

- Comparación de las variantes del modelo MiniMax Speech 2.6
- ¿Por qué Speech 2.6 finalmente hace viables los agentes de voz en tiempo real?
- ¿Qué nuevas capacidades multilingües son posibles en Speech 2.6?
- ¿Cómo mejora Speech 2.6 la clonación de voz personalizada?
- ¿Qué nuevos tipos de datos multimodales puede leer Speech 2.6 sin preprocesamiento?
- ¿Qué modelo de voz deben usar los desarrolladores y cuándo?
- ¿Qué tan detallado es el control sobre pronunciación, énfasis y pausas de Speech 2.6?
- ¿Soporta MiniMax Speech 2.6 streaming?
- ¿Cómo usar MiniMax Speech 2.5 a buen precio?
Speech 2.6 no es simplemente un sucesor de mayor calidad de 2.5; habilita clases completas de aplicaciones en tiempo real, multimodales y conscientes de datos que 2.5 no podía soportar de manera confiable.
Para los desarrolladores que eligen un backend de TTS/agente de voz en producción, la pregunta crucial no es qué modelo “suena” mejor, sino cuál amplía el límite de lo que tu producto puede hacer. Este artículo enmarca ambos modelos a través de puntos débiles concretos del desarrollador: voces personalizadas, agentes en tiempo real, experiencias multilingües, contenido extenso, lectura de datos multimodales y control de costos, y explica cómo Speech 2.6 eleva varios techos de aplicación.
Comparación de las variantes del modelo MiniMax Speech 2.6
| Dimensión | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| Objetivo principal | Baja latencia y eficiencia de costos | Máxima fidelidad y expresividad |
| Latencia de extremo a extremo | < 250 ms para oraciones típicas | ~0.8–1.0 s para oraciones cortas |
| Rendimiento | Más rápido que el tiempo real para texto largo; optimizado para streaming | Rendimiento más bajo; optimizado para calidad |
| Soporte de streaming | Sí; primeros tokens de audio en unos pocos cientos de ms | Parcial; soporta tiempo real para longitud de entrada moderada |
| Calidad de prosodia | Prosodia estándar; prioriza la velocidad | Prosodia mejorada, microdetalles, soporte para Fluent Emotion |
| Capacidad multilingüe | 40+ idiomas; cambio sin problemas | 40+ idiomas con naturalidad mejorada |
| Estilos de emoción | Soportados (básicos) | Soportados con mayor expresividad |
| Precio | $0.06 / 1000 caracteres | $0.10 / 1000 caracteres |
| Mejores casos de uso | Agentes interactivos, chatbots, diálogos en streaming | Narraciones, audiolibros, narración de calidad de estudio |
¿Por qué Speech 2.6 finalmente hace viables los agentes de voz en tiempo real?
La latencia inferior a 250 ms de Speech 2.6 y el streaming estabilizado desbloquean flujos de trabajo de interacción por voz natural que Speech 2.5 no puede soportar.
La interacción en tiempo real es la brecha más grande entre 2.5 y 2.6. Los desarrolladores que construyen bots de servicio al cliente, asistentes en tiendas o funciones de UI por voz a menudo informaron que la latencia de Speech 2.5, aunque aceptable para TTS síncrono, se sentía demasiado lenta para un diálogo real.
Speech 2.6 aborda esto rediseñando el pipeline de decodificación y el planificador de streaming, reduciendo la demora de ida y vuelta a menos de 250 ms y haciendo que la toma de turnos sea casi instantánea desde la perspectiva del usuario. Este cambio transforma el modelo de un generador de contenido en una capa de voz interactiva adecuada para agentes de producción. Los desarrolladores ya no necesitan sortear retrasos o agregar pausas artificiales; el modelo finalmente se ajusta al tiempo conversacional.
¡Prueba MiniMax Speech 2.6 ahora!
¿Qué nuevas capacidades multilingües son posibles en Speech 2.6?
Speech 2.6 mejora la prosodia entre idiomas, haciendo que los agentes multilingües cambien de idioma de forma natural en una sola expresión.
Para aplicaciones globales, los desarrolladores necesitan precisión en la pronunciación en mezclas de chino e inglés, mercados del sudeste asiático y flujos de clientes multilingües. Speech 2.6 mejora la prosodia entre idiomas y mantiene las voces clonadas estables en más de 40 idiomas.
| Característica | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| Número de idiomas | 40+ | 40+ |
| Cambio de código | Bueno | Fluido y natural |
| Preservación de acento | Estable | Más estable entre idiomas |
| Lectura de formatos mixtos | Limitada | Robusta y consciente de la localidad |
¡Prueba MiniMax Speech 2.6 ahora!
¿Cómo mejora Speech 2.6 la clonación de voz personalizada?
Speech 2.6 ofrece voces clonadas más expresivas y emocionalmente coherentes, permitiendo la propiedad de voz a largo plazo para marcas y creadores.
Los desarrolladores que construyen influencers de IA, plataformas de aprendizaje, agentes de juegos de rol o avatares de marca requieren identidades de voz consistentes y reutilizables. Speech 2.5 introdujo la clonación zero-shot usando un codificador de hablante aprendible, un hito importante para el contenido personalizado.
Codificador de hablante entrenado conjuntamente
El codificador de hablante aprendible, entrenado conjuntamente con el transformador principal, logra una fidelidad de clonación de voz de última generación sin necesidad de transcripciones del audio de referencia. La exposición a múltiples idiomas durante el entrenamiento permite un timbre consistente, estabilidad de acento y un comportamiento multilingüe robusto.
Fluent LoRA para adaptación rápida de voz
Fluent LoRA proporciona una adaptación eficiente de bajo rango para la personalización detallada de la voz. Incluso muestras de referencia imperfectas con desviaciones de acento o ruido de fondo pueden convertirse en voces sintetizadas limpias y fluidas, permitiendo un despliegue rápido en entornos diversos.
¡Prueba MiniMax Speech 2.6 ahora!
¿Qué nuevos tipos de datos multimodales puede leer Speech 2.6 sin preprocesamiento?
Speech 2.6 introduce formato inteligente, permitiendo a los desarrolladores introducir URLs, correos electrónicos, números, monedas y fechas sin procesamiento regex.
En aplicaciones reales (tableros, alertas, actualizaciones de CRM, notificaciones logísticas, pipelines RAG), el TTS a menudo necesita leer datos estructurados. Speech 2.5 solo puede leer dicho contenido literalmente, resultando en deletreo torpe o mala pronunciación.
Speech 2.6 incluye normalización de texto integrada que interpreta automáticamente URLs, números de teléfono, direcciones IP, monedas y formatos de marca de tiempo. Esto reduce drásticamente el trabajo de preprocesamiento y permite a los desarrolladores integrar TTS directamente en flujos multimodales dinámicos, como leer tableros de análisis en voz alta o vocalizar notificaciones de comercio electrónico en múltiples idiomas. Por ejemplo, una entrada de “$1,234.56” se dirá automáticamente como “mil doscientos treinta y cuatro dólares con cincuenta y seis centavos”, y una dirección IP como “192.168.1.1” se convertirá en “uno nueve dos punto uno seis ocho punto uno punto uno” sin necesidad de deletrearlo. Esto aumenta significativamente la precisión en lecturas técnicas o financieras y es una fortaleza única de MiniMax Speech 2.6.
| Tipo de dato | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URLs | Caracteres literales | Correcta y consciente del contexto |
| Correos electrónicos | A menudo mal leídos | Natural y consciente de segmentos |
| Fechas, horas | Inconsistente | Estable por localidad |
| Monedas / Números | Básico | Formato numérico inteligente |
¡Prueba MiniMax Speech 2.6 ahora!
¿Qué modelo de voz deben usar los desarrolladores y cuándo?
Speech 2.6 es ideal para
- desarrolladores que construyen agentes conversacionales en tiempo real,
- aplicaciones que requieren cambio de código multilingüe,
- productos que necesitan voces clonadas expresivas,
- sistemas que leen datos multimodales estructurados (URLs, correos, números),
- flujos de UX que exigen tono emocional similar al humano.
Speech 2.5 es ideal para
- plataformas que generan TTS de formato largo por lotes,
- contenido educativo, audiolibros, videos con guión,
- pipelines sensibles al costo con volumen predecible,
- salidas de voz estables donde la expresividad es menos crítica.
Patrón de desarrollador que emerge en producción
- Speech 2.6 maneja flujos interactivos, en tiempo real, multilingües o ricos en datos.
- Speech 2.5 maneja narraciones de formato largo, por lotes o a gran escala.
- Los despliegues más robustos combinan ambos:
- Speech 2.6 para diálogo en vivo
- Speech 2.5 para generación de contenido
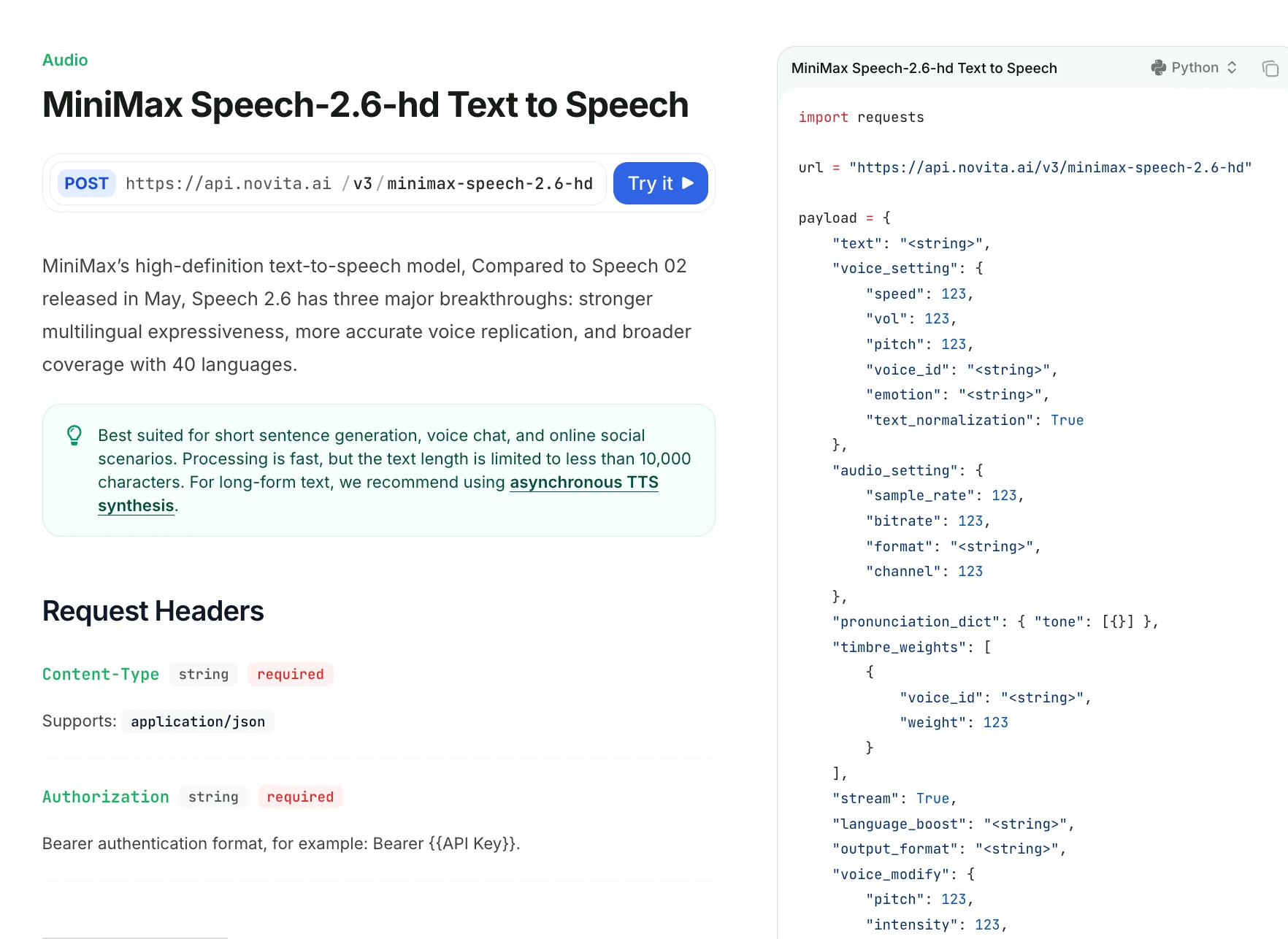
¿Qué tan detallado es el control sobre pronunciación, énfasis y pausas de Speech 2.6?
| Campo | Descripción |
|---|---|
| text | Texto a sintetizar (<10,000 caracteres). Soporta pausas <#x#> (x en segundos). Sin marcadores de pausa consecutivos. |
| voice_setting | Controla velocidad, volumen, tono, ID de timbre, emoción y normalización. |
| speed | 0.5–2.0; velocidad del habla (por defecto 1.0). |
| vol | 0–10; volumen del audio (por defecto 1.0). |
| pitch | -12 a 12; cambio de tono en semitonos. |
| voice_id | ID de timbre; voces del sistema o clonadas. Requerido a menos que se use timbre_weights. |
| emotion | Uno de: happy, sad, angry, fearful, disgusted, surprised, neutral. |
| text_normalization | Normalización de texto en inglés (por defecto false). |
| audio_setting | Controla la calidad de salida de audio. |
| sample_rate | Uno de: 8000–44100 (por defecto 32000). |
| bitrate | solo mp3; 32000–256000 (por defecto 128000). |
| format | mp3 / pcm / flac / wav (wav no para streaming). |
| channel | 1 (mono) o 2 (estéreo); por defecto 1. |
| pronunciation_dict | Reglas de pronunciación personalizadas; soporta anulación de tono en chino. |
| tone | Reemplazar texto o tonos (ej., "omg" → "oh my god"). |
| timbre_weights | Requerido si no se usa voice_id. Hasta 4 timbres mezclados. |
| voice_id | ID de timbre para mezclar. |
| weight | 1–100; proporción de mezcla. |
| stream | Habilitar salida en streaming (por defecto false). |
| language_boost | Mejorar rendimiento para un idioma/dialecto, ej., chino, inglés, japonés, auto. |
| output_format | hex (por defecto) o url; url solo en modo no streaming. |
| voice_modify | Efectos de voz post-procesamiento. |
| pitch | -100 a 100; más oscuro ↔ más brillante. |
| intensity | -100 a 100; más fuerte ↔ más suave. |
| timbre | -100 a 100; magnético ↔ nítido. |
| sound_effects | spacious_echo, auditorium_echo, lofi_telephone, robotic. |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
¡Prueba MiniMax Speech 2.6 ahora!
¿Soporta MiniMax Speech 2.6 streaming?
Sí. MiniMax Speech 2.5 soporta streaming tanto para reconocimiento de voz (ASR) como para texto a voz (TTS). La API incluye explícitamente el campo:
"stream": true
en una solicitud TTS, el sistema comienza a generar audio inmediatamente y lo envía en segmentos. Esto permite que la reproducción comience antes de que se sintetice la oración completa. La latencia típica de inicio del TTS está dentro de unos pocos segundos, y los escenarios optimizados pueden alcanzar tiempos de respuesta de extremo a extremo inferiores al segundo.
¿Cómo usar MiniMax Speech 2.5 a buen precio?
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de Modelos.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
¡Prueba MiniMax Speech 2.6 ahora!
Paso 3: Comienza tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresa a la página “Configuración” y copia la clave API como se indica en la imagen.

MiniMax Speech 2.6 ofrece nuevas capacidades: latencia inferior a 250 ms, prosodia multilingüe sin interrupciones, clonación expresiva con Fluent LoRA y formato automático para URLs, correos electrónicos, números y fechas, habilitando aplicaciones de voz en tiempo real, multimodales y ricas en datos que MiniMax Speech 2.5 no puede soportar de manera confiable. Mientras tanto, Speech 2.5 sigue siendo la opción estable y rentable para contenido de formato largo y generación TTS por lotes. Juntos, los dos modelos forman un pipeline complementario: Speech 2.6 para diálogo interactivo y Speech 2.5 para producción de contenido escalable.
Preguntas frecuentes
¿Qué hace que MiniMax Speech 2.6 sea más adecuado para aplicaciones en tiempo real que MiniMax Speech 2.5?
MiniMax Speech 2.6 ofrece latencia <250 ms y streaming más estable, mientras que MiniMax Speech 2.5 tiene mayor demora y es más adecuado para TTS síncrono.
¿Cómo mejora MiniMax Speech 2.6 la salida multilingüe en comparación con MiniMax Speech 2.5?
MiniMax Speech 2.6 fortalece la prosodia entre idiomas, la estabilidad del acento y la fluidez en idiomas mixtos, mientras que MiniMax Speech 2.5 maneja texto multilingüe pero con cambios menos naturales.
¿La clonación de voz es más expresiva en MiniMax Speech 2.6 que en MiniMax Speech 2.5?
Sí. MiniMax Speech 2.6 utiliza Fluent LoRA y un codificador de hablante entrenado conjuntamente para una mayor coherencia emocional, mientras que MiniMax Speech 2.5 proporciona una clonación sólida pero menos expresiva.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. API integradas, sin servidor, instancias GPU — las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



