

Speech 2.6 不僅是 2.5 的高品質後繼版本,更支援了 2.5 無法穩定運作的整類即時、多模態、數據感知應用。
對於選擇生產環境 TTS/語音代理後端的開發者而言,關鍵問題並非哪個模型「聽起來」更好,而是哪個模型能拓展你的產品能做到的事的邊界。本文將透過開發者實際遇到的痛點——自訂語音、即時代理、多語言體驗、長篇內容、多模態數據讀取、成本控制——來對比兩個模型,並說明 Speech 2.6 如何突破多項應用限制。
MiniMax Speech 2.6 模型版本對比
| 維度 | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| 主要目標 | 低延遲與成本效率 | 最高保真度與表現力 |
| 端到端延遲 | 典型句子 < 250 毫秒 | 短句約 0.8–1.0 秒 |
| 吞吐量 | 長文本優於即時;針對串流優化 | 吞吐量較低;針對品質優化 |
| 串流支援 | 支援;數百毫秒內輸出第一個音訊標記 | 部分支援;支援中等長度輸入的即時處理 |
| 韻律品質 | 標準韻律;優先考量速度 | 強化韻律、微細節、流暢情緒支援 |
| 多語言能力 | 40+ 種語言;無縫切換 | 40+ 種語言,自然度提升 |
| 情緒風格 | 支援(基礎) | 支援,表現力更強 |
| 定價 | 每 1000 字元 $0.06 | 每 1000 字元 $0.10 |
| 最佳適用場景 | 互動代理、聊天機器人、串流對話 | 配音、有聲書、錄音室級旁白 |
為何 Speech 2.6 終於能實現即時語音代理?
Speech 2.6 低於 250 毫秒的延遲與穩定的串流功能,開啟了 Speech 2.5 無法支援的流暢語音互動工作流程。
即時互動是 2.5 與 2.6 之間最大的差距。開發客服機器人、店內助手或語音 UI 功能的開發者經常反饋,Speech 2.5 的延遲雖然能滿足同步 TTS 的需求,但對於真正的對話來說還是太慢了。
Speech 2.6 透過重新設計解碼管線與串流排程器解決了這個問題,將往返延遲降低到 250 毫秒以內,從使用者角度來看對話切換幾乎是瞬時的。這項改動讓模型從內容生成器轉型為適合生產環境代理的互動語音層。開發者不再需要繞過延遲做額外處理,或是加入人工停頓;這個模型終於符合對話的時序要求。
Speech 2.6 帶來了哪些新的多語言能力?
Speech 2.6 優化了跨語言韻律,讓多語言代理能在單次語音輸出中自然切換語言。
對於全球應用而言,開發者需要中英文混合、東南亞市場、多語言客戶流程中的發音準確度。Speech 2.6 優化了跨語言韻律,並讓克隆語音在 40+ 種語言中保持穩定。
| 功能 | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| 語言數量 | 40+ | 40+ |
| 代碼切換(中英混說) | 良好 | 流暢自然 |
| 口音保留 | 穩定 | 跨語言更穩定 |
| 混合格式讀取 | 有限 | 穩健、支援地域設定 |
Speech 2.6 如何改進自訂語音克隆?
Speech 2.6 能輸出表現力更強、情緒連貫的克隆語音,實現品牌與創作者的長期語音所有權。
開發 AI 網紅、學習平台、角色扮演代理或品牌虛擬形象的開發者,需要一致、可重用的語音身份。Speech 2.5 引入了使用可學習說話人編碼器的零樣本克隆功能,是個性化內容的重大里程碑。
聯合訓練的說話人編碼器 這個與主變壓器聯合訓練的可學習說話人編碼器,即使沒有參考音訊的文本,也能達到業界領先的語音克隆保真度。訓練過程中接觸多種語言,能讓語音保持一致的音色、口音穩定,以及穩健的多語言表現。
用於快速語音適配的流暢 LoRA 流暢 LoRA 提供高效的低秩適配,用於細粒度的語音自訂。即使是不完美的參考樣本(包含口音偏差或背景噪音),也能轉換為清晰流暢的合成語音,適合在多元環境中快速部署。
Speech 2.6 無需預處理即可讀取哪些新的多模態數據類型?
Speech 2.6 引入了智能格式化功能,開發者可以直接輸入原始 URL、郵件、數字、貨幣、日期,无需正則清理。
在實際應用中——儀表板、警報、CRM 更新、物流通知、RAG 管線——TTS 經常需要讀取結構化數據。Speech 2.5 只能逐字讀取這類內容,導致尷尬的逐字母拼讀或發音錯誤。
Speech 2.6 內建文本正規化功能,會自動解析 URL、電話號碼、IP 地址、貨幣和時間戳格式。這大幅減少了預處理工作量,開發者能將 TTS 直接整合到動態多模態流程中,例如朗讀分析儀表板、或用多種語言播報電子商務通知。例如輸入「$1,234.56」會自動讀成「one thousand two hundred thirty-four dollars and fifty-six cents」,而「192.168.1.1」這樣的 IP 地址會自動轉為「one nine two dot one six eight dot one dot one」,无需你手動拼讀。這極大提升了技術或財務報表讀取的準確度,是 MiniMax Speech 2.6 的獨特優勢。
| 數據類型 | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URL | 逐字讀取 | 正確、符合語境 |
| 郵件 | 經常讀錯 | 自然、分段感知 |
| 日期、時間 | 不一致 | 依地域設定穩定輸出 |
| 貨幣 / 數字 | 基礎功能 | 智能數字格式化 |
開發者該如何選擇使用哪個語音模型,以及對應時機?
Speech 2.6 最適合以下場景
- 開發即時對話代理的開發者
- 需要多語言混說的應用
- 需要表現力強的克隆語音的產品
- 需要讀取結構化多模態數據(URL、郵件、數字)的系統
- 要求擬人化情緒語調的 UX 流程
Speech 2.5 最適合以下場景
- 生成大批量長篇 TTS的平臺
- 教育內容、有聲書、腳本影片
- 成本敏感、產量可預測的管線
- 對表現力要求不高、需要穩定語音輸出的場景
生產環境中逐漸形成的開發者使用模式
- Speech 2.6 處理互動、即時、多語言或數據豐富的流程。
- Speech 2.5 處理長篇、批次或大規模旁白。
- 最穩健的部署方案會結合兩者:
- Speech 2.6 用於即時對話
- Speech 2.5 用於內容生成
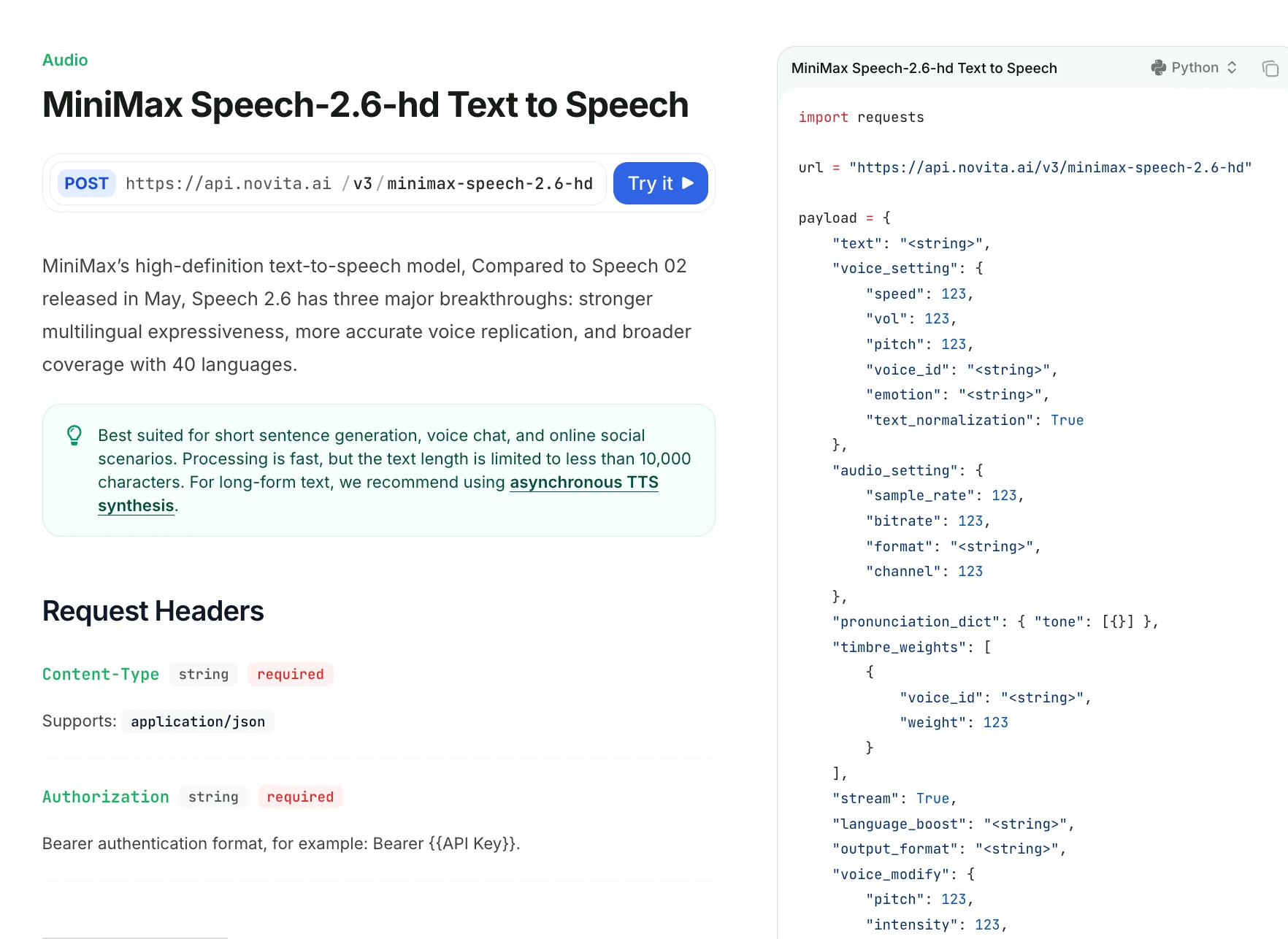
Speech 2.6 對發音、重音和停頓的控制粒度有多細?
| 欄位 | 說明 |
|---|---|
| text | 要合成的文本(<10000 字元)。支援 <#x#> 停頓標記(x 為秒數)。不可使用連續停頓標記。 |
| voice_setting | 控制語速、音量、音高、音色 ID、情緒與正規化。 |
| speed | 0.5–2.0;語速(預設 1.0) |
| vol | 0–10;音訊音量(預設 1.0) |
| pitch | -12 到 12;音高偏移(單位為半音) |
| voice_id | 音色 ID;系統或克隆語音。未使用 timbre_weights 時必填。 |
| emotion | 可選:happy、sad、angry、fearful、disgusted、surprised、neutral |
| text_normalization | 英文文本正規化(預設 false) |
| audio_setting | 控制音訊輸出品質 |
| sample_rate | 可選:8000–44100(預設 32000) |
| bitrate | 僅 mp3 格式;32000–256000(預設 128000) |
| format | mp3 / pcm / flac / wav(wav 不支援串流) |
| channel | 1(單聲道)或 2(立體聲);預設 1 |
| pronunciation_dict | 自訂發音規則;支援中文聲調覆蓋 |
| tone | 替換文本或聲調(例如 "omg" → "oh my god") |
| timbre_weights | 未使用 voice_id 時必填。最多混合 4 種音色 |
| oice_id | 用於混合的音色 ID |
| weight | 1–100;混合比例 |
| stream | 啟用串流輸出(預設 false) |
| language_boost | 提升特定語言/方言的表現,例如 Chinese、English、Japanese、auto |
| output_format | hex(預設)或 url;僅非串流模式下支援 url |
| voice_modify | 後處理語音特效 |
| pitch | -100 到 100;低沉 ↔ 明亮 |
| ntensity | -100 到 100;強勁 ↔ 柔和 |
| timbre | -100 到 100;磁性 ↔ 清脆 |
| sound_effects | spacious_echo、auditorium_echo、lofi_telephone、robotic |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
MiniMax Speech 2.6 是否支援串流?
是的。MiniMax Speech 2.5 的 語音識別(ASR) 和 文字轉語音(TTS) 都支援串流功能。API 明確包含以下欄位:
"stream": true
在 TTS 請求中加入此欄位,系統會立即開始生成音訊,並分段返回。這讓播放可以在完整句子合成完成前就開始。一般 TTS 啟動延遲在幾秒鐘內,優化後的情景可達到秒級以內的端到端回應時間。
如何以優惠價格使用 MiniMax Speech 2.5?
步驟 1:登入並進入模型庫
登入你的帳號,點擊 模型庫 按鈕。

步驟 2:選擇模型
瀏覽可用的選項,選擇符合你需求的模型。
步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
步驟 4:獲取 API 金鑰
要進行 API 認證,我們會提供給你新的 API 金鑰。進入「設定」頁面,即可按照圖片指示複製 API 金鑰。

MiniMax Speech 2.6 帶來了全新能力——低於 250 毫秒的延遲、無縫多語言韻律、流暢 LoRA 表現力克隆、以及 URL、郵件、數字、日期的自動格式化——能實現 MiniMax Speech 2.5 無法穩定支援的即時、多模態、數據豐富的語音應用。與此同時,Speech 2.5 依然是長篇內容與大批量 TTS 生成的穩定、高性價比選擇。兩個模型互補:Speech 2.6 用於互動對話,Speech 2.5 用於可擴展的內容生產。
常見問題
為什麼 MiniMax Speech 2.6 比 2.5 更適合即時應用? MiniMax Speech 2.6 延遲低於 250 毫秒,串流更穩定;而 MiniMax Speech 2.5 延遲較高,更適合同步 TTS 場景。
相比 MiniMax Speech 2.5,MiniMax Speech 2.6 如何改進多語言輸出? MiniMax Speech 2.6 強化了跨語言韻律、口音穩定性和混合語言流暢度;而 MiniMax Speech 2.5 雖能處理多語言文本,但切換自然度較低。
MiniMax Speech 2.6 的語音克隆表現力是否比 2.5 更強? 是的。MiniMax Speech 2.6 使用流暢 LoRA 和聯合訓練的說話人編碼器,情緒連貫性更高;而 MiniMax Speech 2.5 的克隆效果穩固,但表現力較弱。
Novita AI 是全能雲端平台,助力你實現 AI 抱負。整合 API、無伺服器、GPU 實例——你需要的工具。免除基礎設施負擔,免費開始,將你的 AI 願景化為現實。



