende Prosodie, sodass mehrsprachige Agenten in einem einzelnen Äußerungszug natürlich zwischen Sprachen wechseln können.
Für globale Apps benötigen Entwickler Aussprachegenauigkeit bei Chinesisch-Englisch-Mischungen, in südostasiatischen Märkten und mehrsprachigen Kundenabläufen. Speech 2.6 verbessert die sprachübergreifende Prosodie und hält geklonte Stimmen in über 40 Sprachen stabil.
| Funktion | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| Sprachanzahl | 40+ | 40+ |
| Code-Switching | Gut | Fließend und natürlich |
| Akzenterhaltung | Stabil | Noch stabiler über Sprachen hinweg |
| Lesen von gemischten Formaten | Eingeschränkt | Robust, lokalisierungsbewusst |
Probieren Sie MiniMax Speech 2.6 jetzt aus!
Wie verbessert Speech 2.6 das benutzerdefinierte Stimmenklonen?
Speech 2.6 liefert ausdrucksstärkere, emotional kohärente geklonte Stimmen und ermöglicht langfristige Marken- und Erzählerstimmen-Eigentum.
Entwickler, die KI-Influencer, Lernplattformen, Rollenspiel-Agenten oder Marken-Avatare erstellen, benötigen konsistente, wiederverwendbare Stimmenidentitäten. Speech 2.5 führte das Zero-Shot-Klonen mit einem erlernbaren Sprecher-Encoder ein, einen wichtigen Meilenstein für personalisierte Inhalte.
Gemeinsam trainierter Sprecher-Encoder
Der erlernbare Sprecher-Encoder, der gemeinsam mit dem Haupt-Transformer trainiert wird, erreicht eine state-of-the-art-Stimmenklon-Treue ohne Transkripte des Referenzaudios. Die Konfrontation mit mehreren Sprachen während des Trainings ermöglicht konsistenten Klang, Akzentstabilität und robustes mehrsprachiges Verhalten.
Fluent LoRA für schnelle Stimmenanpassung
Fluent LoRA bietet eine effiziente Low-Rank-Anpassung für feingranulare Stimmenanpassung. Selbst unvollständige Referenzproben mit Akzentabweichungen oder Hintergrundgeräuschen können in saubere, flüssige synthetisierte Stimmen umgewandelt werden, was eine schnelle Bereitstellung in unterschiedlichen Umgebungen ermöglicht.
Probieren Sie MiniMax Speech 2.6 jetzt aus!
Welche neuen Multimodal-Datentypen kann Speech 2.6 ohne Vorverarbeitung lesen?
Speech 2.6 führt eine intelligente Formatierung ein, die es Entwicklern ermöglicht, rohe URLs, E-Mails, Zahlen, Währungen und Daten direkt ohne Regex-Bereinigung einzugeben.
In Echt-Anwendungen – Dashboards, Warnungen, CRM-Updates, Logistik-Benachrichtigungen, RAG-Pipelines – muss TTS oft strukturierte Daten vorlesen. Speech 2.5 kann solche Inhalte nur wörtlich vorlesen, was zu unbeholfenem buchstabierenem Vorlesen oder Fehlaussprachen führt.
Speech 2.6 enthält eine integrierte Textnormalisierung, die URLs, Telefonnummern, IP-Adressen, Währungen und Zeitstempelformate automatisch interpretiert. Dies reduziert den Vorverarbeitungsaufwand drastisch und ermöglicht es Entwicklern, TTS direkt in dynamische Multimodal-Abläufe zu integrieren, z. B. um Analyse-Dashboards vorzulesen oder E-Commerce-Benachrichtigungen in mehreren Gebietsschemas vorzulesen. Beispielsweise wird eine Eingabe von „$1,234.56“ automatisch als „one thousand two hundred thirty-four dollars and fifty-six cents“ vorgelesen, und eine IP-Adresse wie „192.168.1.1“ wird zu „one nine two dot one six eight dot one dot one“, ohne dass Sie es buchstabieren müssen. Dies erhöht die Genauigkeit bei technischen oder finanziellen Vorlesungen erheblich und ist eine einzigartige Stärke von MiniMax Speech 2.6.
| Datentyp | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URLs | Wörtliche Zeichen | Korrekt, kontextbewusst |
| E-Mails | Oft falsch ausgesprochen | Natürlich, segmentbewusst |
| Daten, Uhrzeiten | Inkonsistent | Stabil pro Gebietsschema |
| Währungen / Zahlen | Basic | Intelligente Zahlenformatierung |
Probieren Sie MiniMax Speech 2.6 jetzt aus!
Welches Sprachmodell sollten Entwickler wählen und wann?
Speech 2.6 eignet sich am besten für
- Entwickler, die Echtzeit-Konversationsagenten erstellen,
- Apps, die mehrsprachiges Code-Switching erfordern,
- Produkte, die ausdrucksstarke geklonte Stimmen benötigen,
- Systeme, die strukturierte Multimodal-Daten (URLs, E-Mails, Zahlen) lesen,
- UX-Abläufe, die menschlich klingende emotionale Töne erfordern.
Speech 2.5 eignet sich am besten für
- Plattformen, die Massen-Langform-TTS generieren,
- Bildungsinhalte, Hörbücher, geskriptete Videos,
- Kostensensitive Pipelines mit vorhersehbarem Volumen,
- Stabile Sprachausgaben, bei denen Ausdrucksstärke weniger kritisch ist.
Sich in der Produktion abzeichnendes Entwickler-Muster
- Speech 2.6 verarbeitet interaktive, Echtzeit-, mehrsprachige oder datenreiche Abläufe.
- Speech 2.5 verarbeitet Langform-, Batch- oder großangelegte Narration.
- Die robustesten Bereitstellungen kombinieren beide:
- Speech 2.6 für Live-Dialoge
- Speech 2.5 für Inhaltsgenerierung
Wie feingranular ist die Kontrolle über Aussprache, Betonung und Pausen von Speech 2.6?
| Feld | Beschreibung |
|---|---|
| text | Zu synthetisierender Text (<10.000 Zeichen). Unterstützt <#x#>-Pausen (x in Sekunden). Keine aufeinanderfolgenden Pausenmarkierungen. |
| voice_setting | Steuert Geschwindigkeit, Lautstärke, Tonhöhe, Klang-ID, Emotion und Normalisierung. |
| speed | 0,5–2,0; Sprechgeschwindigkeit (Standard 1,0). |
| vol | 0–10; Audio-Lautstärke (Standard 1,0). |
| pitch | -12 bis 12; Tonhöhenverschiebung in Halbtönen. |
| voice_id | Klang-ID; System- oder geklonte Stimmen. Erforderlich, es sei denn, timbre_weights wird verwendet. |
| emotion | Einer von: happy, sad, angry, fearful, disgusted, surprised, neutral. |
| text_normalization | Englische Textnormalisierung (Standard false). |
| audio_setting | Steuert die Audioausgabequalität. |
| sample_rate | Einer von: 8000–44100 (Standard 32000). |
| bitrate | Nur mp3; 32000–256000 (Standard 128000). |
| format | mp3 / pcm / flac / wav (wav nicht für Streaming). |
| channel | 1 (Mono) oder 2 (Stereo); Standard 1. |
| pronunciation_dict | Benutzerdefinierte Ausspracheregeln; Überschreibung des chinesischen Tons unterstützt. |
| tone | Ersetze Text oder Töne (z. B. "omg" → "oh my god"). |
| timbre_weights | Erforderlich, wenn voice_id nicht verwendet wird. Bis zu 4 gemischte Klänge. |
| oice_id | Klang-ID zum Mischen. |
| weight | 1–100; Mischverhältnis. |
| stream | Aktiviere Streaming-Ausgabe (Standard false). |
| language_boost | Verbessere die Leistung für eine Sprache/einen Dialekt, z. B. Chinesisch, Englisch, Japanisch, auto. |
| output_format | hex (Standard) oder url; url nur im Nicht-Streaming-Modus. |
| voice_modify | Nachverarbeitung von Sprach-Effekten. |
| pitch | -100 bis 100; dunkler ↔ heller. |
| ntensity | -100 bis 100; stärker ↔ schwächer. |
| timbre | -100 bis 100; magnetisch ↔ klar. |
| sound_effects | spacious_echo, auditorium_echo, lofi_telephone, robotic. |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Probieren Sie MiniMax Speech 2.6 jetzt aus!
Unterstützt MiniMax Speech 2.6 Streaming?
Ja. MiniMax Speech 2.5 unterstützt Streaming sowohl für die Spracherkennung (ASR) als auch für die Text-zu-Sprache (TTS). Die API enthält explizit das Feld:
"stream": true
Wenn es in einer TTS-Anfrage enthalten ist, beginnt das System sofort mit der Audiogenerierung und sendet sie in Segmenten zurück. Dadurch kann die Wiedergabe starten, bevor der gesamte Satz synthetisiert ist. Die typische Startlatenz von TTS liegt innerhalb weniger Sekunden, und optimierte Szenarien können sub-sekündliche End-to-End-Antwortzeiten erreichen.
Wie nutzt man MiniMax Speech 2.5 zu einem guten Preis?
Schritt 1: Einloggen und Zugriff auf die Modellbibliothek
Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Probieren Sie MiniMax Speech 2.6 jetzt aus!
Schritt 3: Starten Sie Ihre kostenlose Testversion
Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
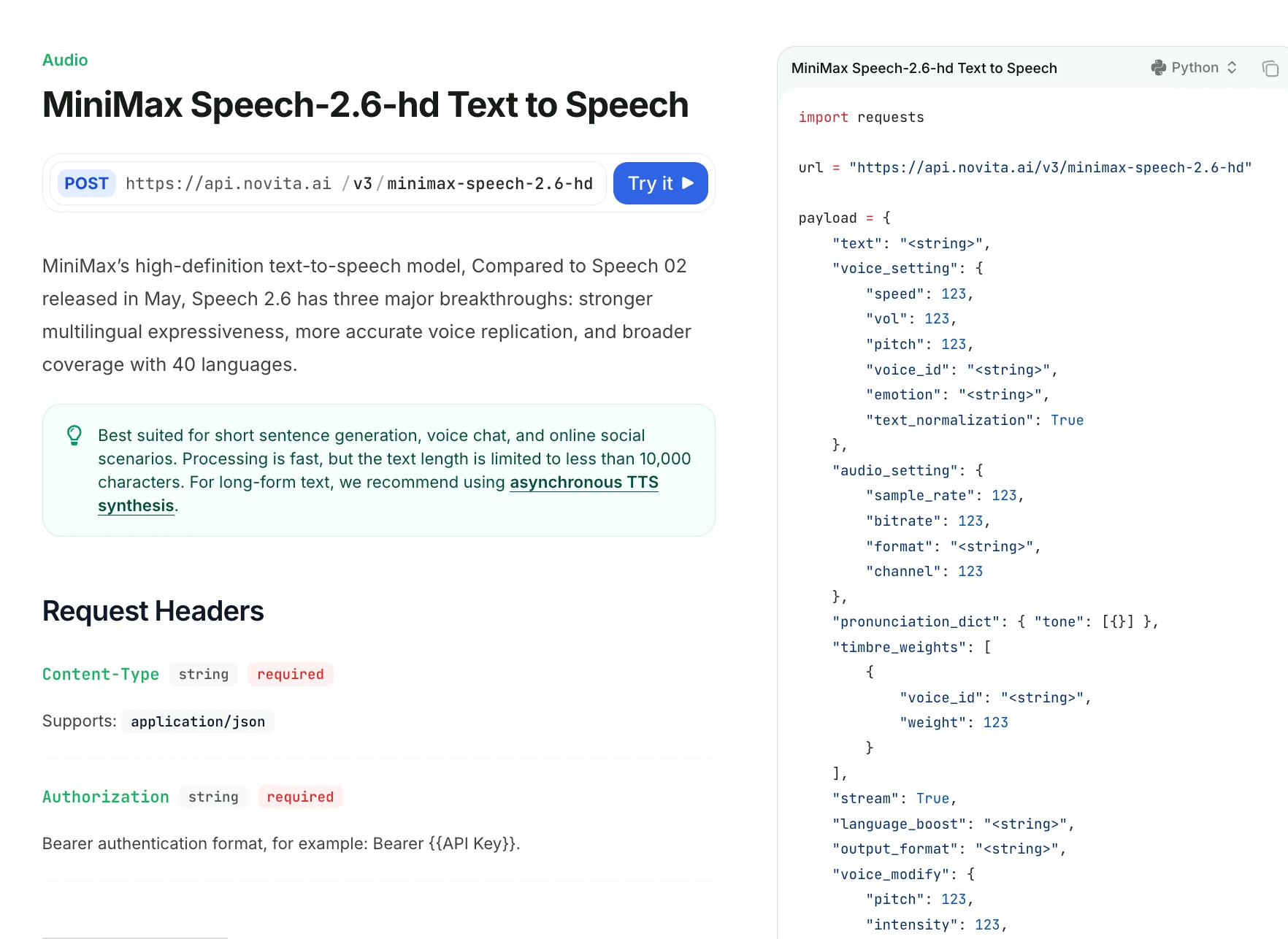
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Um sich bei der API zu authentifizieren, stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

MiniMax Speech 2.6 bietet neue Funktionen – Sub-250-ms-Latenz, nahtlose mehrsprachige Prosodie, ausdrucksstarkes Fluent LoRA-Klonen und automatische Formatierung für URLs, E-Mails, Zahlen und Daten – und ermöglicht Echtzeit-, Multimodal- und datenreiche Sprach-Anwendungen, die MiniMax Speech 2.5 nicht zuverlässig unterstützen kann. Unterdessen bleibt Speech 2.5 die stabile, kosteneffiziente Wahl für Langforminhalte und Massen-TTS-Generierung. Zusammen bilden die beiden Modelle eine komplementäre Pipeline: Speech 2.6 für interaktive Dialoge und Speech 2.5 für skalierbare Inhaltsproduktion.
Häufig gestellte Fragen
Was macht MiniMax Speech 2.6 für Echtzeitanwendungen besser geeignet als MiniMax Speech 2.5?
MiniMax Speech 2.6 bietet eine Latenz von <250 ms und stabileres Streaming, während MiniMax Speech 2.5 eine höhere Verzögerung hat und besser für synchrones TTS geeignet ist.
Wie verbessert MiniMax Speech 2.6 die mehrsprachige Ausgabe im Vergleich zu MiniMax Speech 2.5?
MiniMax Speech 2.6 stärkt die sprachübergreifende Prosodie, Akzentstabilität und Mischsprach-Flüssigkeit, während MiniMax Speech 2.5 mehrsprachigen Text verarbeitet, aber mit weniger natürlichem Wechsel.
Ist das Stimmenklonen in MiniMax Speech 2.6 ausdrucksstärker als in MiniMax Speech 2.5?
Ja. MiniMax Speech 2.6 verwendet Fluent LoRA und einen gemeinsam trainierten Sprecher-Encoder für höhere emotionale Kohärenz, während MiniMax Speech 2.5 solides, aber weniger ausdrucksstarkes Klonen bietet.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen verwirklicht. Integrierte APIs, Serverless, GPU-Instanzen – die kosteneffektiven Tools, die Sie brauchen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



