

- MiniMax Speech 2.6 모델 변형 비교
- Speech 2.6이 마침내 실시간 음성 에이전트를 실현 가능하게 만드는 이유는 무엇인가요?
- Speech 2.6에서 어떤 새로운 다국어 기능이 가능해졌나요?
- Speech 2.6이 커스텀 음성 복제를 어떻게 개선하나요?
- Speech 2.6이 전처리 없이 읽을 수 있는 새로운 멀티모달 데이터 유형은 무엇인가요?
- 개발자는 어떤 음성 모델을 언제 사용해야 할까요?
- Speech 2.6의 발음, 강세, 일시 정지 제어는 얼마나 세밀한가요?
- MiniMax Speech 2.6은 스트리밍을 지원하나요?
- 저렴한 가격에 MiniMax Speech 2.5를 사용하는 방법은?
Speech 2.6은 단순히 2.5의 고품질 후속 모델이 아니라, 2.5가 안정적으로 지원할 수 없었던 실시간, 멀티모달, 데이터 인식 애플리케이션의 전체 클래스를 가능하게 합니다.
프로덕션 TTS/음성 에이전트 백엔드를 선택하는 개발자에게 중요한 질문은 어떤 모델이 더 ‘좋게’ 들리는지가 아니라, ‘제품이 할 수 있는 것’의 경계를 확장하는 모델입니다. 이 글에서는 두 모델을 구체적인 개발자 문제점—커스텀 음성, 실시간 에이전트, 다국어 경험, 장문 콘텐츠, 멀티모달 데이터 읽기, 비용 관리—을 통해 비교하고, Speech 2.6이 어떻게 여러 애플리케이션의 한계를 끌어올리는지 설명합니다.
MiniMax Speech 2.6 모델 변형 비교
| 차원 | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| 주요 목표 | 낮은 지연 시간과 비용 효율성 | 최대 충실도와 표현력 |
| 종단 간 지연 시간 | 일반 문장 < 250ms | 짧은 문장 약 0.8~1.0초 |
| 처리량 | 긴 텍스트에 대해 실시간보다 빠름; 스트리밍에 최적화 | 처리량 낮음; 품질에 최적화 |
| 스트리밍 지원 | 예; 수백 ms 이내에 첫 오디오 토큰 제공 | 부분적; 중간 길이 입력에 대해 실시간 지원 |
| 운율(Prosody) 품질 | 표준 운율; 속도 우선 | 향상된 운율, 미세 디테일, Fluent Emotion 지원 |
| 다국어 기능 | 40개 이상 언어; 원활한 전환 | 40개 이상 언어, 자연스러움 개선 |
| 감정 스타일 | 지원됨 (기본) | 더 높은 표현력으로 지원됨 |
| 가격 | $0.06 / 1,000자 | $0.10 / 1,000자 |
| 최적 사용 사례 | 인터랙티브 에이전트, 챗봇, 스트리밍 대화 | 음성 해설, 오디오북, 스튜디오급 내레이션 |
Speech 2.6이 마침내 실시간 음성 에이전트를 실현 가능하게 만드는 이유는 무엇인가요?
Speech 2.6의 250ms 미만 지연 시간과 안정화된 스트리밍은 Speech 2.5가 지원할 수 없는 자연스러운 음성 상호작용 워크플로를 가능하게 합니다.
실시간 상호작용은 2.5와 2.6 사이의 가장 큰 격차입니다. 고객 서비스 봇, 매장 내 도우미 또는 음성 UI 기능을 구축하는 개발자들은 Speech 2.5의 지연 시간이 동기식 TTS에는 허용되지만 진정한 대화에는 너무 느리다고 자주 보고했습니다.
Speech 2.6은 디코딩 파이프라인과 스트리밍 스케줄러를 재설계하여 왕복 지연 시간을 250ms 미만으로 줄이고, 사용자 관점에서 턴테이킹을 거의 즉각적으로 만듭니다. 이 변화는 모델을 콘텐츠 생성기에서 프로덕션 에이전트에 적합한 인터랙티브 음성 레이어로 전환시킵니다. 개발자는 더 이상 지연 시간을 해결하기 위해 임시방편을 쓰거나 인위적인 멈춤을 추가할 필요가 없습니다. 모델이 마침내 대화 타이밍에 맞춰집니다.
Speech 2.6에서 어떤 새로운 다국어 기능이 가능해졌나요?
Speech 2.6은 교차 언어 운율을 개선하여 다국어 에이전트가 한 문장 내에서 자연스럽게 언어를 전환할 수 있게 합니다.
글로벌 앱의 경우 개발자는 중국어-영어 혼합, 동남아 시장, 다국어 고객 흐름에서 발음 정확도가 필요합니다. Speech 2.6은 교차 언어 운율을 개선하고 40개 이상의 언어에서 복제된 음성을 안정적으로 유지합니다.
| 기능 | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| 언어 수 | 40+ | 40+ |
| 코드 스위칭 | 좋음 | 유창하고 자연스러움 |
| 억양 보존 | 안정적 | 언어 간 더 안정적 |
| 혼합 형식 읽기 | 제한적 | 강력하고 로케일 인식 |
Speech 2.6이 커스텀 음성 복제를 어떻게 개선하나요?
Speech 2.6은 더 표현력 있고 감정적으로 일관된 복제 음성을 제공하여 장기적인 브랜드 및 크리에이터 음성 소유권을 가능하게 합니다.
AI 인플루언서, 학습 플랫폼, 역할극 에이전트 또는 브랜드 아바타를 구축하는 개발자에게는 일관되고 재사용 가능한 음성 정체성이 필요합니다. Speech 2.5는 학습 가능한 화자 인코더를 사용한 제로샷 복제를 도입했으며, 이는 개인화된 콘텐츠의 주요 이정표였습니다.
공동 학습된 화자 인코더
주 트랜스포머와 함께 공동 학습된 학습 가능한 화자 인코더는 기준 오디오의 텍스트 없이도 최첨단 음성 복제 충실도를 달성합니다. 학습 중 여러 언어에 노출되어 일관된 음색, 억양 안정성 및 강력한 다국어 동작을 가능하게 합니다.
Fluent LoRA를 통한 빠른 음성 적응
Fluent LoRA는 세밀한 음성 커스터마이징을 위한 효율적인 저랭크 적응을 제공합니다. 억양 편차나 배경 잡음이 포함된 불완전한 기준 샘플조차 깨끗하고 유창한 합성 음성으로 변환할 수 있어 다양한 환경에서 빠른 배포가 가능합니다.
Speech 2.6이 전처리 없이 읽을 수 있는 새로운 멀티모달 데이터 유형은 무엇인가요?
Speech 2.6은 지능형 포맷팅을 도입하여 개발자가 정규식 정리 없이 원시 URL, 이메일, 숫자, 통화, 날짜를 직접 입력할 수 있게 합니다.
실제 애플리케이션(대시보드, 알림, CRM 업데이트, 물류 알림, RAG 파이프라인)에서 TTS는 종종 구조화된 데이터를 읽어야 합니다. Speech 2.5는 이러한 콘텐츠를 문자 그대로만 읽을 수 있어 어색한 글자별 철자나 잘못된 발음을 초래합니다.
Speech 2.6은 URL, 전화번호, IP 주소, 통화, 타임스탬프 형식을 자동으로 해석하는 내장 텍스트 정규화를 포함합니다. 이는 전처리 작업을 대폭 줄여주며, 개발자가 동적 멀티모달 흐름(예: 분석 대시보드를 소리내어 읽거나 여러 로케일에서 전자상거래 알림을 음성화)에 TTS를 직접 통합할 수 있게 합니다. 예를 들어, 입력 “$1,234.56”은 자동으로 “one thousand two hundred thirty-four dollars and fifty-six cents”로 발음되고, IP 주소 “192.168.1.1”은 “one nine two dot one six eight dot one dot one”으로 변환되어 직접 철자할 필요가 없습니다. 이는 기술적 또는 재무적 판독에서 정확성을 크게 향상시키며 MiniMax Speech 2.6의 고유한 강점입니다.
| 데이터 유형 | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URL | 문자 그대로 | 정확하고 문맥 인식 |
| 이메일 | 종종 잘못 읽음 | 자연스럽고 세그먼트 인식 |
| 날짜, 시간 | 일관성 없음 | 로케일별 안정적 |
| 통화 / 숫자 | 기본 | 스마트 숫자 포맷팅 |
개발자는 어떤 음성 모델을 언제 사용해야 할까요?
Speech 2.6에 가장 적합한 경우
- 실시간 대화형 에이전트를 구축하는 개발자
- 다국어 코드 전환이 필요한 앱
- 표현력 있는 복제 음성이 필요한 제품
- 구조화된 멀티모달 데이터(URL, 이메일, 숫자)를 읽는 시스템
- 인간과 같은 감정 톤이 필요한 UX 흐름
Speech 2.5에 가장 적합한 경우
- 대량 장문 TTS를 생성하는 플랫폼
- 교육 콘텐츠, 오디오북, 대본이 있는 비디오
- 예측 가능한 볼륨으로 비용에 민감한 파이프라인
- 표현력이 덜 중요하지만 안정적인 음성 출력
프로덕션에서 나타나는 개발자 패턴
- Speech 2.6은 인터랙티브, 실시간, 다국어 또는 데이터가 풍부한 흐름을 처리합니다.
- Speech 2.5는 장문, 배치 또는 대규모 내레이션을 처리합니다.
- 가장 강력한 배포는 두 가지를 결합합니다:
- Speech 2.6: 라이브 대화용
- Speech 2.5: 콘텐츠 생성용
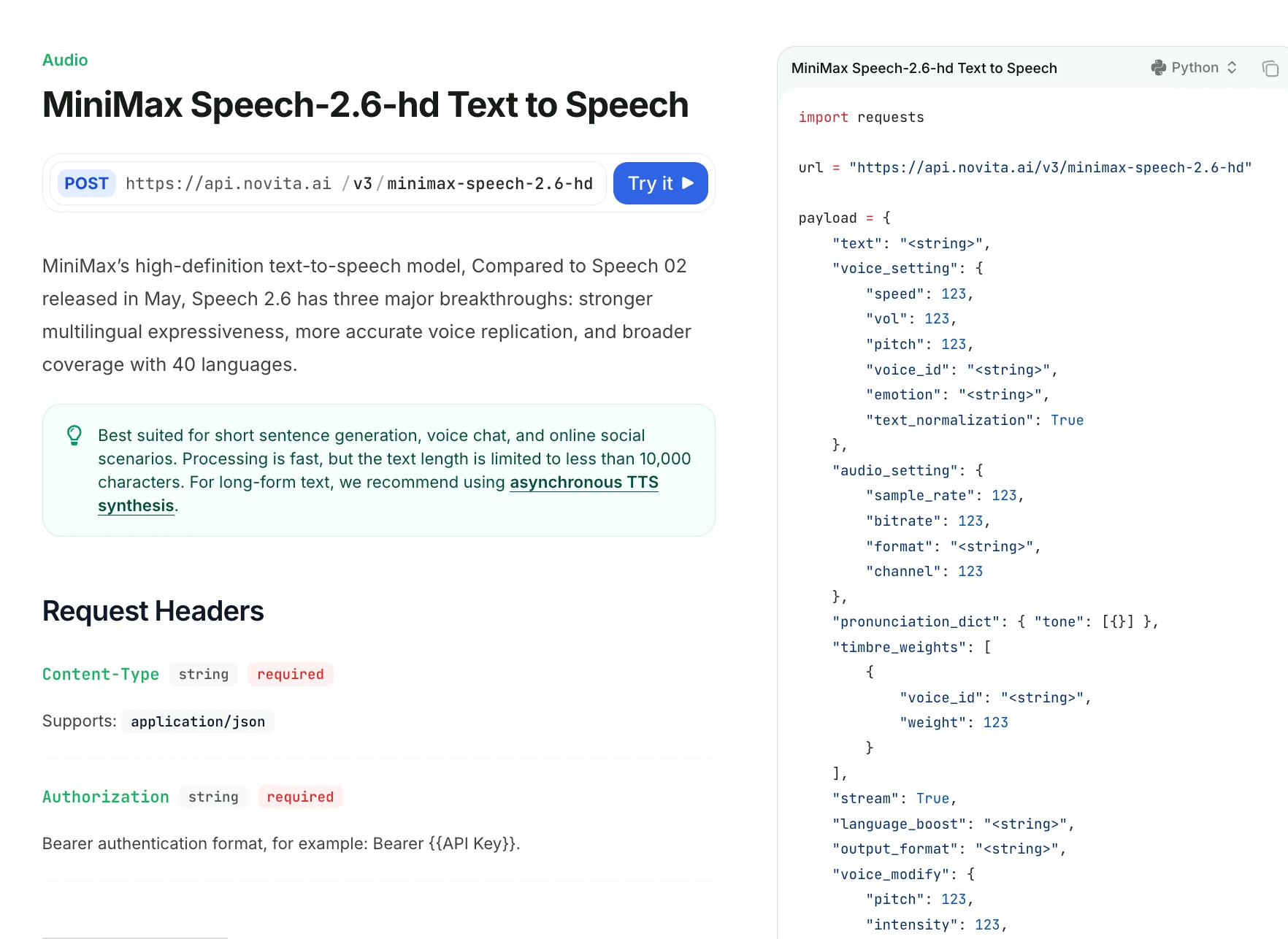
Speech 2.6의 발음, 강세, 일시 정지 제어는 얼마나 세밀한가요?
| 필드 | 설명 |
|---|---|
| text | 합성할 텍스트(<10,000자). <#x#> 일시 정지 지원(x는 초). 연속 일시 정지 마커는 허용되지 않음. |
| voice_setting | 속도, 볼륨, 피치, 음색 ID, 감정, 정규화를 제어합니다. |
| speed | 0.5–2.0; 말하기 속도(기본값 1.0). |
| vol | 0–10; 오디오 음량(기본값 1.0). |
| pitch | -12 ~ 12; 반음 단위 피치 이동. |
| voice_id | 음색 ID; 시스템 또는 복제 음성. timbre_weights를 사용하지 않는 경우 필수. |
| emotion | 다음 중 하나: happy, sad, angry, fearful, disgusted, surprised, neutral. |
| text_normalization | 영어 텍스트 정규화(기본값 false). |
| audio_setting | 오디오 출력 품질을 제어합니다. |
| sample_rate | 8000–44100 중 하나(기본값 32000). |
| bitrate | mp3만 해당; 32000–256000(기본값 128000). |
| format | mp3 / pcm / flac / wav(wav는 스트리밍 불가). |
| channel | 1(모노) 또는 2(스테레오); 기본값 1. |
| pronunciation_dict | 사용자 정의 발음 규칙; 중국어 성조 재정의 지원. |
| tone | 텍스트 또는 성조 대체(예: "omg" → "oh my god"). |
| timbre_weights | voice_id를 사용하지 않는 경우 필수. 최대 4개의 혼합 음색. |
| voice_id | 혼합할 음색 ID. |
| weight | 1–100; 혼합 비율. |
| stream | 스트리밍 출력 활성화(기본값 false). |
| language_boost | 특정 언어/방언(예: 중국어, 영어, 일본어, auto)에 대한 성능 향상. |
| output_format | hex(기본값) 또는 url; url은 비스트림 모드에서만 가능. |
| voice_modify | 후처리 음성 효과. |
| pitch | -100 ~ 100; 어둡게 ↔ 밝게. |
| intensity | -100 ~ 100; 강하게 ↔ 부드럽게. |
| timbre | -100 ~ 100; 자기적 ↔ 선명하게. |
| sound_effects | spacious_echo, auditorium_echo, lofi_telephone, robotic. |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
MiniMax Speech 2.6은 스트리밍을 지원하나요?
네. MiniMax Speech 2.5는 **음성 인식(ASR)**과 텍스트 음성 변환(TTS) 모두에 대해 스트리밍을 지원합니다. API에는 명시적으로 다음 필드가 포함됩니다:
"stream": true
TTS 요청에서 이 필드를 활성화하면 시스템이 즉시 오디오 생성을 시작하고 세그먼트 단위로 반환합니다. 이를 통해 전체 문장이 합성되기 전에 재생을 시작할 수 있습니다. 일반적인 TTS 시작 지연 시간은 몇 초 이내이며, 최적화된 시나리오에서는 1초 미만의 종단 간 응답 시간을 달성할 수 있습니다.
저렴한 가격에 MiniMax Speech 2.5를 사용하는 방법은?
1단계: 로그인 및 모델 라이브러리 접속
계정에 로그인하고 모델 라이브러리 버튼을 클릭합니다.

2단계: 모델 선택
사용 가능한 옵션을 살펴보고 필요에 맞는 모델을 선택합니다.
3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하기 위해 무료 체험을 시작합니다.
4단계: API 키 받기
API 인증을 위해 새 API 키를 제공해 드립니다. “설정” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

MiniMax Speech 2.6은 250ms 미만의 지연 시간, 원활한 다국어 운율, Fluent LoRA 표현형 복제, URL, 이메일, 숫자, 날짜에 대한 자동 포맷팅 등 새로운 기능을 제공하여 MiniMax Speech 2.5가 안정적으로 지원하지 못했던 실시간, 멀티모달, 데이터가 풍부한 음성 애플리케이션을 가능하게 합니다. 한편 Speech 2.5는 장문 콘텐츠 및 대량 TTS 생성을 위한 안정적이고 비용 효율적인 선택으로 남아 있습니다. 두 모델은 함께 상호 보완적인 파이프라인을 형성합니다: Speech 2.6은 인터랙티브 대화용, Speech 2.5는 확장 가능한 콘텐츠 생산용입니다.
자주 묻는 질문
MiniMax Speech 2.6이 MiniMax Speech 2.5보다 실시간 애플리케이션에 더 적합한 이유는 무엇인가요?
MiniMax Speech 2.6은 250ms 미만의 지연 시간과 더 안정적인 스트리밍을 제공하는 반면, MiniMax Speech 2.5는 지연 시간이 더 높고 동기식 TTS에 더 적합합니다.
MiniMax Speech 2.6은 MiniMax Speech 2.5에 비해 다국어 출력을 어떻게 개선하나요?
MiniMax Speech 2.6은 교차 언어 운율, 억양 안정성 및 혼합 언어 유창성을 강화하는 반면, MiniMax Speech 2.5는 다국어 텍스트를 처리하지만 자연스러운 전환은 덜합니다.
MiniMax Speech 2.6의 음성 복제가 MiniMax Speech 2.5보다 더 표현력이 있나요?
네. MiniMax Speech 2.6은 Fluent LoRA와 공동 학습된 화자 인코더를 사용하여 더 높은 감정적 일관성을 제공하는 반면, MiniMax Speech 2.5는 견고하지만 덜 표현력 있는 복제를 제공합니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구를 제공합니다. 인프라를 제거하고, 무료로 시작하며, AI 비전을 현실로 만드세요.



