

- Сравнение вариантов модели MiniMax Speech 2.6
- Почему Speech 2.6 наконец делает голосовых агентов для работы в реальном времени работоспособными?
- Какие новые многоязычные возможности появляются в Speech 2.6?
- Как Speech 2.6 улучшает клонирование пользовательских голосов?
- Какие новые типы данных нескольких модальностей может читать Speech 2.6 без предварительной обработки?
- Какую модель речи должны использовать разработчики и когда?
- Насколько тонкий контроль над произношением, акцентом и паузами предоставляет Speech 2.6?
- Поддерживает ли MiniMax Speech 2.6 потоковую передачу?
- Как использовать MiniMax Speech 2.5 по выгодной цене?
Speech 2.6 — это не просто более качественный преемник версии 2.5; он открывает целые классы приложений для работы в реальном времени, с поддержкой нескольких модальностей и обработкой данных, которые версия 2.5 не могла поддерживать стабильно.
Для разработчиков, выбирающих бэкенд для синтеза речи/голосовых агентов в продакшене, ключевой вопрос не в том, какая модель «звучит» лучше, а в том, какая из них расширяет границы возможностей вашего продукта. В этой статье мы рассматриваем обе модели через призму конкретных проблем разработчиков: пользовательские голоса, агенты для работы в реальном времени, многоязычные решения, контент большого объема, чтение данных нескольких модальностей и контроль затрат, а также объясняем, как Speech 2.6 снимает несколько ограничений для приложений.
Сравнение вариантов модели MiniMax Speech 2.6
| Параметр | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| Основная цель | Низкая задержка и эффективность затрат | Максимальная точность и выразительность |
| Сквозная задержка | < 250 мс для типичных предложений | ~0,8–1,0 с для коротких предложений |
| Пропускная способность | Выше скорости реального времени для длинного текста; оптимизирована для потоковой передачи | Ниже пропускная способность; оптимизирована для качества |
| Поддержка потоковой передачи | Да; первые аудио-токены поступают в течение нескольких сотен мс | Частичная; поддерживает работу в реальном времени для входных данных средней длины |
| Качество просодии | Стандартная просодия; приоритет скорости | Улучшенная просодия, микродетали, поддержка Fluent Emotion |
| Многоязычные возможности | 40+ языков; бесшовное переключение | 40+ языков с улучшенной естественностью |
| Стили эмоций | Поддерживаются (базовые) | Поддерживаются с более высокой выразительностью |
| Цена | $0,06 за 1000 символов | $0,10 за 1000 символов |
| Лучшие сценарии использования | Интерактивные агенты, чат-боты, потоковый диалог | Озвучка, аудиокниги, озвучка студийного качества |
Почему Speech 2.6 наконец делает голосовых агентов для работы в реальном времени работоспособными?
Задержка менее 250 мс и стабилизированная потоковая передача Speech 2.6 открывают возможности для естественных рабочих процессов голосового взаимодействия, которые Speech 2.5 не может поддерживать.
Работа в реальном времени — это самое большое различие между версиями 2.5 и 2.6. Разработчики, создающие ботов для службы поддержки клиентов, помощников для магазинов или функции голосового интерфейса, часто сообщали, что задержка Speech 2.5, хотя и приемлема для синхронного синтеза речи, кажется слишком большой для настоящего диалога.
Speech 2.6 решает эту проблему за счет перепроектирования конвейера декодирования и планировщика потоковой передачи, сокращая задержку туда-обратно до менее 250 мс и делая смену говорящего практически мгновенной с точки зрения пользователя. Это изменение превращает модель из генератора контента в интерактивный голосовой уровень, подходящий для продакшн-агентов. Разработчикам больше не нужно обходить задержки обходными путями или добавлять искусственные паузы; модель наконец соответствует таймингам разговора.
Попробуйте MiniMax Speech 2.6 сейчас!
Какие новые многоязычные возможности появляются в Speech 2.6?
Speech 2.6 улучшает межъязыковую просодию, что позволяет многоязычным агентам естественно переключаться между языками в рамках одного высказывания.
Для глобальных приложений разработчикам нужна точность произношения в смесях китайского и английского языков, на рынках Юго-Восточной Азии и в многоязычных клиентских потоках. Speech 2.6 улучшает межъязыковую просодию и сохраняет стабильность клонированных голосов в более чем 40 языках.
| Функция | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| Количество языков | 40+ | 40+ |
| Переключение между языками | Хорошее | Плавное и естественное |
| Сохранение акцента | Стабильное | Более стабильное при работе с разными языками |
| Чтение смешанных форматов | Ограниченное | Надежное, с учетом локали |
Попробуйте MiniMax Speech 2.6 сейчас!
Как Speech 2.6 улучшает клонирование пользовательских голосов?
Speech 2.6 предоставляет более выразительные, эмоционально согласованные клонированные голоса, что позволяет обеспечивать долгосрочное владение голосом для брендов и создателей контента.
Разработчики, создающие ИИ-инфлюенсеров, обучающие платформы, ролевые агенты или аватары брендов, нуждаются в согласованных, повторно используемых голосовых идентичностях. Speech 2.5 представил клонирование без дополнительного обучения (zero-shot) с использованием обучаемого кодировщика говорящего, что стало важной вехой для персонализированного контента.
Совместно обученный кодировщик говорящего
Обучаемый кодировщик говорящего, обученный совместно с основным трансформером, достигает точности клонирования голоса уровня state-of-the-art без расшифровок эталонного аудио. Обучение на нескольких языках обеспечивает согласованный тембр, стабильность акцента и устойчивое многоязычное поведение.
Fluent LoRA для быстрой адаптации голоса
Fluent LoRA обеспечивает эффективную низкоранговую адаптацию для тонкой настройки голоса. Даже неидеальные эталонные образцы с отклонениями акцента или фоновым шумом могут быть преобразованы в чистые и плавные синтезированные голоса, что позволяет быстро развертывать решения в разнообразных средах.
Попробуйте MiniMax Speech 2.6 сейчас!
Какие новые типы данных нескольких модальностей может читать Speech 2.6 без предварительной обработки?
Speech 2.6 внедряет интеллектуальное форматирование, которое позволяет разработчикам напрямую передавать необработанные URL, адреса электронной почты, числа, валюты и даты без очистки с помощью регулярных выражений.
В реальных приложениях — дашбордах, оповещениях, обновлениях CRM, логистических уведомлениях, конвейерах RAG — синтезу речи часто нужно зачитывать структурированные данные. Speech 2.5 может читать такой контент только буквально, что приводит к неудобному посимвольному произношению или ошибкам в произношении.
Speech 2.6 включает встроенную нормализацию текста, которая автоматически интерпретирует URL, номера телефонов, IP-адреса, валюты и форматы временных меток. Это drastically сокращает объем предварительной обработки и позволяет разработчикам напрямую интегрировать синтез речи в динамические потоки нескольких модальностей, например, для зачитывания аналитических дашбордов или озвучивания уведомлений электронной коммерции на нескольких локалях. Например, входное значение «$1,234.56» будет произнесено как «one thousand two hundred thirty-four dollars and fifty-six cents» автоматически, а IP-адрес вида «192.168.1.1» превратится в «one nine two dot one six eight dot one dot one» без необходимости произносить его по буквам. Это значительно повышает точность при зачитывании технических или финансовых данных и является уникальной сильной стороной MiniMax Speech 2.6.
| Тип данных | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URL | Буквальные символы | Корректное, с учетом контекста |
| Адреса электронной почты | Часто произносятся с ошибками | Естественное, с учетом сегментов |
| Даты, время | Несогласованное | Стабильное в зависимости от локали |
| Валюта / числа | Базовое | Умное числовое форматирование |
Попробуйте MiniMax Speech 2.6 сейчас!
Какую модель речи должны использовать разработчики и когда?
Speech 2.6 лучше всего подходит для
- разработчиков, создающих агенты для диалога в реальном времени,
- приложений, требующих переключения между несколькими языками,
- продуктов, нуждающихся в выразительных клонированных голосах,
- систем, зачитывающих структурированные данные нескольких модальностей (URL, адреса электронной почты, числа),
- UX-потоков, требующих эмоционального тона, близкого к человеческому.
Speech 2.5 лучше всего подходит для
- платформ, генерирующих массовый синтез речи для контента большого объема,
- образовательного контента, аудиокниг, видео по сценарию,
- конвейеров с чувствительными к затратам процессами и предсказуемым объемом,
- стабильных голосовых выходов, где выразительность не является критически важной.
Паттерн использования разработчиками в продакшене
- Speech 2.6 обрабатывает интерактивные, работающие в реальном времени, многоязычные или насыщенные данные потоки.
- Speech 2.5 обрабатывает контент большого объема, пакетные или крупномасштабные задачи озвучки.
- Наиболее надежные развертывания сочетают обе модели:
- Speech 2.6 для живого диалога
- Speech 2.5 для генерации контента
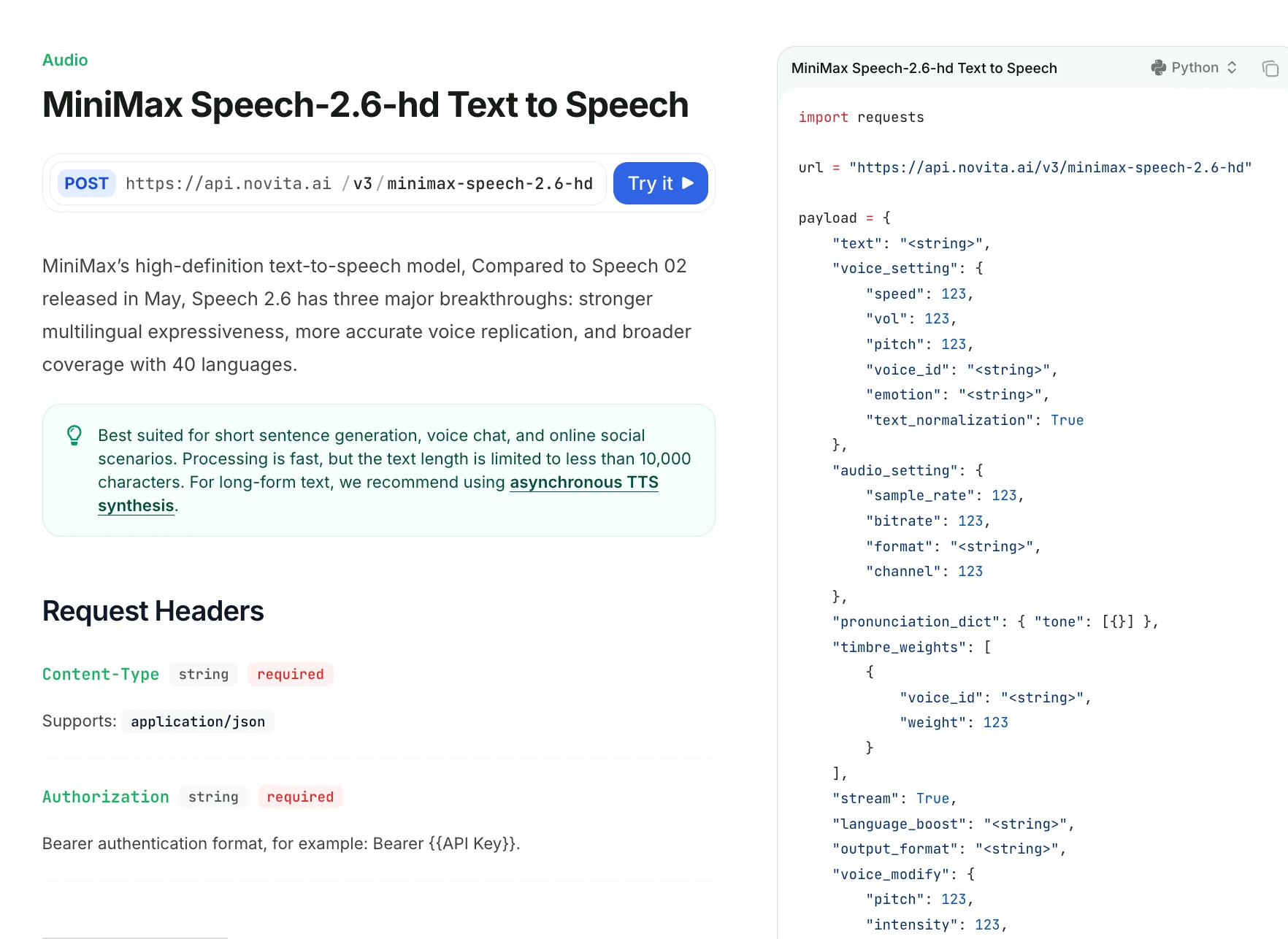
Насколько тонкий контроль над произношением, акцентом и паузами предоставляет Speech 2.6?
| Поле | Описание |
|---|---|
| text | Текст для синтеза (<10 000 символов). Поддерживаются паузы <#x#> (x в секундах). Нельзя использовать последовательные маркеры паузы. |
| voice_setting | Управляет скоростью, громкостью, высотой тона, ID тембра, эмоцией и нормализацией. |
| speed | 0,5–2,0; скорость речи (по умолчанию 1,0). |
| vol | 0–10; громкость аудио (по умолчанию 1,0). |
| pitch | -12 до 12; сдвиг высоты тона в полутонах. |
| voice_id | ID тембра; системные или клонированные голоса. Обязателен, если не используется timbre_weights. |
| emotion | Одно из значений: happy, sad, angry, fearful, disgusted, surprised, neutral. |
| text_normalization | Нормализация английского текста (по умолчанию false). |
| audio_setting | Управляет качеством аудиовыхода. |
| sample_rate | Одно из значений: 8000–44100 (по умолчанию 32000). |
| bitrate | Только для mp3; 32000–256000 (по умолчанию 128000). |
| format | mp3 / pcm / flac / wav (wav не поддерживается для потоковой передачи). |
| channel | 1 (моно) или 2 (стерео); по умолчанию 1. |
| pronunciation_dict | Пользовательские правила произношения; поддерживается переопределение китайских тонов. |
| tone | Замена текста или тонов (например, "omg" → "oh my god"). |
| timbre_weights | Обязателен, если не используется voice_id. До 4 смешанных тембра. |
| oice_id | ID тембра для смешивания. |
| weight | 1–100; коэффициент смешивания. |
| stream | Включить потоковый вывод (по умолчанию false). |
| language_boost | Улучшить производительность для языка/диалекта, например, Chinese, English, Japanese, auto. |
| output_format | hex (по умолчанию) или url; url доступен только в непоточном режиме. |
| voice_modify | Постобработка голосовых эффектов. |
| pitch | -100 до 100; темнее ↔ ярче. |
| ntensity | -100 до 100; сильнее ↔ слабее. |
| timbre | -100 до 100; магнитный ↔ четкий. |
| sound_effects | spacious_echo, auditorium_echo, lofi_telephone, robotic. |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Попробуйте MiniMax Speech 2.6 сейчас!
Поддерживает ли MiniMax Speech 2.6 потоковую передачу?
Да. MiniMax Speech 2.5 поддерживает потоковую передачу как для распознавания речи (ASR), так и для синтеза речи из текста (TTS). API явно включает поле:
"stream": true
в запросе на синтез речи система начинает генерировать аудио немедленно и отправляет его обратно сегментами. Это позволяет начать воспроизведение до того, как будет синтезировано все предложение. Типичная задержка запуска синтеза речи составляет несколько секунд, а в оптимизированных сценариях можно достичь времени отклика сквозной передачи менее одной секунды.
Как использовать MiniMax Speech 2.5 по выгодной цене?
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей
Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2: Выберите нужную модель
Просмотрите доступные варианты и выберите модель, которая подходит для ваших задач.
Попробуйте MiniMax Speech 2.6 сейчас!
Шаг 3: Начните бесплатный пробный период
Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.
Шаг 4: Получите API-ключ
Для аутентификации в API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

MiniMax Speech 2.6 предоставляет новые возможности: задержку менее 250 мс, бесшовную многоязыковую просодию, выразительное клонирование Fluent LoRA и автоматическое форматирование для URL, адресов электронной почты, чисел и дат, что позволяет создавать голосовые приложения для работы в реальном времени, с поддержкой нескольких модальностей и большим объемом данных, которые MiniMax Speech 2.5 не может поддерживать стабильно. При этом Speech 2.5 остается стабильным, экономически эффективным выбором для контента большого объема и массовой генерации синтеза речи. Вместе эти две модели формируют взаимодополняющий конвейер: Speech 2.6 для интерактивного диалога и Speech 2.5 для масштабируемого производства контента.
Часто задаваемые вопросы
Что делает MiniMax Speech 2.6 более подходящим для приложений, работающих в реальном времени, по сравнению с MiniMax Speech 2.5?
MiniMax Speech 2.6 обеспечивает задержку менее 250 мс и более стабильную потоковую передачу, в то время как MiniMax Speech 2.5 имеет более высокую задержку и лучше подходит для синхронного синтеза речи.
Как MiniMax Speech 2.6 улучшает многоязычный вывод по сравнению с MiniMax Speech 2.5?
MiniMax Speech 2.6 улучшает межъязыковую просодию, стабильность акцента и плавность переключения между языками, в то время как MiniMax Speech 2.5 обрабатывает многоязычный текст, но с менее естественным переключением.
Является ли клонирование голоса более выразительным в MiniMax Speech 2.6 по сравнению с MiniMax Speech 2.5?
Да. MiniMax Speech 2.6 использует Fluent LoRA и совместно обученный кодировщик говорящего для более высокой эмоциональной согласованности, в то время как MiniMax Speech 2.5 обеспечивает надежное, но менее выразительное клонирование.
Novita AI — это универсальная облачная платформа, которая помогает реализовать ваши амбиции в области ИИ. Интегрированные API, бессерверные решения, GPU-инстансы — экономически эффективные инструменты, которые вам нужны. Избавьтесь от необходимости управления инфраструктурой, начните бесплатно и воплотите ваше видение ИИ в реальность.



