

Speech 2.6 不仅仅是 2.5 的高质量升级版;它实现了 2.5 无法可靠支持的整个类别的实时、多模态和数据感知应用。
对于选择生产级 TTS/语音代理后端的开发者来说,关键问题不是哪个模型“听起来”更好,而是哪个模型扩展了你的产品能做什么的边界。本文通过具体的开发者痛点——自定义语音、实时代理、多语言体验、长内容、多模态数据读取和成本控制——来对比两个模型,并解释 Speech 2.6 如何提升多个应用上限。
MiniMax Speech 2.6 模型变体对比
| 维度 | Speech 2.6 Turbo | Speech 2.6 HD |
|---|---|---|
| 主要目标 | 低延迟与成本效益 | 最高保真度与表现力 |
| 端到端延迟 | 典型句子 < 250 ms | 短句子约 0.8–1.0 秒 |
| 吞吐量 | 长文本快于实时;针对流式优化 | 吞吐量较低;针对质量优化 |
| 流式支持 | 是;几百毫秒内输出首个音频 token | 部分支持;中等长度输入可实时 |
| 韵律质量 | 标准韵律;优先考虑速度 | 增强的韵律、微细节、支持 Fluent Emotion |
| 多语言能力 | 40+ 种语言;无缝切换 | 40+ 种语言,自然度更优 |
| 情感风格 | 支持(基础) | 支持,表现力更高 |
| 定价 | $0.06 / 1,000 字符 | $0.10 / 1,000 字符 |
| 最佳用例 | 交互式代理、聊天机器人、流式对话 | 配音、有声书、录音室级旁白 |
为什么 Speech 2.6 最终让实时语音代理变得可行?
Speech 2.6 的亚 250 毫秒延迟和稳定的流式输出,实现了 Speech 2.5 无法支持的自然语音交互工作流。
实时交互是 2.5 与 2.6 之间最大的差距。构建客服机器人、店内助手或语音 UI 功能的开发者经常反馈,Speech 2.5 的延迟虽然对于同步 TTS 可以接受,但对于真正的对话来说感觉太慢。
Speech 2.6 通过重新设计解码流水线和流式调度器解决了这个问题,将往返延迟降低到 250 毫秒以下,使得轮换从用户角度看几乎是即时的。这一变化将模型从内容生成器转变为适合生产代理的交互式语音层。开发者不再需要变通地应对延迟或添加人为停顿;模型终于符合对话的节奏。
Speech 2.6 实现了哪些新的多语言功能?
Speech 2.6 改进了跨语言韵律,使得多语言代理能够在单次话语中自然切换语言。
对于全球应用,开发者需要中英混合、东南亚市场以及多语言客户流中的发音准确性。Speech 2.6 改进了跨语言韵律,并在 40+ 种语言中保持克隆语音的稳定性。
| 特性 | Speech 2.5 | Speech 2.6 HD |
|---|---|---|
| 语言数量 | 40+ | 40+ |
| 代码切换 | 良好 | 流畅自然 |
| 口音保留 | 稳定 | 跨语言更稳定 |
| 混合格式读取 | 有限 | 稳健,且具备地域感知能力 |
Speech 2.6 如何改进自定义语音克隆?
Speech 2.6 提供更具表现力、情感一致的克隆语音,支持长期品牌和创作者语音所有权。
构建 AI 网红、学习平台、角色扮演代理或品牌形象的开发者需要一致且可复用的语音身份。Speech 2.5 通过可学习的说话人编码器引入了零样本克隆,这是个性化内容的一个重要里程碑。
联合训练的说话人编码器
可学习的说话人编码器与主 Transformer 联合训练,在没有参考音频转录的情况下实现了最先进的语音克隆保真度。训练过程中接触多种语言,使得音色一致、口音稳定且多语言行为鲁棒。
Fluent LoRA 快速语音适配
Fluent LoRA 提供了高效的低秩适配,用于细粒度的语音定制。即使包含口音偏差或背景噪音的不完美参考样本,也能转换为干净流畅的合成语音,实现快速部署到多样环境中。
Speech 2.6 无需预处理即可读取哪些新的多模态数据类型?
Speech 2.6 引入了智能格式化,允许开发者直接输入原始 URL、电子邮件、数字、货币和日期,无需正则清理。
在实际应用中——仪表盘、警报、CRM 更新、物流通知、RAG 流水线——TTS 经常需要读取结构化数据。Speech 2.5 只能逐字读取这些内容,导致尴尬的逐个字母拼读或发音错误。
Speech 2.6 包含内置的文本归一化,可自动解释 URL、电话号码、IP 地址、货币和时间戳格式。这大大减少了预处理工作,使开发者能够将 TTS 直接集成到动态多模态流程中,例如大声读取分析仪表盘或为多语言区域的电子商务通知配音。例如,输入 “$1,234.56” 会被自动读作 “one thousand two hundred thirty-four dollars and fifty-six cents”,而 IP 地址 “192.168.1.1” 会变成 “one nine two dot one six eight dot one dot one”,无需你手动拼写。这显著提升了技术或财务数据读取的准确性,这也是 MiniMax Speech 2.6 的独特优势。
| 数据类型 | Speech 2.5 | Speech 2.6 |
|---|---|---|
| URL | 逐个字符 | 正确,且具备上下文感知 |
| 电子邮件 | 经常读错 | 自然,按段识别 |
| 日期、时间 | 不一致 | 按区域稳定读取 |
| 货币/数字 | 基础 | 智能数字格式化 |
开发者应该在何时使用哪种语音模型?
Speech 2.6 最适合
- 构建实时对话代理的开发者
- 需要多语言代码切换的应用
- 需要富有表现力的克隆语音的产品
- 读取结构化多模态数据(URL、电子邮件、数字)的系统
- 需要类人情感语调的用户体验流程
Speech 2.5 最适合
- 生成批量长文 TTS 的平台
- 教育内容、有声书、剧本视频
- 成本敏感且可预测音量的流水线
- 表现力要求较低的稳定语音输出
生产中出现的开发者模式
- Speech 2.6 处理交互式、实时、多语言或数据密集型流程。
- Speech 2.5 处理长文、批量或大规模旁白。
- 最稳健的部署将两者结合:
- Speech 2.6 用于实时对话
- Speech 2.5 用于内容生成
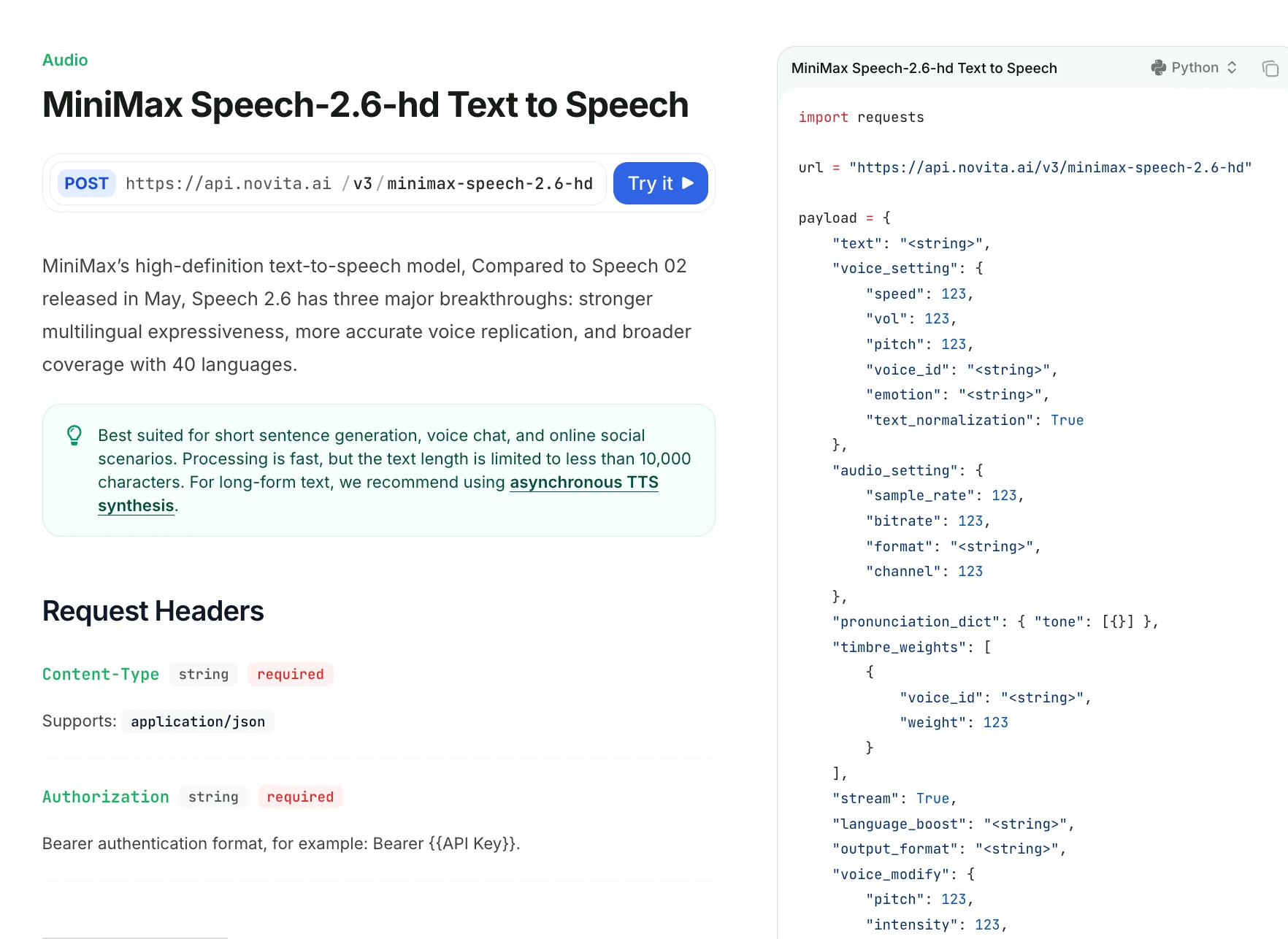
Speech 2.6 在发音、重音和停顿方面的控制有多精细?
| 字段 | 描述 |
|---|---|
| text | 要合成的文本(<10,000 字符)。支持 <#x#> 停顿(x 为秒)。不能有连续的停顿标记。 |
| voice_setting | 控制语速、音量、音调、音色 ID、情感和归一化。 |
| speed | 0.5–2.0;语速(默认 1.0)。 |
| vol | 0–10;音频响度(默认 1.0)。 |
| pitch | -12 到 12;半音移调。 |
| voice_id | 音色 ID;系统或克隆语音。除非使用 timbre_weights,否则必填。 |
| emotion | 可选:happy, sad, angry, fearful, disgusted, surprised, neutral。 |
| text_normalization | 英文文本归一化(默认 false)。 |
| audio_setting | 控制音频输出质量。 |
| sample_rate | 可选:8000–44100(默认 32000)。 |
| bitrate | 仅 mp3;32000–256000(默认 128000)。 |
| format | mp3 / pcm / flac / wav(wav 不支持流式)。 |
| channel | 1(单声道)或 2(立体声);默认 1。 |
| pronunciation_dict | 自定义发音规则;支持中文声调覆盖。 |
| tone | 替换文本或音调(例如 "omg" → "oh my god")。 |
| timbre_weights | 如果未使用 voice_id 则必填。最多混合 4 种音色。 |
| voice_id | 用于混合的音色 ID。 |
| weight | 1–100;混合比例。 |
| stream | 启用流式输出(默认 false)。 |
| language_boost | 提升某种语言/方言的效果,例如 Chinese, English, Japanese, auto。 |
| output_format | hex(默认)或 url;仅非流式模式支持 url。 |
| voice_modify | 后处理语音特效。 |
| pitch | -100 到 100;暗 ↔ 亮。 |
| intensity | -100 到 100;强 ↔ 柔。 |
| timbre | -100 到 100;磁 ↔ 清爽。 |
| sound_effects | spacious_echo, auditorium_echo, lofi_telephone, robotic。 |
import requests
url = "https://api.novita.ai/v3/minimax-speech-2.6-hd"
payload = {
"text": "Hello <#0.5#> this is a MiniMax Speech 2.6 HD test example.",
"voice_setting": {
"speed": 1.1,
"vol": 1.0,
"pitch": 0,
"voice_id": "Elegant_Man",
"emotion": "neutral",
"text_normalization": False
},
"audio_setting": {
"sample_rate": 32000,
"bitrate": 128000,
"format": "mp3",
"channel": 1
},
"pronunciation_dict": {
"tone": [
{ "AI": "A I" }
]
},
"timbre_weights": [
{ "voice_id": "Elegant_Man", "weight": 80 }
],
"stream": True,
"language_boost": "English",
"output_format": "hex",
"voice_modify": {
"pitch": 0,
"intensity": 0,
"timbre": 0,
"sound_effects": "none"
}
}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
MiniMax Speech 2.6 支持流式吗?
是的。MiniMax Speech 2.5 支持语音识别 (ASR) 和文本转语音 (TTS) 的流式输出。API 明确包含字段:
"stream": true
在 TTS 请求中,系统立即开始生成音频并分段返回。这使得播放可以在整个句子合成完成之前开始。典型的 TTS 启动延迟在几秒内,优化场景可达亚秒级端到端响应时间。
如何以优惠价格使用 MiniMax Speech 2.5?
步骤 1:登录并访问模型库
登录您的账户,点击模型库按钮。

步骤 2:选择模型
浏览可用选项,选择适合您需求的模型。
步骤 3:开始免费试用
开始免费试用,探索所选模型的功能。
步骤 4:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入"设置"页面,您可以按图中所示复制 API 密钥。

MiniMax Speech 2.6 提供了新能力——亚 250 毫秒延迟、无缝的多语言韵律、Fluent LoRA 表现力克隆,以及 URL、电子邮件、数字和日期的自动格式化——实现了 MiniMax Speech 2.5 无法可靠支持的实时、多模态和富数据语音应用。同时,Speech 2.5 仍然是长内容和批量 TTS 生成的稳定、高性价比选择。两者共同构成互补流水线:Speech 2.6 用于交互式对话,Speech 2.5 用于可扩展的内容生产。
常见问题
是什么让 MiniMax Speech 2.6 比 MiniMax Speech 2.5 更适合实时应用?
MiniMax Speech 2.6 提供 <250 毫秒延迟和更稳定的流式输出,而 MiniMax Speech 2.5 延迟较高,更适合同步 TTS。
MiniMax Speech 2.6 在多语言输出方面相比 MiniMax Speech 2.5 有哪些改进?
MiniMax Speech 2.6 增强了跨语言韵律、口音稳定性和混合语言流畅度,而 MiniMax Speech 2.5 虽然也能处理多语言文本,但自然切换能力较弱。
MiniMax Speech 2.6 的语音克隆是否比 MiniMax Speech 2.5 更具表现力?
是的。MiniMax Speech 2.6 使用 Fluent LoRA 和联合训练的说话人编码器,实现更高的情感一致性,而 MiniMax Speech 2.5 提供扎实但表现力较弱的克隆。
Novita AI 是一个一站式云平台,助力您的 AI 雄心。集成 API、无服务器、GPU 实例——您所需的高性价比工具。消除基础设施,免费开始,让您的 AI 愿景成为现实。



