

- O Que É Ling-2.6-flash?
- Arquitetura Linear Híbrida: Como Ling-2.6-flash Fica Mais Rápido em Escala
- Eficiência de Tokens: 15M vs. 110M para Resolver os Mesmos Benchmarks
- Resultados de Benchmark: Onde Ling-2.6-flash Lidera
- Tabela de Comparação Rápida
- Acesse Ling-2.6-flash com Suporte do Novita AI
- O Que a Comunidade Está Dizendo
- Quem Deve Usar Ling-2.6-flash?
- Comece Agora
- Perguntas Frequentes
As contas de tokens de agentes estão disparando: chamadas de ferramentas em várias etapas, planejamento com contexto longo e saídas estendidas transformam o que parece um preço barato por token em uma fatura mensal muito cara. A resposta da indústria — cadeias de raciocínio mais longas para aumentar os escores de benchmarks — piora a economia, não melhora.
Ling-2.6-flash é um tipo diferente de modelo. Construído em torno de uma arquitetura híbrida de atenção linear, ele atinge até 340 tokens/s em hardware 4× H20, oferece 2,2× o throughput de prefill do Nemotron-3-Super e usa apenas ~15M tokens de saída para completar o Artificial Analysis Intelligence Index — cerca de um décimo do que o Nemotron-3-Super consome. Em resumo: Ling-2.6-flash é um modelo MoE de 104B (7.4B ativos) com janela de contexto de 256K, otimizado para cargas de trabalho de agentes onde velocidade, custo e estabilidade importam mais do que um único benchmark de destaque. Agora disponível no Novita AI.
O Que É Ling-2.6-flash?
Ling-2.6-flash é um modelo de linguagem esparso Mixture-of-Experts com 104B parâmetros totais e 7.4B parâmetros ativos por forward pass. Desenvolvido pela equipe Ling (InclusionAI), é projetado como um modelo da categoria “Instant” — otimizado para implantações de agentes em produção onde o consumo de tokens e a latência são custos reais, não apenas manchetes de benchmarks.
- 104B total / 7.4B ativos — arquitetura MoE com alta esparsidade
- Janela de contexto de 256K tokens — habilitada por atenção linear híbrida
- Pico de throughput de 340 tokens/s em 4× H20 (TP=4)
- Híbrido 1:7 MLA + Lightning Linear attention — 4× throughput em contextos longos
- Principais benchmarks de agentes — lidera em BFCL-V4 (67.04), PinchBench (81.10), IFBench (58.10), Multi-IF Turn-3 (74.85)
- Variantes BF16, FP8 e INT4 — lançamento open-source planejado via Linghe
- Validado em produção — ~100B tokens diários no OpenRouter dias após o lançamento
Arquitetura Linear Híbrida: Como Ling-2.6-flash Fica Mais Rápido em Escala
A maioria dos modelos MoE combina atenção transformer padrão com uma camada FFN esparsa. Ling-2.6-flash substitui a maior parte da atenção por uma camada Lightning Linear, criando um híbrido 1:7 MLA + Lightning Linear. O custo da atenção cresce linearmente com o comprimento do contexto, em vez de quadraticamente — crítico para longas sessões de agentes.
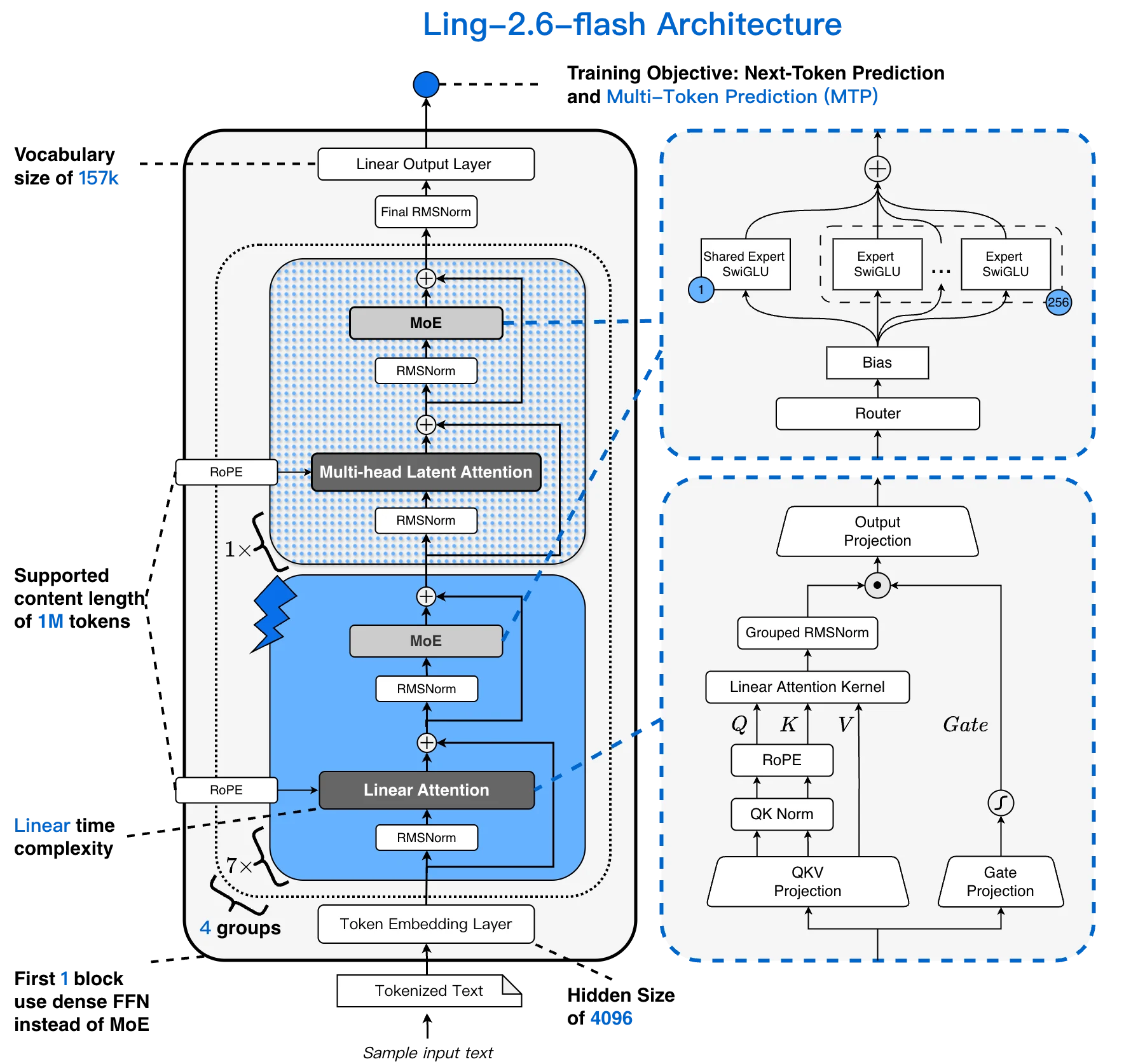
Arquitetura Ling-2.6-flash: vocabulário de 157K, contexto de 256K, híbrido 1:7 MLA + Lightning Linear, 256 especialistas selecionáveis [Fonte: Blog Oficial Ling]
Throughput de Decodificação: Até 4,38× em Saídas Longas
Em 4× H20-3e (TP=4, batch size 32), Ling-2.6-flash atinge 4,38× o throughput de decodificação normalizado em comprimento de saída de 65.536 tokens em comparação com a baseline GLM-4.5-Air. Qwen3.5-122B-A10B atinge 1,90×; Nemotron-3-Super 3,37×. A lacuna se amplia à medida que o comprimento da saída da tarefa aumenta.
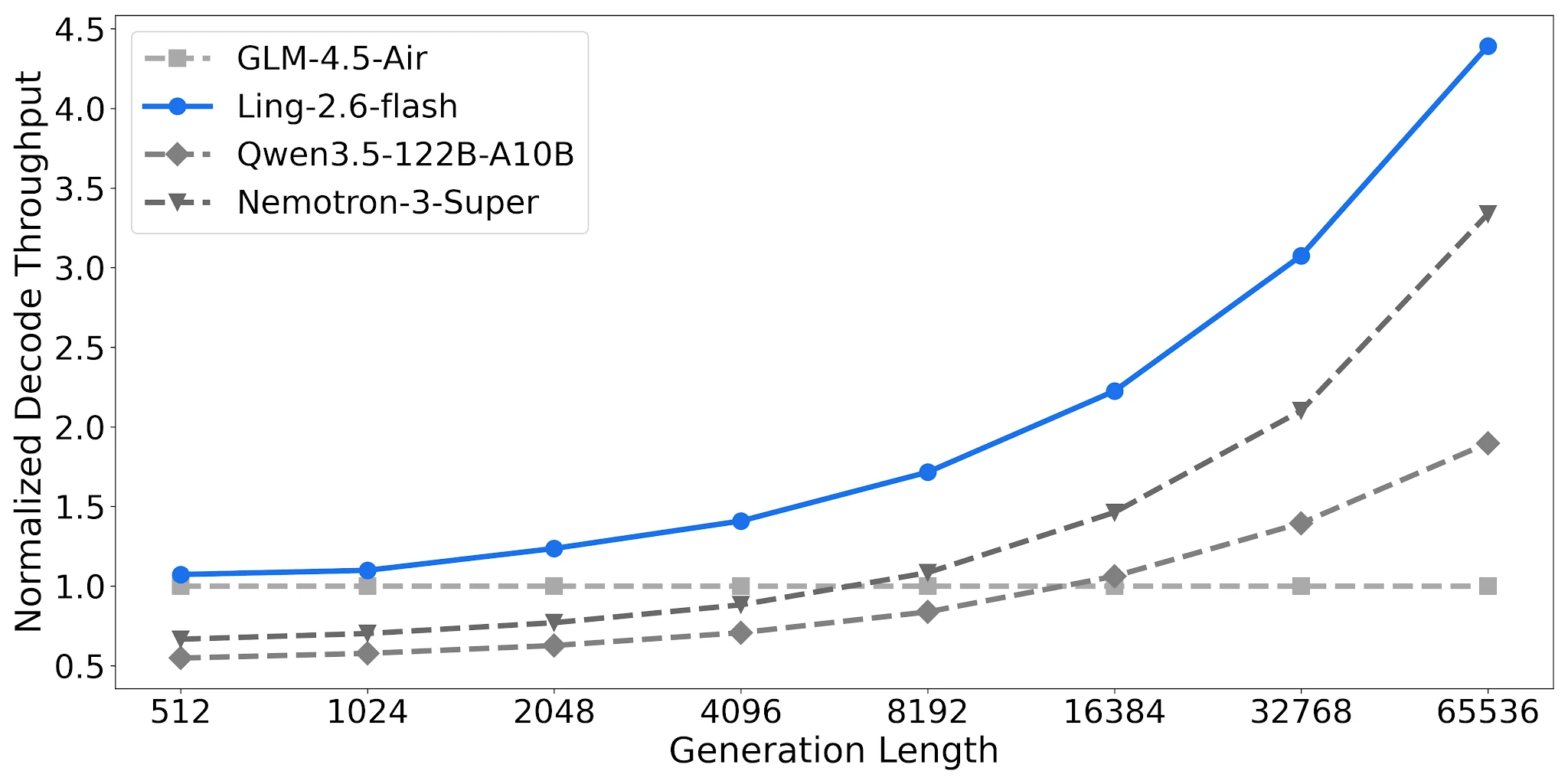
Comparação de Throughput de Decodificação, 4× H20-3e, TP=4, Batch=32 [Fonte: Blog Oficial Ling]
Throughput de Prefill: 2,2× Nemotron em Contextos Longos
Ling-2.6-flash atinge ~4,68× o throughput de prefill normalizado em contexto de 65K vs. ~2,12× para Nemotron-3-Super. Para pipelines de RAG e agentes de múltiplas rodadas com prompts de sistema longos, isso reduz diretamente o custo por requisição.
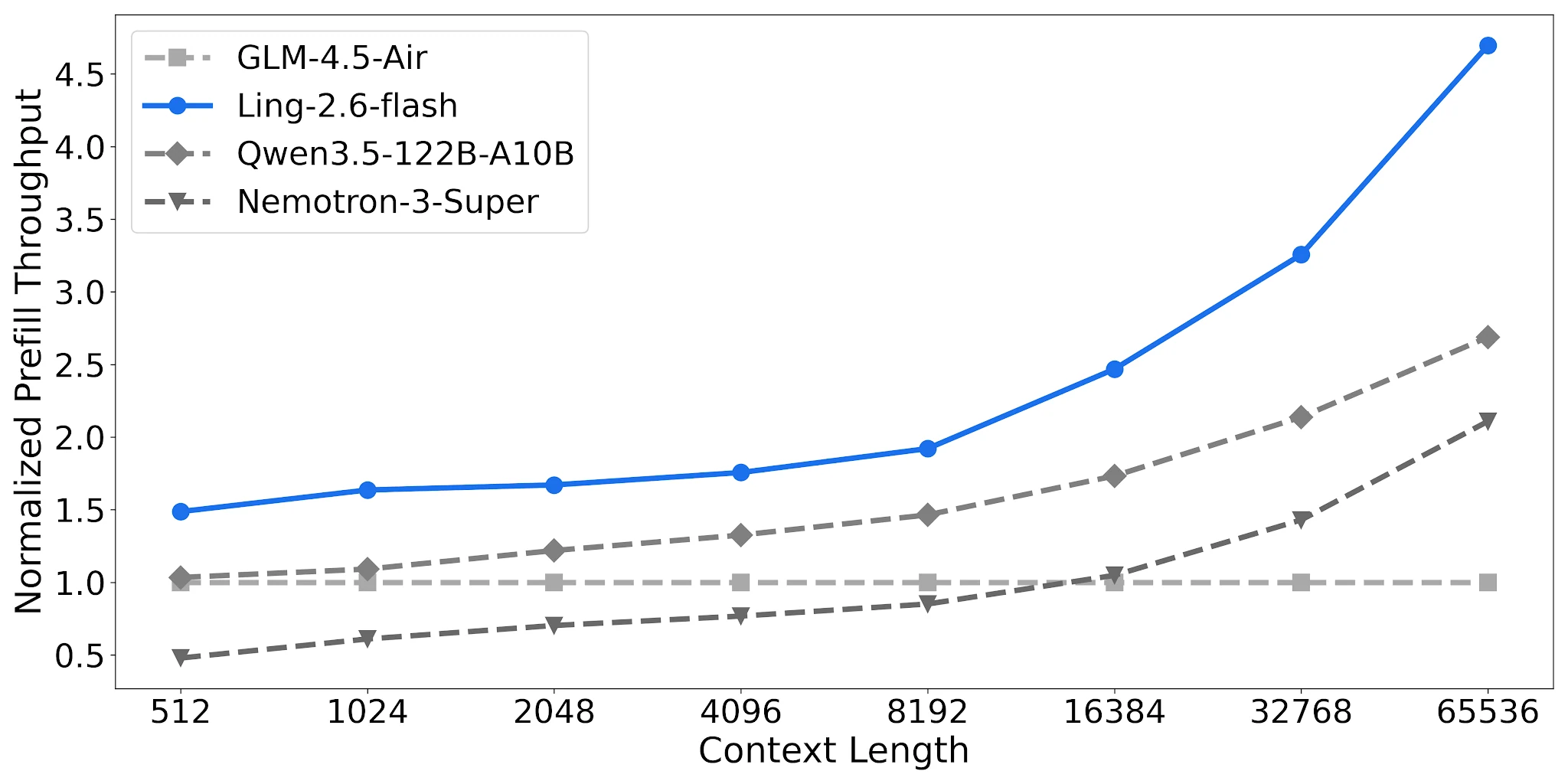
Comparação de Throughput de Prefill, 4× H20-3e, TP=4, Batch=32 [Fonte: Blog Oficial Ling]
Eficiência de Tokens: 15M vs. 110M para Resolver os Mesmos Benchmarks
No Artificial Analysis Intelligence Index completo, Ling-2.6-flash usa ~15M tokens de saída. Nemotron-3-Super usa 110M+ — cerca de 7× mais — para um modelo que pontua mais baixo em tarefas de agente. Para aplicações que executam centenas de milhares de tarefas de agente diariamente, essa lacuna é um item direto no orçamento de custo.
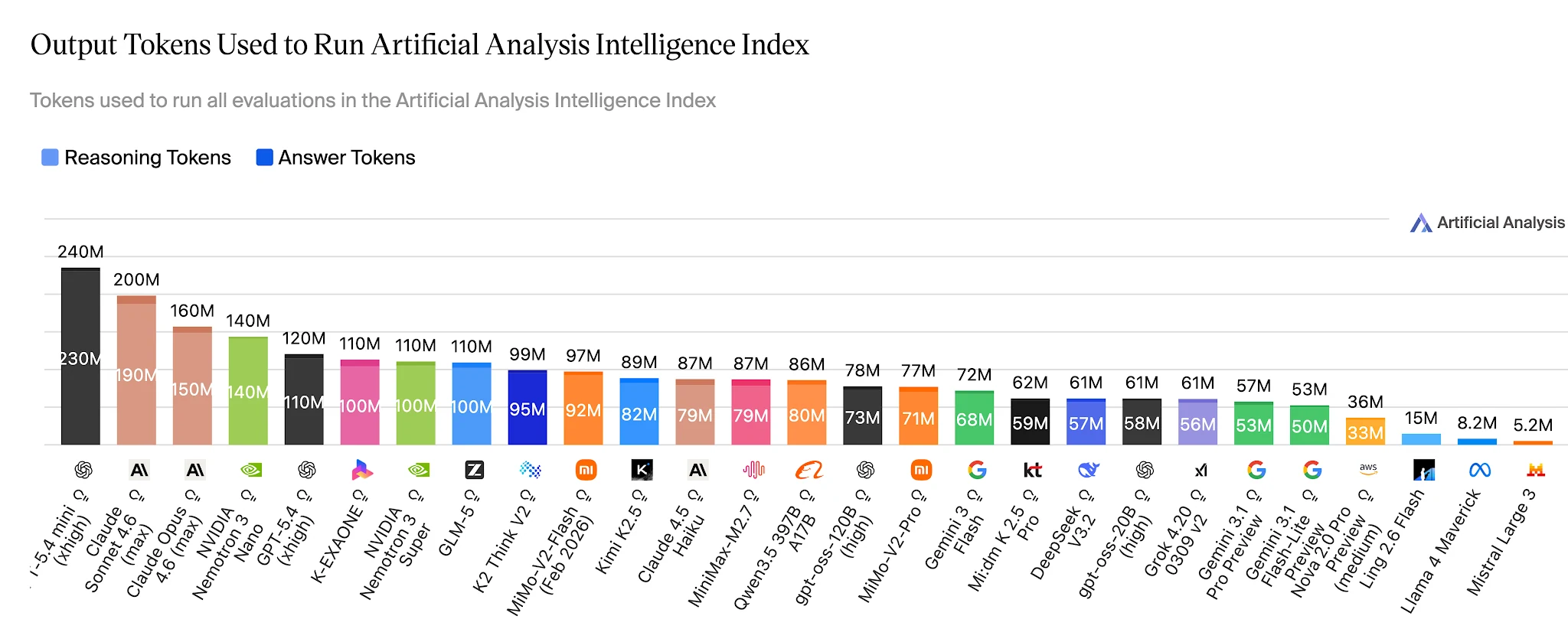
Tokens de saída para completar o Artificial Analysis Intelligence Index — Ling 2.6 Flash: ~15M vs Nemotron-3-Super: ~110M+ [Fonte: Artificial Analysis]
Inteligência vs. Tokens de Saída: Ling 2.6 Flash está na zona de alta eficiência [Fonte: Artificial Analysis]
Resultados de Benchmark: Onde Ling-2.6-flash Lidera
Avaliado em 19 benchmarks em 7 categorias contra Qwen3-57B-A14B, Qwen3.5-122B-A10B, GLM-4.5-Air, Nemotron-3-Super e MiniMax-M1-80k:
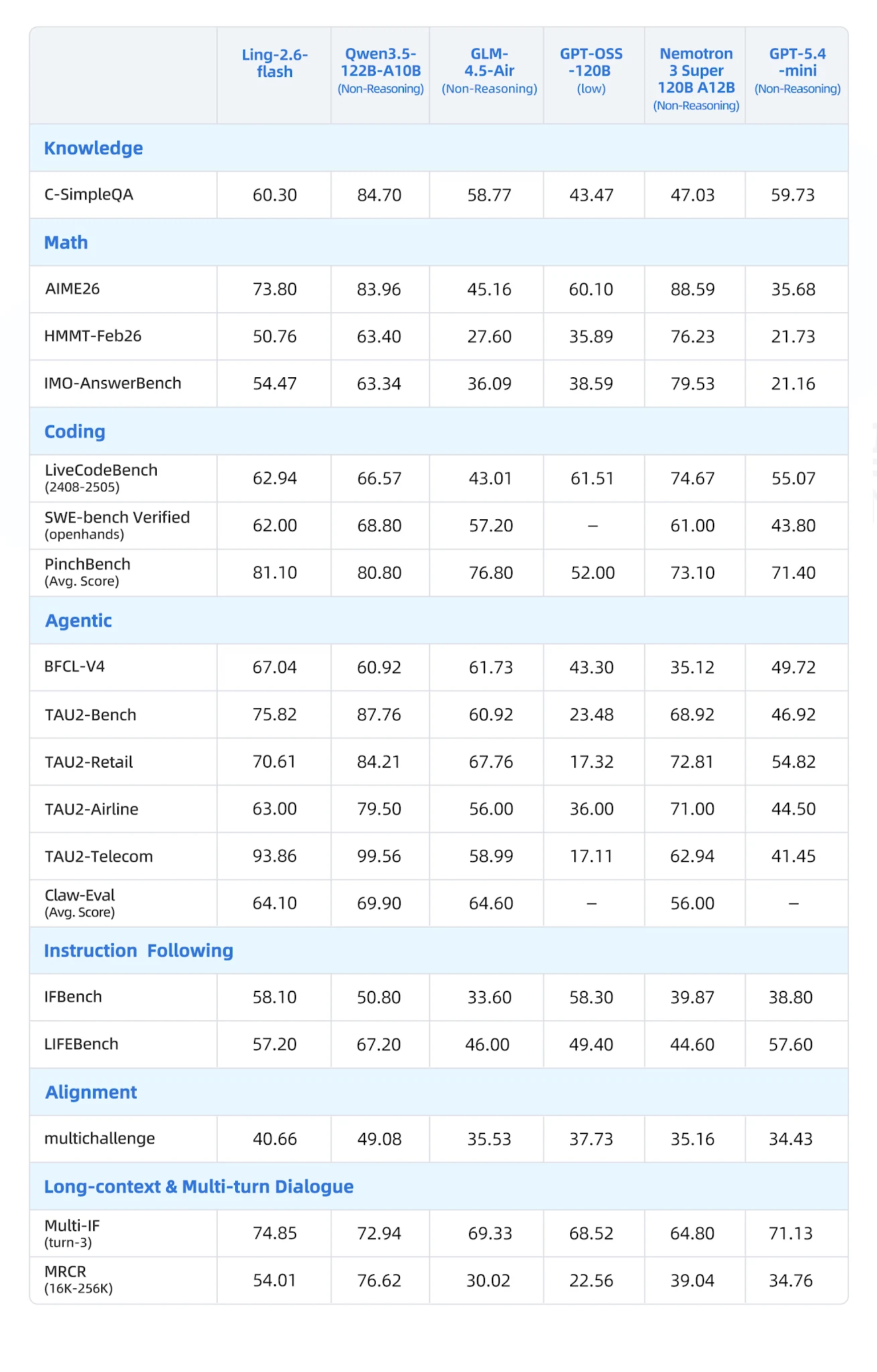
Tabela abrangente de benchmarks [Fonte: Blog Oficial Ling]
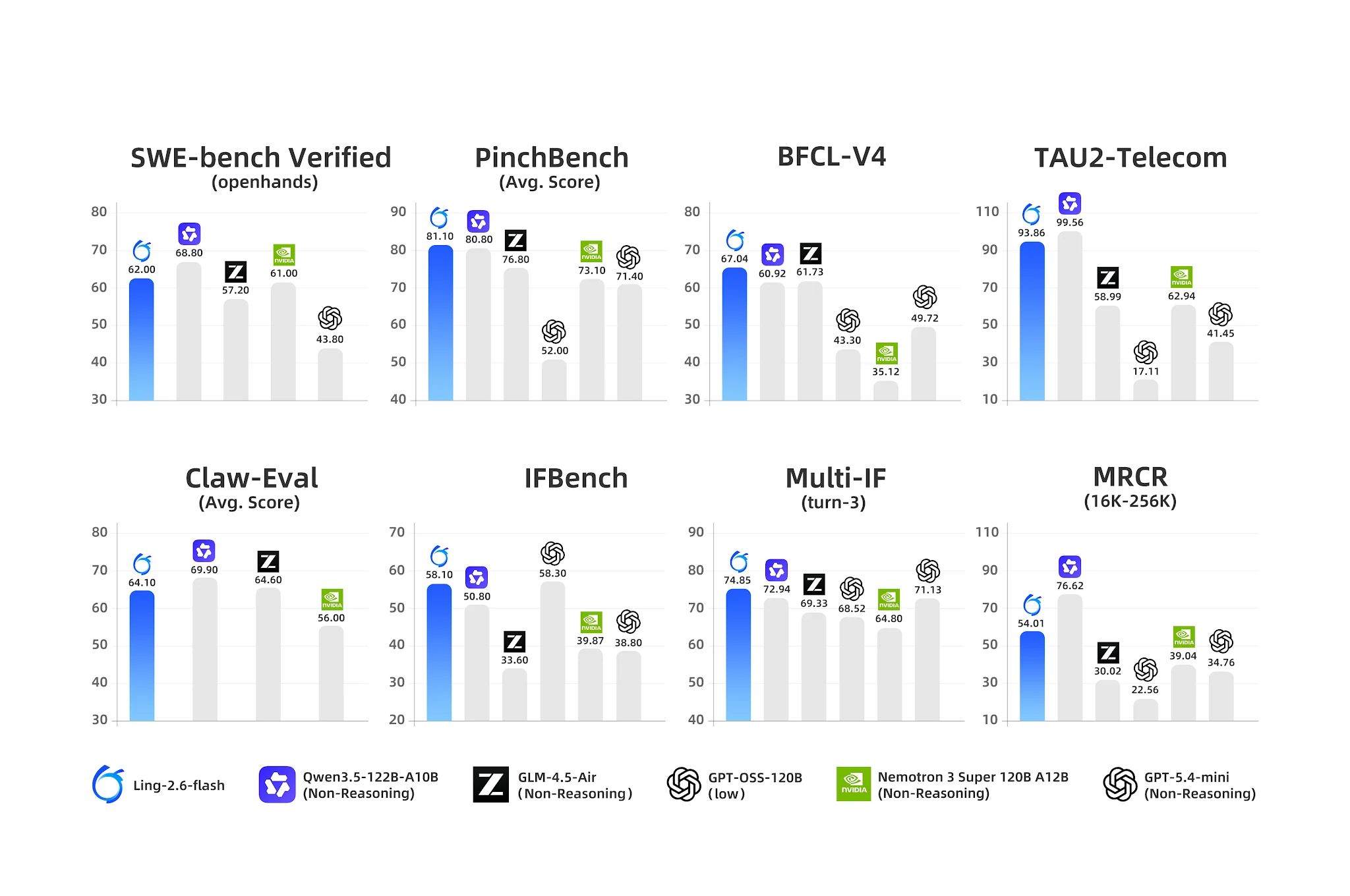
Benchmarks de agente: Ling-2.6-flash lidera em uso de ferramentas e IF multi-turno [Fonte: Blog Oficial Ling]
Onde Ling-2.6-flash Lidera
- BFCL-V4 (Function Calling): 67,04 — concorrente mais próximo Nemotron com 35,12 (diferença de 90%)
- PinchBench (Tarefas de Agente): 81,10 vs. Nemotron 73,10
- IFBench (Instrução Seguinte): 58,10
- Multi-IF Turn-3: 74,85 — forte persistência de instrução em múltiplas rodadas
- LongBench-v2: 54,80 — melhor na categoria de contexto longo
- CCAlignBench (Chinês): 7,44 — melhor entre todos os modelos testados
Onde Outros Lideram
- Matemática (AIME 2025, MATH-500): Nemotron-3-Super e variantes de raciocínio Qwen3 vencem
- Codificação (LiveCodeBench): Qwen3.5-122B-A10B lidera; Ling é competitivo, mas não o melhor
- GPQA-Diamond: GLM-4.5-Air e Nemotron pontuam mais alto
Tabela de Comparação Rápida
| Modelo | Parâmetros Ativos | BFCL-V4 ↑ | PinchBench ↑ | TP Decodificação @ 65K ↑ | Tokens de Saída ↓ |
|---|---|---|---|---|---|
| Ling-2.6-flash | 7,4B | 67,04 | 81,10 | 4,38× | ~15M |
| Nemotron-3-Super | 49B total | 35,12 | 73,10 | 3,37× | ~110M+ |
| Qwen3.5-122B-A10B | 10B | — | 78,20 | 1,90× | — |
| GLM-4.5-Air | — | 50,67 | 73,30 | 1,00× (baseline) | — |
| MiniMax-M1-80k | — | 44,07 | 75,70 | — | — |
| Qwen3-57B-A14B | 14B | 52,32 | 76,30 | — | — |
Acesse Ling-2.6-flash com Suporte do Novita AI
Ling-2.6-flash está disponível agora. Experimente no OpenRouter — nível gratuito, sem configuração necessária:
Comece no OpenRouter — inclusionai/ling-2.6-flash:free. Nível gratuito disponível, nenhuma alteração de código necessária para clientes compatíveis com OpenAI.
Ling-2.6-flash funciona com LangChain, LlamaIndex e OpenAI Agent SDK — sem necessidade de adaptador ou alteração de código. Streaming, chamada de funções e saídas estruturadas são todas suportadas. Combine com o Novita Agent Sandbox para execução segura de código junto com inferência.
O Que a Comunidade Está Dizendo
Ling-2.6-flash foi lançado no OpenRouter como “Elephant Alpha” antes da revelação oficial. Em poucos dias, processou ~100B tokens e liderou o ranking de tendências da plataforma — sem qualquer anúncio.
“Ling-2.6-flash é meio voltado para o trabalho. Cerca de 75% menos prolixo que modelos grandes. Ainda tem um pouco de texto padrão, mas quando se trata de escrever código — é quase perfeito.”
— Usuário inicial no X/Twitter
“Acabei de testar Ling-2.6-flash em algumas tarefas de codificação com llama.cpp. Muito melhor do que esperava. Lida com chamadas de ferramentas de forma confiável e não enche a saída com explicações desnecessárias.”
— Usuário inicial no Reddit
O comentário “75% menos prolixo” corresponde exatamente à diferença de 15M vs. 110M tokens nos benchmarks do Artificial Analysis. O objetivo de treinamento parece recompensar respostas diretas e completas — uma propriedade que se acumula em economia de custos em escala de produção.
Quem Deve Usar Ling-2.6-flash?
- ✅ Agentes de chamada de função / uso de ferramentas de alto volume — liderança ampla no BFCL-V4
- ✅ Sessões de agente com múltiplas rodadas — consistente ao longo de históricos de conversa longos
- ✅ Pipelines de RAG com contexto longo — janela de 256K tokens, prefill de custo linear
- ✅ Implantações de produção sensíveis a custo — ~7× menos tokens de saída que Nemotron
- ✅ Aplicações em chinês — melhor CCAlignBench
- ❌ Raciocínio matemático / estilo AIME — use Nemotron ou variantes de raciocínio Qwen3
- ❌ Máximo desempenho em benchmarks de codificação — Qwen3.5-122B-A10B lidera
Comece Agora
Ling-2.6-flash está disponível agora. Acesse via página do modelo no OpenRouter — nível gratuito disponível imediatamente, sem necessidade de alterações de código para clientes compatíveis com OpenAI. O Agent Sandbox está disponível para equipes que combinam inferência e execução segura.
Perguntas Frequentes
O que é Ling-2.6-flash?
Ling-2.6-flash é um modelo MoE de 104B (7.4B ativos) com atenção linear híbrida, janela de contexto de 256K e velocidade de inferência de até 340 tokens/s — otimizado para cargas de trabalho de agentes.
Como usar Ling-2.6-flash via API?
Use OpenRouter com sua chave de API do Novita AI (BYOK). Adicione sua chave Novita em openrouter.ai/settings/integrations, selecione Novita como provedor e direcione requisições para inclusionai/ling-2.6-flash:free via endpoint compatível com OpenAI:
POST https://openrouter.ai/api/v1/chat/completions
Authorization: Bearer SUA_CHAVE_OPENROUTER_API
{
"model": "inclusionai/ling-2.6-flash:free",
"provider": {
"order": ["Novita"],
"api_key": "SUA_CHAVE_NOVITA_API"
},
"messages": [{"role": "user", "content": "Olá!"}]
}
Veja a documentação BYOK do OpenRouter para configuração completa. Ao usar BYOK, o OpenRouter não cobra taxas — você paga diretamente ao Novita com preços do nível gratuito.
Como Ling-2.6-flash se compara ao Nemotron-3-Super?
Ling lidera em BFCL-V4 (67,04 vs 35,12), PinchBench (81,10 vs 73,10) e usa ~7× menos tokens de saída. Nemotron lidera em matemática. Para cargas de trabalho de agentes, Ling-2.6-flash é a melhor escolha econômica.
Qual é a janela de contexto?
256K tokens (262.144), com prefill de custo linear graças à atenção linear híbrida. Sessões longas de RAG e múltiplas rodadas escalam eficientemente.
Ling-2.6-flash é open source?
Variantes BF16, FP8 e INT4, além dos kernels Linghe, estão planejadas para lançamento open-source. Cronograma a definir — confira o site oficial do Ling para atualizações.
Você Também Pode Gostar
- Kimi K2.6: Agente Open-Source para Sessões de Codificação de 13 Horas — modelo MoE de 1T com contexto de 256K e 58,6% no SWE-Bench Pro
- GLM-5.1 API no Novita AI: Modelo Agente de Longo Horizonte — lidera SWE-Bench Pro com 58,4, executa tarefas de codificação autônomas por 8 horas
- Principais Provedores de API de Inferência para Modelos Open-Source em 2026 — compare Novita AI, Together AI, Fireworks, DeepInfra e Groq



